最全面的百度NLP自然語言處理技術解析
在AI時代,我們希望計算機能夠擁有視覺、聽覺、行動以及語言的智能,而相對于聽和看以及行動,語言是我們人類區別于其他動物的最重要特征之一。語言是我們思維的載體,也因此我們對于語言的理解和處理,變得尤為重要。而在計算機領域,自然語言處理(NLP, Natural Language Processing)就是研究如何讓計算機理解并生成人類的語言,從而和人類平等流暢地溝通交流。自然語言處理技術 在百度已經有悠久的歷史,早在百度誕生之時就成為搜索技術的重要組成部分,一直伴隨著百度的發展而進步。從中文分詞、詞性分析、改寫,到機器翻譯、篇章分析、語義理解、對話系統等等,NLP技術已成功應用在百度各類產品中。
近期由百度開發者中心主辦、極客邦科技承辦的75期百度技術沙龍上,百度NLP和AI開放平臺的多位資深工程師和產品經理,針對開發者如何利用百度NLP技術更好解決實際應用問題,進行了具體分享。百度AI技術生態部高級運營顧問張揚,通過具體應用案例,讓大家對百度NLP開放的核心技術有一個感性的認知;自然語言處理部主任架構師孫宇,針對NLP語義計算技術的具體問題深入分析;自然語言處理部資深研發工程師何伯磊,用大量場景詳細解釋了情感分析領域的技術應用;自然語言處理部資深研發工程師姜迪,詳細闡述了概率圖模型技術如何應用;百度AI技術生態部資深產品經理張晶晶,為大家現場指導百度AI開放平臺的使用方法。
NLP是什么?
NLP是計算機科學領域與人工智能領域中的一個重要方向。它研究能實現人與計算機之間用自然語言進行有效通信的各種理論和方法。自然語言處理是一門融語言學、計算機科學、數學于一體的學科。NLP由兩個主要的技術領域構成:自然語言理解和自然語言生成。
- 自然語言理解方向,主要目標是幫助機器更好理解人的語言,包括基礎的詞法、句法等語義理解,以及需求、篇章、情感層面的高層理解。
- 自然語言生成方向,主要目標是幫助機器生成人能夠理解的語言,比如文本生成、自動文摘等。
NLP技術基于大數據、知識圖譜、機器學習、語言學等技術和資源,并可以形成機器翻譯、深度問答、對話系統的具體應用系統,進而服務于各類實際業務和產品。
我們為什么需要NLP?
在演講中,為了讓大家有更直觀的感受,張揚首先舉了個生活中的例子:人們在用百度搜索一個生僻字時,不知道拼音的情況下會搜索:“4個又念什么?”,我們發現,搜索結果一定是告訴你這個“叕”字念什么,而不是“4個又念什么”的這幾個詞表面的匹配結果,這其中已經用到自然語言理解的能力了,它幫助搜索引擎理解用戶需要搜的是“由4個又組成的字”,而不是“4個又是什么”這幾個孤零零的詞。由此可見,NLP技術真正能夠知道你所說的話的深層語義是什么,這項技術也把人工智能推向了一個新的高度。
那么NLP究竟能能夠干什么?如何幫助業務實現,張揚繼續介紹了百度NLP開放的幾項典型技術:
情感傾向分析
針對帶有主觀描述的中文文本,可自動判斷該文本的情感極性類別并給出相應的置信度。情感極性分為積極、消極、中性。情感傾向分析能幫助企業理解用戶消費習慣、分析熱點話題和危機輿情監控,為企業提供有力的決策支持。

評論觀點抽取
自動分析評論關注點和評論觀點,并輸出評論觀點標簽及評論觀點極性。目前支持13類產品用戶評論的觀點抽取,包括美食、酒店、汽車、景點等,可幫助商家進行產品分析,輔助用戶進行消費決策。

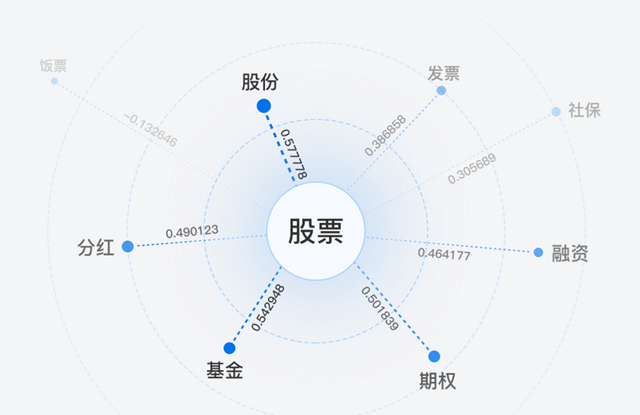
詞義相似度計算
用于計算兩個給定詞語的語義相似度,基于自然語言中的分布假設,即越是經常共同出現的詞之間的相似度越高。詞義相似度是自然語言處理中的重要基礎技術,是專名挖掘、query改寫、詞性標注等常用技術的基礎之一。
詞法分析
百度詞法分析向用戶提供分詞、詞性標注、命名實體識別三大功能。該服務能夠識別出文本串中的基本詞匯標注和詞匯的詞性,并進一步識別出命名實體,百度詞法分析的算法效果大幅領先已公開的主流中文詞法分析模型。

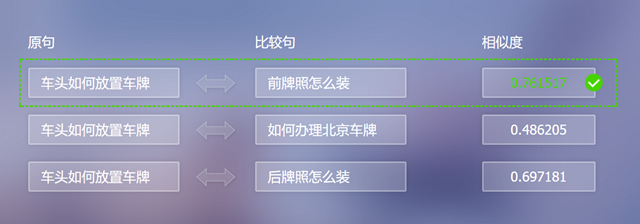
短文本相似度
能夠提供不同短文本之間相似度的計算,輸出的相似度是一個介于-1到1之間的實數值,越接近1則相似度越高。這個相似度值可以直接用于結果排序,也可以作為一維基礎特征作用于更復雜的系統。
DNN語言模型
語言模型是通過計算給定詞組成的句子的概率,從而判斷所組成的句子是否符合客觀語言表達習慣。在機器翻譯、拼寫糾錯、語音識別、問答系統、詞性標注、句法分析和信息檢索等系統中都有廣泛應用。

詞向量表示
詞向量表示表示是通過訓練的方法,將語言詞表中的詞映射成一個長度固定的向量。詞表中所有的詞向量構成一個向量空間,每一個詞都是這個詞向量空間中的一個點,利用這種方法,實現文本的可計算。
依存句法分析
利用句子中詞與詞之間的依存關系來表示詞語的句法結構信息(如主謂、動賓、定中等結構關系)
并用樹狀結構來表示整句的的結構(如主謂賓、定狀補等)。
百度語義計算技術是如何實現的?
在各個NLP開放接口之中,語義計算是一個非常基礎的技術。百度NLP部門的主任架構師孫宇主要圍繞NLP語義計算整體技術框架展開分析,核心介紹了語義表示技術和語義匹配技術。百度NLP語義計算整體框架主要分三大部分(如下圖),***層依托于大數據、網頁數據和用戶行為數據,以及高性能集群(GPU、CPU和FPGA),打造了基于DNN和概率圖模型的語義計算引擎,通過文本輸入到語義計算引擎當中,可以得到文本的語義表示,進而基于這個語義表示,進行語義層面的計算,包括語義匹配、語義檢索、文本分類、序列生成以及序列標注。

目前,百度在語義方面開放了四個技術,囊括了詞匯和句子兩個層面的語義技術。詞匯層面包括了詞語義向量表示,詞義相似度計算;句子層面的包括短文本語義相似度計算和DNN語言模型。孫宇對這些技術背后的原理進行了詳細的介紹。
語義表示技術業界很早就開始研究,主要有兩種流派,一個是形式化的方法,一個是基于統計的方法。關于基于形式化的方法,在上世紀八十年代普林斯頓有科學家提出:基于語言學知識構建一個詞圖,把知識通過詞與詞之間的關系構建到這個圖里。九十年代又有人提出,將自然語言表示成一種邏輯的表達式,可以直接用于計算機計算和執行。但這兩個技術都存在一個問題:自動化程度不高,適用性較差,因此,百度NLP主要采用基于統計的方法。
短文本語義相似度計算是他們重點打造、應用廣泛的技術。其中的核心模型是利用他們2013年開始研發的SimNet語義匹配框架,在千億級別真實點擊數據訓練得到。該框架的基礎匹配算法上包含兩種匹配范式,一種側重于表示層建模,另外一種則更側重于匹配層建模。這兩種模型各有優勢,可解決不同問題。另外,針對不同應用場景他們還擴展研發了基于字符級別匹配和多視角匹配技術,這些技術都廣泛應用于百度內部各產品中。
百度自然語言處理在情感分析領域有哪些技術和應用?
在演講中,何伯磊主要針對用戶日常的使用場景,分析了情感分析技術的原理和實際應用。百度情感分析技術依托于評論大數據、深度學習、語義理解等基礎技術,建立了一套完整情感分類與觀點挖掘的核心技術。在情感分類方面,我們研發了情感傾向性分析、情感的情緒分析,情感對象識別以及句子的主客觀的分析。在觀點挖掘方面,我們通過情感搭配知識自動構建和觀點計算技術,我們能有效的進行文本數據的觀點抽取。百度依托這些核心的技術,進行用戶產品開發。
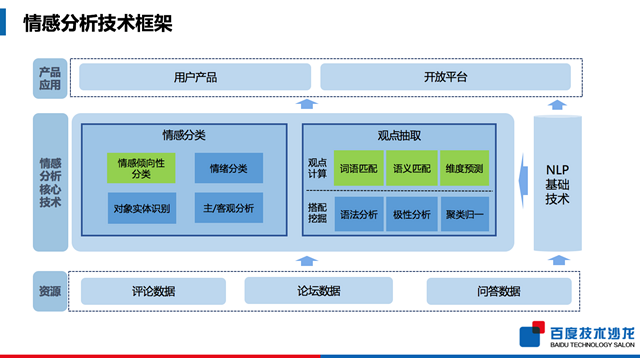
這里重點介紹兩類核心技術:
情感傾向性分析
情感傾向分析任務目標是能夠判斷用戶文本是積極、消極或是中性的情感。傳統方法有兩類:一類利用情感詞典進行規則匹配的方法進行判斷,另外一類基于情感詞典和文本特征建立一個2分類任務的方法 。百度情感傾向性分析基于深度學習的方法,分別建立了句子級、實體級、篇章級多粒度完整的分析任務。句子級粒度上,通過基于Bi-LSTM分類方法,系統更好的捕捉了情感極性在前后文表達的信息,效果上相對于傳統的方法有了很大的提升。實體級粒度的任務概念稍有晦澀,舉個例子:《成龍對戰狼2的看法》一篇文章可能有多個主題,這個任務就是希望能夠把這篇文章對于“吳京”的態度分析出來。在這個任務中,我們通過建立層次化的語義表達方法,讓整個系統更加精準的進行分析和判斷。
評論觀點抽取的技術
評論觀點抽取目標:給定一個文本,把其中表達觀點的信息抽取出來。舉個例子,用戶的評論:“這家旅店的服務還不錯,但是房間比較簡陋”,我們目標把“服務不錯、房間簡陋”這樣的關鍵觀點信息抽取出來。評論觀點抽取技術在當前互聯網產品中應用十分廣泛,但是召回率一直不高,百度的評論觀點抽取技術將任務從應用需求進行細致分析拆解,通過基于情感搭配的方法,基于語義計算的方法,基于維度預測的方法,以及基于維度預測加情感極性分類的方法***的解決了應用中各種的問題,這也是一個技術和應用完結合經典案例。
概率圖模型技術如何應用?
姜迪分享的主題是《Familia可配置的主題模型框架》,Familia是家族、家庭的意思。顧名思義,這個框架的特點就是涵蓋了一族具有較大的工業價值的主題模型,這樣一來,一線的工程師就有很多靈活性,可以根據具體任務,來選擇適用的模型。
百度有一個貝葉斯技術體系的框架,主要分三大類:***類是主題模型,這個框架的特點就是它有一個自配置的功能;第二類是點擊模型,主要是應用在搜索引擎的領域,來量化分析用戶的搜索行為以及搜索查詢和網頁的相關性;第三類是分類模型,包含最常見的基于貝葉斯網的分類器。

主題模型框架中有十幾個主流的主題模型,其中包含LDA模型、引入了句子結構的SentenceLDA模型、引入了監督信號的SupervisedLDA,以及其他具有工業價值的主題模型,并且支持用戶根據具體任務設計對應的模型。
那么,為什么要設計Familia這個主題框架?業界大部分主題模型工具只支持PLSA和LDA兩種模型,這兩種模型非常類似,它們只支持一種數據假設,也就是說,我們只能用一種模型來適用不同的場景,不能支持用戶的根據具體任務自定義擴展。當用戶的數據本身和這兩個模型的假設有較大差異時,效果可想而知。另一方面,當前的主題模型工具對下游的應用并不太友好,這些工作往往只注重模型的訓練,忽略了模型如何在具體任務中應用。從模型的訓練到應用之間有很長的距離,如何消除這個距離是我們這個工作的重點。Familia在百度的應用場景其實非常多,包含了大家耳熟能詳的百度搜索、百度新聞、糯米、貼吧這些平臺,也部署到了百度自然語言的云處理平臺上,這個工具目前每天有3000萬次的響應需求。
Familia框架是怎么在工業界場景進行應用的?***步,數據預處理,這里可以支持多種類型的數據,包括常見的網頁數據、新聞數據和糯米數據,在內部將數據預處理步驟和百度的分詞進行了一個深度的融合。在分詞的前和后我們還有多種多樣的過濾器,用戶可以根據自己的需求,來選擇什么信息要過濾掉,什么信息可以保留。第二步,概率圖模型配置,Familia支持多種主流的已有的主題模型,同時用戶也可以自定義自己的主題模型。這個過程是通過一種數據組織抽象存儲多種圖模型的信息來實現的。第三步,采樣公式自動推導,Familia中的參數推導引擎可以自動推導出采樣公式,降低了主題模型應用的數學門檻。第四步,模型的后期處理,Familia進一步對訓練好的主題模型進行優化和壓縮操作。第五步,Familia抽象了語義表示和語義匹配兩個應用范式,用戶可以根據具體任務來使用對應的范式。
目前Familia已經在github上完成開源(https://github.com/baidu/familia),***期提供網頁、新聞、小說等多個垂類語料訓練的工業級主題模型,并提供語義表示、語義匹配兩類應用范式的大量應用場景指導。
對開發者而言,如何更好的使用百度AI開放平臺?
張晶晶主要就自然語言使用的相關問題及整個百度AI開放平臺的使用方法進行了介紹。目前百度自然語言處理技術開放8項語言處理的基礎技術,基于這些基礎的能力,百度對外開放了很多感知層和認知層的技術,在上面搭建了我們一個開放平臺,在這個平臺上百度把我們所有成熟的AI技術都在這里統一對外開放,使大家能夠通過接口的方式,直接調用、直接使用,比如語音識別、語音合成、文字識別的各種模板、端口,人臉識別等。另外,百度也將開放個性化和定制服務,主要是有詞法分析、評論觀點抽取和情感傾向分析。詞法分析的定制,可以幫助我們的行業客戶實現個性化需求,若有識別不了的詞匯,可以通過上傳詞表的方式,來把模型訓練的更適合自己。

百度AI平臺為開發過程提供了三方面的支持,首先是開發組建,其次是管理功能和配套資源。開發組建方面,每個技術領域里都以標準的方式提供了API和SDK,有些方向上還提供了參考代碼。有一些需要獨立去配置的模塊單獨做了配置系統,讓開發者可以先在平臺上做好配置之后就可以直接調用。在后臺管理上,有基礎的應用管理,也支持很多跟企業業務相關的個性化的配置,隨時查看調用的統計信息。開發者還可以在產品上使用百度LOGO,標識出百度AI技術。開發者如果應用百度的AI技術解決了行業中的典型問題,百度也會擔任伯樂的角色,將其案例進行宣傳推廣。