













IT運維如何防止陷入“中年油膩”和頻繁被動地打“遭遇戰(zhàn)”?
原創(chuàng)【51CTO.com原創(chuàng)稿件】近期,我拜訪了一家文化傳播公司的 IT 運維總監(jiān) Tim,他向我講述了他的團隊是如何像當年玩《大航海時代》那樣將 IT 系統(tǒng)的戰(zhàn)艦越造越大,并使之在企業(yè)運營的海洋中平穩(wěn)前行的。
在此,我將他的心路歷程分享出來,希望能夠幫助您改變那種像小倉鼠一樣一直在環(huán)形輪上盲目地“跑酷”狀態(tài)。
縱然練就“72變”,也無法笑對“81難”
該文化公司成立于 2013 年,他們最初從簡單的“PC 服務器 + 二手三層交換 + 托管服務器”這樣的硬件架構起步,既要對內滿足員工的“上網 + 郵件 + 文件共享 + 存儲”,又要對外提供“官網 + 視頻上傳/下載”的服務。
在 IT 系統(tǒng)建成初期,由于處于運維“四少”,即設備少、應用少,流程少,問題少的狀態(tài),他和另一名同事組成的“哼哈二將”模式完全可以 hold 住各種與 Ops 相關的需求和問題。
但是隨著公司這幾年來的多元化發(fā)展,各種看得見的設備和看不見的軟件越來越多,特別是“論壇 + 會員博客 + 微官網 + 在線訂單 + 移動支付 + 遠程訪問”等業(yè)務所帶動的系統(tǒng)復雜性,縱然他們不斷練就七十二變,也無法笑對前方的八十一難。
在擴大運維團隊的同時,他們通過整合資源、逐步轉變并提升了 Ops 的相關觀念和操作模式,摸索出了一條具有本企業(yè)特色的 Ops+ 模式。
總的說來就是:針對整個運維生命周期中的各個方面,用三步遞進的模式來逐步改進日常各項工作,即“標準化—配置與流程、自動化—操作與安全、平臺化—監(jiān)控與管理”。
Ops+ 運維模式初探
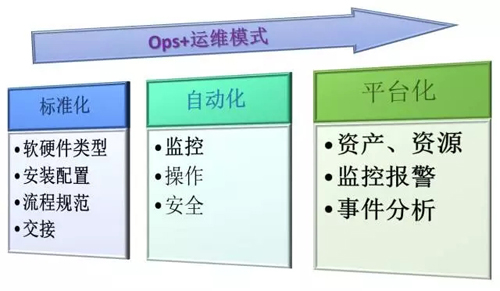
標準化—配置與流程
過去他們的運維人員過分依賴技術上的大牛,由于上手門檻較高,部門里往往充斥著個人英雄主義,當然也就造成了人員資源上的單點風險。與此同時,他們又時常被服務廠商所“綁架”。
由于各家實現(xiàn)方式的不盡相同,在系統(tǒng)出現(xiàn)問題的時候,要么相互推諉,要么一擁而上、各自為政。這些都給系統(tǒng)的正常運營埋下了不少的“雷”。
在經歷數次“多么痛的領悟”之后,他們逐漸認識到標準化的重要性,并通過如下方面的實踐,有效杜絕了各種“任性”。
軟硬件類型標準化
無論是網絡設備、服務器端、用戶終端,還是操作系統(tǒng)和應用軟件,他們都有既定的支持和首選的列表。
這樣一來,在品牌和型號層面上大幅降低了不兼容性,并縮小了排查的可能性范圍。
安裝配置標準化
可參照的實施步驟文檔與配圖包括:
- 設備上架安裝所在的機房和機架的物理位置約定。
- 網線、電源線的走向、編號和顏色等規(guī)范。
- 在服務器端,涉及到虛擬硬件資源(CPU、內存、磁盤空間、分區(qū)大小)的分配、虛擬機安裝文件的準備、主機名/IP地址/默認使用目錄/日志目錄/代碼目錄的定義。
- 在用戶端,通過 PXE 和 cobbler 來使用鏡像文件批量安裝操作系統(tǒng)。
- 規(guī)范服務端所用到的基礎支撐軟件(如 IIS)和產品應用的部署路徑和配置順序。
- 賬號名稱、對應的密碼和權限屬性、以及服務與端口的關開列表。
流程規(guī)范標準化
無論是新建發(fā)布、服務變更、事件處理、事故響應、還是項目推進等,都有可遵循的流程和清晰的操作次序圖表。
交接標準化
雖然他們不像一些互聯(lián)網企業(yè)那樣有專門的 Dev 團隊、且產品迭代也不頻繁,但是他們也充分考慮到了“建轉運”過程中的風險。
通過分階段、分步驟地制定了相應的轉化流程,他們實現(xiàn)了測試賬戶的及時回收,并合理區(qū)分了系統(tǒng)類與業(yè)務類賬戶與數據的遷移。
除了上述各個方面的標準化之外,他們還日常維護著諸如:硬件設備全量清單、軟件應用全量清單、第三方服務提供清單、干系人聯(lián)系清單等支持類文檔。
這些文檔多以圖表的形式清晰直觀地提供了各類速查的信息,同時方便了后面將要提到的平臺化所進行的二次篩選與統(tǒng)計。
他們有專門的共享知識庫(后面會提到 CMDB)來分門別類地妥善存放所有的標準化文檔。
可以說,他們以標準化作為基礎的 Ops+ 模式,能有效地降低人員犯低級錯誤的發(fā)生頻率,統(tǒng)一整體的服務水平,提高他們的響應和處理速度,并能簡化對其工作質量的考核。
自動化—操作與安全
雖說上述各個方面的標準化能夠從規(guī)范的角度減少出錯的可能,但是隨著需要維護的設備數量和系統(tǒng)復雜程度的增加,各種重復性的例行操作日趨占據了維護人員的大量時間和精力。
為了控制成本和增加系統(tǒng)本身的魯棒性,他們的團隊在如下方面進行了自動化的嘗試,進而提高了系統(tǒng)日常管理的效率。
監(jiān)控自動化
通過軟件(如 Zabbix)的自動注冊與發(fā)現(xiàn)特性實現(xiàn)了:
- 機房環(huán)境、物理設備、網絡流量、虛擬化、數據庫、業(yè)務應用、存儲狀態(tài)、備份作業(yè)和日志等方面的實時自動巡檢。
- 自動跟蹤監(jiān)測的項目除了標準的 CPU、內存、磁盤、I/O 之外,還有定制化的某項服務(如 Nginx、PHP 頁面等)的 KPI 性能。
- 在顯示上通過自動發(fā)現(xiàn),能提供 2D 機房拓撲圖、3D 機架視圖、地域鏈路實時圖、流量歷史曲線圖和各類應用的dashboard等。
而運維人員通過進一步點擊,則可細致到每個服務自有的狀態(tài)視圖,以便人工分析潛在的異常并介入跟蹤診斷。
操作自動化
善假于物方可事半功倍:
- 通過調用各種云服務平臺所提供的 API,自動化啟/停、操作和管理云端的服務。
- 運用 SaltStack 在初始化好的操作系統(tǒng)上部署 Nginx,運用預先定制好 sls 之類的文件對目標主機進行程序包、文件、網絡配置、服務以及用戶等方面的管理。
- 使用 Ansible 來實現(xiàn)上述標準化的安裝部署方案,把多個 Shell、Python、PowerShell、Bat 等腳本串在一起執(zhí)行,實現(xiàn)對系統(tǒng)和服務的流程化操作。
- 在補丁和訂閱方面,他們有用到 SCCM 和 Yum 分別對服務器端的 Windows 和 Linux 進行自動化的定期更新和升級。
- 這些軟件通過對版本文件的上傳、分發(fā)、以及在必要時進行的回滾等實現(xiàn)各種版本控制與更新操作。
- 根據自動化監(jiān)控到的事件進行知識關聯(lián),依照既定的規(guī)則進行自動化的初步響應,包括各種報警和服務中斷保護等。
安全自動化
上述操作自動化雖然能夠廣受運維人員的推崇,但勢必會涉及到對特權的調用和對基線的調整。
為了防范由此所帶來的安全隱患和漏洞,他們也上馬和啟用了針對安全運維方面的自動化:
- 根據身份和訪問管理(IAM)原則,安全程序能智能地識別出各種場景,如:請求 SSH 的服務在屢次嘗試性登錄失敗后,僅有一次成功的記錄。
非活躍 VPN 用戶在非常規(guī)工作時間登錄,并對共享文件進行頻繁的移動、復制甚至是刪除等操作。
某臺主機向內網的其他主機發(fā)送探測掃描包;網絡設備的配置在計劃外的時間被更改;以及 Web 頁面出現(xiàn) 404、401、500 等錯誤代碼。
- 基線核查:對于主機而言,對指定目錄和文件的完整性檢查,對指定設備和系統(tǒng)的端口勘察,對指定操作系統(tǒng)的注冊表、服務和進程、以及惡意軟件 Rookit 和 WebShell 予以檢查。
而對于內網的數據流量而言,則是對協(xié)議、內容和攻擊簽名模式的匹配檢查。
- 自動合規(guī):根據審計的流程,檢查各個系統(tǒng)上多余/可疑的賬號與組,文件/文件夾的屬性/訪問權限,遠程訪問的 IP 與賬戶限制,靜態(tài)代碼中的漏洞,各類補丁與防毒簽名的更新等,并且能根據既定的 playbook 自動進行整改和加固。
平臺化—監(jiān)控與管理
業(yè)界喜歡用物理學上的熵理論來闡述:倘若不對 IT 系統(tǒng)進行人工管控的話,則會趨向于無序。
Tim 和他的運維團隊認識到:如果日常運維工作完全依賴于標準化和自動化進行推進的話,很快就會陷入“中年油膩”,大家也會頻繁被動地打“遭遇戰(zhàn)”。
因此,他們基于過往的經驗匯總、需求分析、當然也考慮到實際預算,設計并集成了一個具有可視化和方便管控的平臺架構。該平臺具體由如下三部分所組成:
資產、資源管理
做到手中有糧,心里不慌:
- 通過建立 CMDB 來存儲所有的主機名、域名、IP 地址及分配范圍、應用服務特征屬性等資產相關的信息,從而為日常運維和問題處理提供最新且完整的信息。
下一階段,他們將引入數據分析模塊,分析一般用戶和專業(yè)運維人員登錄該平臺后,檢索知識庫的方式(如題名、關鍵詞、作者、部門等)、使用頻率、駐留時間、反饋信息等。
- 在平臺上融入服務資產和配置管理(Service Asset and Configuration Management,SACM)的概念,通過梳理和建立資產、應用和使用者的對應關系,平臺能夠快速、準確地獲知新發(fā)布的服務和應用,從而自動化執(zhí)行掃描、編錄和后續(xù)的管理。
- 引入“容器”的概念,從資產的購置入庫開始進行整個生命周期的跟蹤,及時回收閑置的資產,在提高資源復用率的前提下避免了資源的浪費和設備超期服役所帶來的安全隱患。
- 對關鍵備件狀態(tài)和第三方服務合同,這兩個容易被忽視的地帶提供平臺化的跟蹤管理,為預算和決策提供數據依據。
監(jiān)控報警
一站式獲取策略的實施和服務的狀態(tài):
- 平臺提供一致的可視化入口,實時反映:人員的操作行為(用戶操作、文件處置與打印、移動設備使用)、設備與服務的運行狀況、鏈路的連接質量與擁塞程度、數據存儲與備份作業(yè)完全情況、工具與文檔的更新頻率等。
- 通過各種標準接口對自建的或是由第三方平臺提供的云服務進行監(jiān)控。例如:通過設定監(jiān)控的頻率和觸發(fā)報警的閥值,獲知資源(CPU、IOPS)的使用率、通用服務(如 HTTP、PING 等)和特定服務(如果 POST 方法、HEAD 方法)的可用狀態(tài)和請求響應的時間。
事件分析
做到事前防范、事中控制、事后溯源:
- 從兩個維度出發(fā),分別抓取和過濾來自各個主機層面的系統(tǒng)事件和基于網絡的異常流量信息,通過持續(xù)將經過整理的日志信息寫入 Hbase 數據庫,為后期的各種故障診斷和攻擊取證提供重要的判定依據。
- 管理平臺對某些事件的發(fā)生次數和頻率進行統(tǒng)計,為了去重,系統(tǒng)可以對事件進一步按照其特征碼的種類予以分組顯示。
- 在平臺上引入了應用性能分析(APM)模塊,能夠精確地定位到應用服務中某個 URL 的訪問速度的驟降、或是用戶在網站上提交某個 SQL 執(zhí)行語句時的延時,這些都能協(xié)助運維人員快速定位問題。
- 平臺通過關聯(lián)分析,可以有效地處置風險、提出持續(xù)改進的建議,以及發(fā)現(xiàn)和預報可能出現(xiàn)的問題。
小結
我正好在采訪 Tim 之前閱讀過《鳳凰項目——一個IT運維的傳奇故事》一書,書中很多橋段與他所奉行的 Ops+ 模式遙相呼應。
在 Tim 看來,通過他們的 Ops+,運維人員提升了對系統(tǒng)各類隱患的發(fā)現(xiàn)能力、對例行操作的處理能力、對應急事故的恢復能力和對內外攻擊的應對能力。
正如他自己所坦言的那樣:“我們正在確保自己所維護的系統(tǒng)能從 run right(運行正確)穩(wěn)步進化為 right run(正確地運行)”。
好了,最后低調地幫他打一下 call 吧:希望上述分享的運維“大禮包”能夠如一杯泡滿枸杞的保溫杯一般給您在這個冬天帶來一絲暖意。
陳峻(Julian Chen) ,有著十多年的 IT 項目、企業(yè)運維和風險管控的從業(yè)經驗,日常工作深入系統(tǒng)安全各個環(huán)節(jié)。作為 CISSP 證書持有者,他在各專業(yè)雜志上發(fā)表了《IT運維的“六脈神劍”》、《律師事務所IT服務管理》 和《股票交易網絡系統(tǒng)中的安全設計》等論文。他還持續(xù)分享并更新《廉環(huán)話》系列博文和各種外文技術翻譯,曾被(ISC)2 評為第九屆亞太區(qū)信息安全領袖成就表彰計劃的“信息安全踐行者”和 Future-S 中國 IT 治理和管理的 2015 年度踐行人物。

【51CTO原創(chuàng)稿件,合作站點轉載請注明原文作者和出處為51CTO.com】












