如何從MongoDB遷移到MySQL?這有現成經驗!
最近的一個多月時間都在做數據庫的遷移工作,我目前在開發的項目在上古時代是使用 MySQL 作為主要數據庫的,后來由于一些業務上的原因從 MySQL 遷移到了 MongoDB,使用了幾個月的時間后,由于數據庫服務非常不穩定,再加上無人看管,同時 MongoDB 本身就是無 Schema 的數據庫,***導致數據庫的臟數據問題非常嚴重。目前團隊的成員沒有較為豐富的 Rails 開發經驗,所以還是希望使用 ActiveRecord 加上 Migration 的方式對數據進行一些強限制,保證數據庫中數據的合法。
本文會介紹作者在遷移數據庫的過程中遇到的一些問題,并為各位讀者提供需要停機遷移數據庫的可行方案,如果需要不停機遷移數據庫還是需要別的方案來解決,在這里提供的方案用于百萬數據量的 MongoDB,預計的停機時間在兩小時左右,如果數據量在***別以上,過長的停機時間可能是無法接受的,應該設計不停機的遷移方案;無論如何,作者希望這篇文章能夠給想要做數據庫遷移的開發者帶來一些思路,少走一些坑。
從關系到文檔
雖然這篇文章的重點是從 MongoDB 遷移到 MySQL,但作者還是想簡單提一下從 MySQL 到 MongoDB 的遷移,如果我們僅僅是將 MySQL 中的全部數據導入到 MongoDB 中其實是一間比較簡單的事情,其中最重要的原因就是 MySQL 支持的數據類型是 MongoDB 的子集:
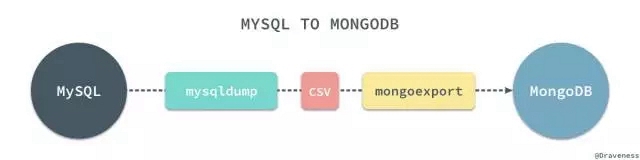
在遷移的過程中可以將 MySQL 中的全部數據以 csv 的格式導出,然后再將所有 csv 格式的數據使用 mongoimport 全部導入到 MongoDB 中:
- $ mysqldump -u<username> -p<password>
- -T <output_directory>
- –fields-terminated-by ‘,’
- –fields-enclosed-by ‘”‘
- –fields-escaped-by ”
- –no-create-info <database_name>
- $ mongoimport –db <database_name> –collection <collection_name>
- –type csv
- –file <data.csv>
- –headerline
整個過程看起來只需要兩個命令,非常簡單,但等到你真要去做時你會遇到非常多的問題,作者沒有過從 MySQL 或者其它關系型數據庫遷移到 MongoDB 的經驗,但是 Google 上相關的資料特別多,所以這總是一個有無數前人踩過坑的問題,而前人的經驗也能夠幫助我們節省很多時間。
使用 csv 的方式導出數據在絕大多數的情況都不會出現問題,但如果數據庫中的某些文檔中存儲的是富文本,那么雖然在導出數據時不會出現問題,最終導入時可能出現一些比較奇怪的錯誤。
從文檔到關系
相比于從 MySQL 到 MongoDB 的遷移,反向的遷移就麻煩了不止一倍,這主要是因為 MongoDB 中的很多數據類型和集合之間的關系在 MySQL 中都并不存在,比如嵌入式的數據結構、數組和哈希等集合類型、多對多關系的實現,很多的問題都不是僅僅能通過數據上的遷移解決的,我們需要在對數據進行遷移之前先對部分數據結構進行重構,本文中的后半部分會介紹需要處理的數據結構和邏輯。

當我們準備將數據庫徹底遷移到 MySQL 之前,需要做一些準備工作,將***遷移所需要的工作盡可能地減少,保證停機的時間不會太長,準備工作的目標就是盡量消滅工程中復雜的數據結構。
數據的預處理
在進行遷移之前要做很多準備工作,***件事情是要把所有嵌入的數據結構改成非嵌入式的數據結構:

也就是把所有 embeds_many 和 embeds_one 的關系都改成 has_many 和 has_one,同時將 embedded_in 都替換成 belongs_to,同時我們需要將工程中對應的測試都改成這種引用的關系,然而只改變代碼中的關系并沒有真正改變 MongoDB 中的數據。
- def embeds_many_to_has_many(parent, child)
- child_key_name = child.to_s.underscore.pluralize
- parent.collection.find({}).each do |parent_document|
- next unless parent_document[child_key_name]
- parent_document[child_key_name].each do |child_document|
- new_child = child_document.merge “#{parent.to_s.underscore}_id”: parent_document[‘_id’]
- child.collection.insert_one new_child
- end
- end
- parent.all.unset(child_key_name.to_sym)
- end
- embeds_many_to_has_many(Person, Address)
我們可以使用上述的代碼將關系為嵌入的模型都轉換成引用,拍平所有復雜的數據關系,這段代碼的運行時間與嵌入關系中的兩個模型的數量有關,需要注意的是,MongoDB 中嵌入模型的數據可能因為某些原因出現相同的 _id 在插入時會發生沖突導致崩潰,你可以對 insert_one 使用 resuce 來保證這段代碼的運行不會因為上述原因而停止。
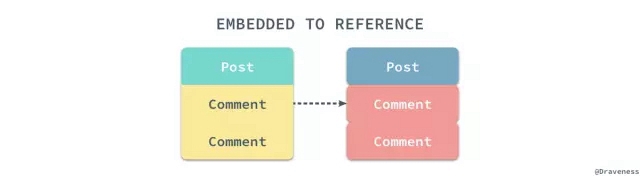
通過這段代碼我們就可以輕松將原有的嵌入關系全部展開變成引用的關系,將嵌入的關系變成引用除了做這兩個改變之外,不需要做其他的事情,無論是數據的查詢還是模型的創建都不需要改變代碼的實現,不過記得為子模型中父模型的外鍵添加索引,否則會導致父模型在獲取自己持有的全部子模型時造成全表掃描:
- class Comment
- include Mongoid::Document
- index post_id: 1
- belongs_to :post
- end
在處理了 MongoDB 中獨有的嵌入式關系之后,我們就需要解決一些復雜的集合類型了,比如數組和哈希,如果我們使用 MySQL5.7 或者 PostgreSQL 的話,其實并不需要對他們進行處理,因為***版本的 MySQL 和 PostgreSQL 已經提供了對 JSON 的支持,不過作者還是將項目中的數組和哈希都變成了常見的數據結構。
在這個可選的過程中,其實并沒有什么標準答案,我們可以根據需要將不同的數據轉換成不同的數據結構:
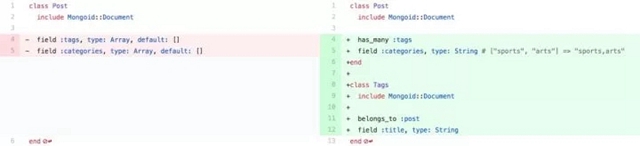
比如,將數組變成字符串或者一對多關系,將哈希變成當前文檔的鍵值對等等,如何處理這些集合數據其實都要看我們的業務邏輯,在改變這些字段的同時盡量為上層提供一個與原來直接 .tags 或者 .categories 結果相同的 API:
- class Post
- …
- def tag_titles
- tags.map(&:title)
- end
- def split_categories
- categories.split(‘,’)
- end
- end
這一步其實也是可選的,上述代碼只是為了減少其它地方的修改負擔,當然如果你想使用 MySQL5.7 或者 PostgreSQL 數據庫對 JSON 的支持也沒有什么太大的問題,只是在查詢集合字段時有一些不方便。
Mongoid 的『小兄弟』們
在使用 Mongoid 進行開發期間難免會用到一些相關插件,比如 mongoid-enum、mongoid-slug 和 mongoid-history 等,這些插件的實現與 ActiveRecord 中具有相同功能的插件在實現上有很大的不同。
對于有些插件,比如 mongoid-slug 只是在引入插件的模型的文檔中插入了 _slugs 字段,我們只需要在進行數據遷移忽略這些添加的字段并將所有的 #slug 方法改成 #id,不需要在預處理的過程中做其它的改變。而枚舉的實現在 Mongoid 的插件和 ActiveRecord 中就截然不同了:
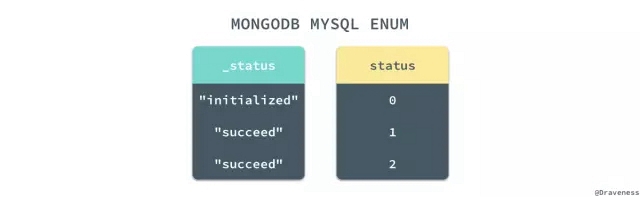
mongoid-enum 使用字符串和 _status 來保存枚舉類型的字段,而 ActiveRecord 使用整數和 status 表示枚舉類型,兩者在底層數據結構的存儲上有一些不同,我們會在之后的遷移腳本中解決這個問題。

如果在項目中使用了很多 Mongoid 的插件,由于其實現不同,我們也只能根據不同的插件的具體實現來決定如何對其進行遷移,如果使用了一些支持特殊功能的插件可能很難在 ActiveRecord 中找到對應的支持,在遷移時可以考慮暫時將部分不重要的功能移除。
主鍵與 UUID
我們希望從 MongoDB 遷移到 MySQL 的另一個重要原因就是 MongoDB 每一個文檔的主鍵實在是太過冗長,一個 32 字節的 _id 無法給我們提供特別多的信息,只能增加我們的閱讀障礙,再加上項目中并沒有部署 MongoDB 集群,所以沒能享受到用默認的 UUID 生成機制帶來的好處。

我們不僅沒有享受到 UUID 帶來的有點,它還在遷移 MySQL 的過程中帶來了很大的麻煩,一方面是因為 ActiveRecord 的默認主鍵是整數,不支持 32 字節長度的 UUID,如果想要不改變 MongoDB 的 UUID,直接遷移到 MySQL 中使用其實也沒有什么問題,只是我們要將默認的整數類型的主鍵變成字符串類型,同時要使用一個 UUID 生成器來保證所有的主鍵都是根據時間遞增的并且不會沖突。
如果準備使用 UUID 加生成器的方式,其實會省去很多遷移的時間,不過看起來確實不是特別的優雅,如何選擇還是要權衡和評估,但是如果我們選擇了使用 integer 類型的自增主鍵時,就需要做很多額外的工作了,首先是為所有的表添加 uuid 字段,同時為所有的外鍵例如 post_id 創建對應的 post_uuid 字段,通過 uuid 將兩者關聯起來:
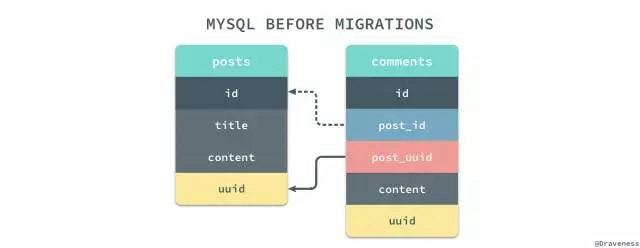
在數據的遷移過程中,我們會將原有的 _id 映射到 uuid 中,post_id 映射到 post_uuid 上,我們通過保持 uuid和 post_uuid 之間的關系保證模型之間的關系沒有丟失,在遷移數據的過程中 id 和 post_id 是完全不存在任何聯系的。
當我們按照 _id 的順序遍歷整個文檔,將文檔中的數據被插入到表中時,MySQL 會為所有的數據行自動生成的遞增的主鍵 id,而 post_id 在這時都為空。
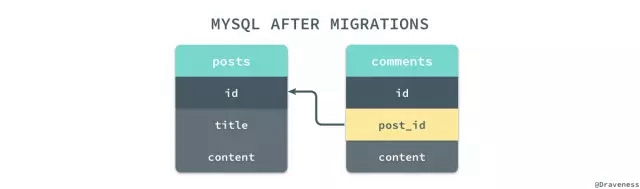
在全部的數據都被插入到 MySQL 之后,我們通過 #find_by_uuid 查詢的方式將 uuid 和 post_uuid 中的關系遷移到 id 和 post_id 中,并將與 uuid 相關的字段全部刪除,這樣我們能夠保證模型之間的關系不會消失,并且數據行的相對位置與遷移前完全一致。
代碼的遷移
Mongoid 在使用時都是通過 include 將相關方法加載到當前模型中的,而 ActiveRecord 是通過繼承 ActiveRecord::Base 的方式使用的,完成了對數據的預處理,我們就可以對現有模型層的代碼進行修改了。
首先當然是更改模型的『父類』,把所有的 Mongoid::Document 都改成 ActiveRecord::Base,然后創建類對應的 Migration 遷移文件:
- # app/models/post.rb
- class Post < ActiveRecord::Base
- validate_presence_of :title, :content
- end
- # db/migrate/20170908075625_create_posts.rb
- class CreatePosts < ActiveRecord::Migration[5.1]
- def change
- create_table :posts do |t|
- t.string :title, null: false
- t.text :content, null: false
- t.string :uuid, null: false
- t.timestamps null: false
- end
- add_index :posts, :uuid, unique: true
- end
- end
注意:要為每一張表添加類型為字符串的 uuid 字段,同時為 uuid 建立唯一索引,以加快通過 uuid 建立不同數據模型之間關系的速度。
除了建立數據庫的遷移文件并修改基類,我們還需要修改一些 include 的模塊和 Mongoid 中獨有的查詢,比如使用 gte 或者 lte 的日期查詢和使用正則進行模式匹配的查詢,這些查詢在 ActiveRecord 中的使用方式與 Mongoid 中完全不同,我們需要通過手寫 SQL 來解決這些問題。

除此之外,我們也需要處理一些復雜的模型關系,比如 Mongoid 中的 inverse_of 在 ActiveRecord 中叫做foreign_key 等等,這些修改其實都并不復雜,只是如果想要將這部分的代碼全部處理掉,就需要對業務邏輯進行詳細地測試以保證不會有遺留的問題,這也就對我們項目的測試覆蓋率有著比較高的要求了,不過我相信絕大多數的 Rails 工程都有著非常好的測試覆蓋率,能夠保證這一部分代碼和邏輯能夠順利遷移,但是如果項目中完全沒有測試或者測試覆蓋率很低,就只能人肉進行測試或者自求多福了,或者就別做遷移了,多寫點測試再考慮這些重構的事情吧。
數據的遷移
為每一個模型創建對應的遷移文件并建表其實一個不得不做的體力活,雖然有一些工作我們沒法省略,但是我們可以考慮使用自動化的方式為所有的模型添加 uuid 字段和索引,同時也為類似 post_id 的字段添加相應的 post_uuid 列:
- class AddUuidColumns < ActiveRecord::Migration[5.1]
- def change
- Rails.application.eager_load!
- ActiveRecord::Base.descendants.map do |klass|
- # add `uuid` column and create unique index on `uuid`.
- add_column klass.table_name, :uuid, :string, unique: true
- add_index klass.table_name, unique: true
- # add `xxx_uuid` columns, ex: `post_uuid`, `comment_uuid` and etc.
- uuids = klass.attribute_names
- .select { |attr| attr.include? ‘_id’ }
- .map { |attr| attr.gsub ‘_id’, ‘_uuid’ }
- next unless uuids.present?
- uuids.each do |uuid|
- add_column klass.table_name, uuid, :string
- end
- end
- end
- end
在添加 uuid 列并建立好索引之后,我們就可以開始對數據庫進行遷移了,如果我們決定在遷移的過程中改變原有數據的主鍵,那么我們會將遷移分成兩個步驟,數據的遷移和關系的重建,前者僅指將 MongoDB 中的所有數據全部遷移到 MySQL 中對應的表中,并將所有的 _id 轉換成 uuid、xx_id 轉換成 xx_uuid,而后者就是前面提到的:通過 uuid 和 xx_uuid 的關聯重新建立模型之間的關系并在***刪除所有的 uuid 字段。
我們可以使用如下的代碼對數據進行遷移,這段代碼從 MongoDB 中遍歷某個集合 Collection 中的全部數據,然后將文檔作為參數傳入 block,然后再分別通過 DatabaseTransformer#delete_obsolete_columns 和 DatabaseTransformer#update_rename_columns 方法刪除部分已有的列、更新一些數據列***將所有的 id 列都變成 uuid:
- module DatabaseTransformer
- def import(collection_name, *obsolete_columns, **rename_columns)
- collection = Mongoid::Clients.default.collections.select do |c|
- c.namespace == “#{database}.#{collection_name.to_s.pluralize}”
- end.first
- unless collection.present?
- STDOUT.puts “#{collection_name.to_s.yellow}: skipped”
- STDOUT.puts
- return
- end
- constant = collection_name.to_s.singularize.camelcase.constantize
- reset_callbacks constant
- DatabaseTransformer.profiling do
- collection_count = collection.find.count
- collection.find.each_with_index do |document, index|
- document = yield document if block_given?
- delete_obsolete_columns document, obsolete_columns
- update_rename_columns document, rename_columns
- update_id_columns document
- insert_record constant, document
- STDOUT.puts “#{index}/#{collection_count} ” if (index % 1000).zero?
- end
- end
- end
- end
當完成了對文檔的各種操作之后,該方法會直接調用 DatabaseTransformer#insert_record 將數據插入 MySQL 對應的表中;我們可以直接使用如下的代碼將某個 Collection 中的全部文檔遷移到 MySQL 中:
- transformer = DatabaseTransformer.new ‘draven_production’
- transformer.import :post, :_slugs, name: :title, _status: :status
上述代碼會在遷移時將集合每一個文檔的 _slugs 字段全部忽略,同時將 name 重命名成 title、_status 重命名成 status,雖然作為枚舉類型的字段 mongoid-enum 和 ActiveRecord 的枚舉類型完全不同,但是在這里可以直接插入也沒有什么問題,ActiveRecord 的模型在創建時會自己處理字符串和整數之間的轉換:
- def insert_record(constant, params)
- model = constant.new params
- model.save! validate: false
- rescue Exception => exception
- STDERR.puts “Import Error: #{exception}”
- raise exception
- end
為了加快數據的插入速度,同時避免所有由于插入操作帶來的副作用,我們會在數據遷移期間重置所有的回調:
- def reset_callbacks(constant)
- %i(create save update).each do |callback|
- constant.reset_callbacks callback
- end
- end
這段代碼的作用僅在這個腳本運行的過程中才會生效,不會對工程中的其他地方造成任何的影響;同時,該腳本會在每 1000 個模型插入成功后向標準輸出打印當前進度,幫助我們快速發現問題和預估遷移的時間。
你可以在 database_transformer.rb 找到完整的數據遷移代碼。
將所有的數據全部插入到 MySQL 的表之后,模型之間還沒有任何顯式的關系,我們還需要將通過 uuid 連接的模型轉換成使用 id 的方式,對象之間的關系才能通過點語法直接訪問,關系的建立其實非常簡單,我們獲得當前類所有結尾為 _uuid 的屬性,然后遍歷所有的數據行,根據 uuid 的值和 post_uuid 屬性中的 “post” 部分獲取到表名,最終得到對應的關聯模型,在這里我們也處理了類似多態的特殊情況:
- module RelationBuilder
- def build_relations(class_name, polymorphic_associations = [], rename_associations = {})
- uuids = class_name.attribute_names.select { |name| name.end_with? ‘_uuid’ }
- unless uuids.present?
- STDOUT.puts “#{class_name.to_s.yellow}: skipped”
- STDOUT.puts
- return
- end
- reset_callbacks class_name
- RelationBuilder.profiling do
- models_count = class_name.count
- class_name.unscoped.all.each_with_index do |model, index|
- update_params = uuids.map do |uuid|
- original_association_name = uuid[0…-5]
- association_model = association_model(
- original_association_name,
- model[uuid],
- polymorphic_associations,
- rename_associations
- )
- [original_association_name.to_s, association_model]
- end.compact
- begin
- Hash[update_params].each do |key, value|
- model.send “#{key}=”, value
- end
- model.save! validate: false
- rescue Exception => e
- STDERR.puts e
- raise e
- end
- STDOUT.puts “#{index}/#{models_count} ” if (counter % 1000).zero?
- end
- end
- end
- end
在查找到對應的數據行之后就非常簡單了,我們調用對應的 post= 等方法更新外鍵***直接將外鍵的值保存到數據庫中,與數據的遷移過程一樣,我們在這段代碼的執行過程中也會打印出當前的進度。
在初始化 RelationBuilder 時,如果我們傳入了 constants,那么在調用 RelationBuilder#build! 時就會重建其中的全部關系,但是如果沒有傳入就會默認加載 ActiveRecord 中所有的子類,并去掉其中包含 :: 的模型,也就是 ActiveRecord 中使用 has_and_belongs_to_many 創建的中間類,我們會在下一節中介紹如何單獨處理多對多關系:
- def initialize(constants = [])
- if constants.present?
- @constants = constants
- else
- Rails.application.eager_load!
- @constants = ActiveRecord::Base.descendants
- .reject { |constant| constant.to_s.include?(‘::’) }
- end
- end
跟關系重建相關的代碼可以在 relation_builder.rb 找到完整的用于關系遷移的代碼。
- builder = RelationBuilder.new([Post, Comment])
- builder.build!
通過這數據遷移和關系重建兩個步驟就已經可以解決絕大部分的數據遷移問題了,但是由于 MongoDB 和 ActiveRecord 中對于多對多關系的處理比較特殊,所以我們需要單獨進行解決,如果所有的遷移問題到這里都已經解決了,那么我們就可以使用下面的遷移文件將數據庫中與 uuid 有關的全部列都刪除了:
- class RemoveAllUuidColumns < ActiveRecord::Migration[5.1]
- def change
- Rails.application.eager_load!
- ActiveRecord::Base.descendants.map do |klass|
- attrs = klass.attribute_names.select { |n| n.include? ‘uuid’ }
- next unless attrs.present?
- remove_columns klass.table_name, *attrs
- end
- end
- end
到這里位置整個遷移的過程就基本完成了,接下來就是跟整個遷移過程中有關的其它事項,例如:對多對關系、測試的重要性等話題。
多對多關系的處理
多對多關系在數據的遷移過程中其實稍微有一些復雜,在 Mongoid 中使用 has_and_belongs_to_many 會在相關的文檔下添加一個 tag_ids 或者 post_ids 數組:
- # The post document.
- {
- “_id” : ObjectId(“4d3ed089fb60ab534684b7e9”),
- “tag_ids” : [
- ObjectId(“4d3ed089fb60ab534684b7f2”),
- ObjectId(“4d3ed089fb60ab53468831f1”)
- ],
- “title”: “xxx”,
- “content”: “xxx”
- }
而 ActiveRecord 中會建立一張單獨的表,表的名稱是兩張表名按照字母表順序的拼接,如果是 Post 和 Tag,對應的多對多表就是 posts_tags,除了創建多對多表,has_and_belongs_to_many 還會創建兩個 ActiveRecord::Base的子類 Tag::HABTM_Posts 和 Post::HABTM_Tags,我們可以使用下面的代碼簡單實驗一下:
- require ‘active_record’
- class Tag < ActiveRecord::Base; end
- class Post < ActiveRecord::Base
- has_and_belongs_to_many :tags
- end
- class Tag < ActiveRecord::Base
- has_and_belongs_to_many :posts
- end
- puts ActiveRecord::Base.descendants
上述代碼打印出了兩個 has_and_belongs_to_many 生成的類 Tag::HABTM_Posts 和 Post::HABTM_Tags,它們有著完全相同的表 posts_tags,處理多對多關系時,我們只需要在使用 DatabaseTransformer 導入表中的所有的數據之后,再通過遍歷 posts_tags 表中的數據更新多對多的關系表就可以了:
- class PostsTag < ActiveRecord::Base; end
- # migrate data from mongodb to mysql.
- transformer = DatabaseTransformer.new ‘draven_production’
- transformer.import :posts_tags
- # establish association between posts and tags.
- PostsTag.unscoped.all.each do |model|
- post = Post.find_by_uuid model.post_uuid
- tag = Tag.find_by_uuid model.tag_uuid
- next unless post.present? && tag.present?
- model.update_columns post_id: post.id, tag_id: tag.id
- end
所有使用 has_and_belongs_to_many 的多對多關系都需要通過上述代碼進行遷移,這一步需要在刪除數據庫中的所有 uuid 字段之前完成。
測試的重要性
在真正對線上的服務進行停機遷移之前,我們其實需要對數據庫已有的數據進行部分和全量測試,在部分測試階段,我們可以在本地準備一個數據量為生產環境數據量 1/10 或者 1/100 的 MongoDB 數據庫,通過在本地模擬 MongoDB 和 MySQL 的環境進行預遷移,確保我們能夠盡快地發現遷移腳本中的錯誤。

準備測試數據庫的辦法是通過關系刪除一些主要模型的數據行,在刪除時可以通過 MongoDB 中的 dependent: :destroy 刪除相關的模型,這樣可以盡可能的保證數據的一致性和完整性,但是在對線上數據庫進行遷移之前,我們依然需要對 MongoDB 中的全部數據進行全量的遷移測試,這樣可以發現一些更加隱蔽的問題,保證真正上線時可以出現更少的狀況。
數據庫的遷移其實也屬于重構,在進行 MongoDB 的數據庫遷移之前一定要保證項目有著完善的測試體系和測試用例,這樣才能讓我們在項目重構之后,確定不會出現我們難以預料的問題,整個項目才是可控的,如果工程中沒有足夠的測試甚至沒有測試,那么就不要再說重構這件事情了 – 單元測試是重構的基礎。
總結
如何從 MongoDB 遷移到 MySQL 其實是一個工程問題,我們需要在整個過程中不斷尋找可能出錯的問題,將一個比較復雜的任務進行拆分,在真正做遷移之前盡可能地減少遷移對服務可用性以及穩定性帶來的影響。

除此之外,MongoDB 和 MySQL 之間的選擇也不一定是非此即彼,我們將項目中的大部分數據都遷移到了 MySQL 中,但是將一部分用于計算和分析的數據留在了 MongoDB,這樣就可以保證 MongoDB 宕機之后仍然不會影響項目的主要任務,同時,MySQL 的備份和恢復速度也會因為數據庫變小而非常迅速。
***一點,測試真的很重要,如果沒有測試,沒有人能夠做到在修改大量的業務代碼的過程中不丟失任何的業務邏輯,甚至如果沒有測試,很多業務邏輯可能在開發的那一天就已經丟失了。