自然語言處理庫—Snownlp
本文轉載自微信公眾號「志斌的python筆記」,作者志斌。轉載本文請聯系志斌的python筆記公眾號。
大家好,我是志斌~
上次在跟大家分享用Python在本地進行文本情感分析的時候,給大家介紹了一個Snownlp庫,當時只跟大家介紹了一下它的情感分析功能,這次來跟大家詳細的介紹一下它其它的強大的功能。
01定義和安裝
我們先來看看官方對它的介紹:
SnowNLP是一個python寫的類庫,可以方便的處理中文文本內容,是受到了TextBlob的啟發而寫的,由于現在大部分的自然語言處理庫基本都是針對英文的,于是寫了一個方便處理中文的類庫,并且和TextBlob不同的是,這里沒有用NLTK,所有的算法都是自己實現的,并且自帶了一些訓練好的字典。注意本程序都是處理的unicode編碼,所以使用時請自行decode成unicode。
它的安裝命令如下:
- pip install snownlp
02功能介紹
它主要有九個功能,我們分別來給大家介紹一下這九個功能都是干什么的。
01分詞功能
SnowNLP的分詞功能,可以將文本內容對照著字典劃分一個個詞語字符串,如果不是詞語的就單獨成為一個字符串。代碼如下:
- a = SnowNLP('我非常的熱愛學習!')
- print(a.words)

02詞性標注
SnowNLP的詞性標注功能,可以對各個詞語進行標注,讓我們能夠知道這個詞語屬于名詞還是動詞,或者其它詞性。代碼如下:
- a = SnowNLP('我非常的熱愛學習!')
- for i in a.tags:
- print(i)

03情感分析
在之前的文章我們已經詳細的介紹過了SnowNLP的情感分析功能,這里就不在過多介紹,用興趣的小伙伴,可以看看這篇文章兩種文本情感分析方式,你更pick哪一種?。
04拼音標注
SnowNLP的拼音標準功能,可以給文本中所有文字進行拼音標注,這樣以后再也不擔心遇到生僻字不會讀啦~~ 代碼如下:
- a = SnowNLP('我非常的熱愛學習!')
- print(a.pinyin)

05提取關鍵字和摘要
SnowNLP可以將文本中出現的關鍵字和文本摘要給提取出來,從而讓我們可以更快速的了解文本講述的內容。代碼如下:
- text = '''計算機網絡系統就是利用通信設備和線路將地理位置不同、功能獨立的多個計算機系統互聯起來,以功能完善的網絡軟件實現網絡中資源共享和信息傳遞的系統。
- 通過計算機的互聯,實現計算機之間的通信,從而實現計算機系統之間的信息、軟件和設備資源的共享以及協同工作等功能,
- 其本質特征在于提供計算機之間的各類資源的高度共享,實現便捷地交流信息和交換思想。'''
- b=SnowNLP(text)
- key_word = b.keywords(5) #()中的數字,代表提取關鍵字數量
- abs_word = b.summary(1) #()中的數字,代表提取摘要數量
- print(key_word)
- print(abs_word)

06計算詞頻和逆文檔頻率
關鍵字的先后順序是由TF-IDF值的大小來決定的,其中TF就是詞頻、IDF就是逆文檔頻率、詞頻很好理解就是一個詞在文本中出現的頻率,逆文檔頻率是在詞頻的基礎上,給每個詞分配一個“重要性”的權重,越常見的詞分配的權重越低,越稀少的詞,權重越高,這個權重就成為逆文檔頻率,它的大小和詞語的常見性成反比。代碼如下:
- c = SnowNLP([['計算機'], ['資源'], ['系統'], ['信息'], ['功能']])
- print(c.tf)
- print(c.idf)

07繁體轉簡體
個人感覺這個技能較為冷門,現在基本上都是簡體字了。(僅為個人意見,不喜勿噴。)代碼如下:
- d = SnowNLP('山不在高,有仙則靈.水不在深,有龍則靈')
- print(d.han)

08斷句功能
SnowNLP可以按照","和“。”對文本進行斷句處理。代碼如下:
- b=SnowNLP(text)
- print(b.sentences)

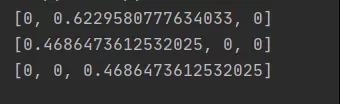
09文本相似度
- e = SnowNLP([['計算機','資源'],
- ['系統'],
- ['信息','功能']
- ])
- print(e.sim(['系統']))
- print(e.sim(['計算機']))
- print(e.sim(['功能']))