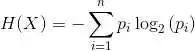用深度學習和樹搜索進行從零開始的既快又慢的學習
本文介紹了來自倫敦大學學院(UCL)Thomas Anthony、Zheng Tian 與 David Barber 的深度學習與樹搜索研究。該論文已被 NIPS 2017 大會接收。
二元處理機制理論
「二元處理機制」認為,人類的推理包括兩種不同種類的思考方法。如下圖所示,系統 1 是一個快速的、無意識的、自動化的思考模式,它也被稱為直覺。系統 2 是一個慢速的、有意識的、顯式的、基于規則的推理模式,它被認為是一種進化上的最新進展。
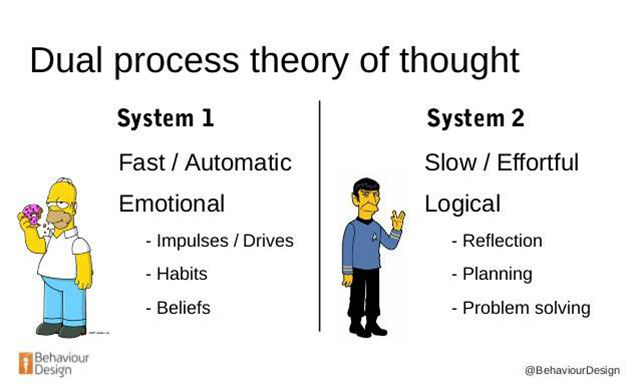
圖片出處:https://www.slideshare.net/AshDonaldson/behaviour-design-predicting-irrational-decisions
在學習完成某項具有挑戰性的規劃任務(例如棋牌類游戲)時,人類會同時運用這兩種處理方式:準確的直覺可以快速地選擇有利路線,這使我們慢速的分析推理更加高效。而持續的深入學習又能逐漸提升直覺,從而使更準確的直覺回饋到更強大的分析中,這就形成了一個閉合的學習回路。換言之,人類是通過既快又慢的思考方式來學習的 [1]。
目前的深度強化學習存在什么問題?
在當前的深度強化學習算法中,例如策略梯度(Policy Gradient)和 DQN3[3], 神經網絡在選擇動作的時候沒有任何前瞻性;這個和系統 1 類似。與人類直覺不同的是,這些強化學習算法在訓練的過程中并沒有一個「系統 2」來給它們推薦更好的策略。
AlphaGo 這類 AI 算法的一個缺陷之處在于,它們使用了人類專業玩家的數據庫 [4]。在訓練的初始階段,強化學習智能體會模仿人類專家的行動—而只有經歷這樣的初始階段,它們才會開始潛在地學習更強大的超人類玩法。但是這種算法從某種程度而言并不令人滿意,因為它們可能會嚴重偏向某人類玩家的風格,從而忽視潛在的更好策略。同時,人類專家數據庫在游戲領域中或許可得,而如果我們想要在其他情況下訓練出一個 AI 機器,也許我們并沒有這種可用的數據庫。因此,從零開始訓練出一個最先進的棋牌游戲玩家對 AI 而言是一項主要挑戰。
專家迭代 (ExIt)
專家迭代(ExIt)是我們在 2017 年 5 月介紹的一個通用學習框架。它能夠在不需要模仿人類策略的情況下就訓練出強大的 AI 機器。

ExIt 可被視為模仿學習(Imitation Learning)的延伸,它可以擴展至連頂尖人類專家也無法達到滿意表現的領域中。在標準的模仿學習中,學徒被訓練以模仿專家的行為。ExIt 則將此方法延伸至一種迭代學習過程。在每一次迭代中,我們都會執行一次專家提升(expert improvement)步驟,在這個過程中我們會依靠(快速的)學徒策略來改善(相對較慢的)專家的表現。
ExIt
象棋這類棋類游戲或許可以幫助我們更直觀地了解這個概念。在這類游戲中專家就類似于慢手下棋的棋手(每一步都花好多時間來決策),而學徒就像在下快棋(每一步都花很少時間決定如何走)。
一份獨立的研究顯示,玩家會在同一個位置考慮多個可能的行動,深入(緩慢)地思考每一步可能的行動。她會分析在當前位置哪幾手棋會成功而哪幾手棋會失敗。當在未來遇到相似的棋局時,她之前的學習所培養出來的直覺就會迅速告訴她哪幾手棋會可能更好。這樣即使在快棋設置下,她依然可以表現不俗。她的直覺就來源于她模仿自己之前通過深度思考計算而獲得的強大策略。人類不可能僅僅通過快棋而變成卓越的棋手,更深入的研究是學習過程中必需的部分。
對人工智能游戲機器而言,這種模仿是可以實現的,例如,將一個神經網絡擬合到另一個「機器專家」的某一步棋。在短時間之內通過模仿目前所見到的專家的行動,學徒就可以學習到一個快棋策略。這里的關鍵點在于,假設在這個游戲背后存在一個潛在的結構,機器學習就能夠讓學徒將它們的直覺泛化到以前沒有見到過的狀態中去采取快速決策。也就是說,學徒沒有僅僅是從有限的,固定的專家棋譜數據庫中創建一個行動查詢表,而是能將所學泛化到其他棋局狀態中。所以神經網絡既起著泛化的作用,也起到了模仿專家玩家的作用。
假設學徒通過模仿目前所見到的所有專家行動學到了一個快速決策,那么它就可以被專家所用。當專家希望采取行動的時候,學徒會很快地給出一些備選行動,然后專家會進行深入考慮,并且也許在這個慢速思考的過程中,專家還會繼續受到學徒的敏銳直覺的指引。
在這個階段的最后,專家會在學徒的輔助下采取一些行動,這樣,每一步行動通常都會比僅由專家或者僅由學徒單獨做出的行動要好。
接下來,上述的過程可以從學徒重新模仿(新)專家推薦的行動開始,反復進行下去。這會形成一個完整的學習階段的迭代,迭代過程將持續,直到學徒收斂。
從二元處理機制方面來看,模仿學習(imitation learning)步驟類似于人類通過研究實例問題來提升直覺,然而專家提升(expert improvement)步驟則類似于人類利用自己已經得到提升的直覺去指導未來的分析。
樹搜索和深度學習
ExIt 是一種通用的學習策略,學徒和專家可以用不同的形式具體化。在棋牌類游戲中,蒙特卡洛樹搜索(Monte Carlo Tree Search)是一個強大的游戲策略 [6],是專家角色的天然候選者。深度學習已經被證明是一種模仿強悍玩家的成功方法 [4],所以我們將它作為學徒。
在專家提升(expert improvement)階段,我們使用學徒來指引蒙特卡洛樹搜索算法,讓它朝著更有希望的方向行動,這有效地減少了游戲樹搜索的寬度和深度。以這種方式,我們就能夠把在模仿學習中得到的知識返回來用在規劃算法中。
棋牌游戲 HEX
Hex 是一款經典的兩玩家棋牌游戲,玩家在 n×n 的六邊形格子上角逐。玩家顏色分為黑和白,輪流將代表自己顏色的棋子放在空格子中,如果有一列依次相連的黑子從南到北連在了一起,那么黑方獲勝。如果有一列依次相連的白子從東到西連通,那么白方獲勝。
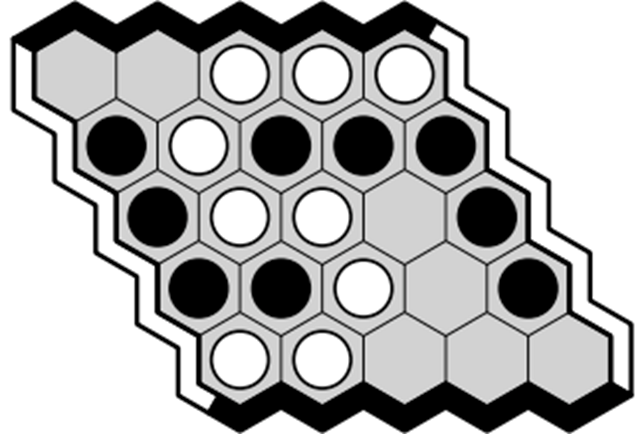
5×5 的 Hex 棋盤示例
上面是一個 5×5 的棋盤,其中白方獲勝。Hex 有深度策略,這使得它對機器而言極具挑戰性,它巨大的動作集合和連接規則意味著它和圍棋給人工智能帶來的挑戰有些類似。然而,與圍棋相比,它的規則更加簡單,而且沒有平局。
Hex 的規則很簡單,因此數學分析方法非常適用於此,目前最好的機器玩家 MoHex[7] 使用的是蒙特卡洛樹搜索和巧妙的數學思想。自 2009 年,MoHex 在所有的計算機游戲奧林匹克 Hex 競賽中戰無不勝。值得注意的是,MoHex 使用了人類專家數據庫訓練展開策略 (rollout policy)。
讓我們一起驗證,在不使用任何專業知識和人類專家棋譜的情況下(游戲規則除外),ExIt 訓練策略是否可以訓練出一個勝過 MoHex 的 AI 玩家。為此,我們使用蒙特卡羅樹搜索作為專家,由學徒神經網絡來引領專家。我們的神經網絡是深度卷積神經網絡的形式,具有兩個輸出策略–一個給白方,另一個給黑方(細節參見 [5])。
修正過的蒙特卡羅樹搜索公式可實現專家提升(expert improvement):
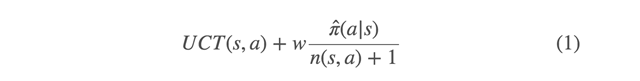
這里,s 是一個棋局狀態,a 是一個在狀態 s 下可能被采取的行動。UCT(s,a) 是蒙特卡羅樹搜索中所使用的樹 [6] 的經典上置信區間(Upper Confidence Bound),后面所加的那一項能幫助神經網絡學徒指導專家搜索更佳的行動。其中π̂ 是學徒的策略(在狀態 s 中對于每個潛在行動 a 的相對優勢),n(s,a) 是搜索算法在狀態 s 做出行動 a 的當前訪問次數;w 是為了平衡專家的慢思考和學徒的快思考而經驗性選擇的權重因子。該附加項使神經網絡學徒引領搜索至更有希望的行動,并且更快地拒絕不佳的行動。
為了在每一個模仿學習階段生成用以訓練學徒的數據,批處理方法每次都重新生成數據,拋棄之前迭代中產生的所有數據。因此,我們同時也考慮了一個僅保存有限的最新生成數據的在線版本,以及一個保留所有數據的在線版本,但是隨著與最強玩法對應的最新專家的增多,數據會成指數增長。在下圖中我們對比了一些不同的方法:從訓練的時間去衡量每一種學習策略網絡的強度(測量 ELO 分數)。
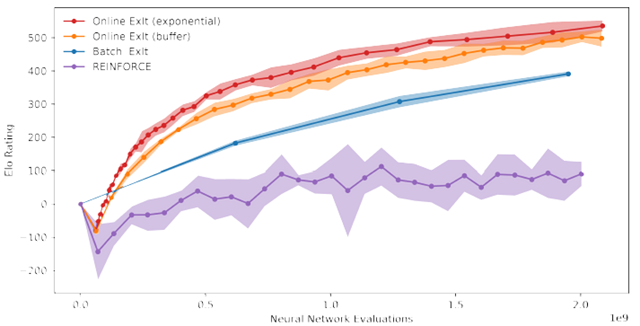
我們還展示了僅僅使用一個更傳統的強化學習方法,通過自我對弈(self play)學到策略 π̂ (a|s) 的結果(換言之不使用蒙特卡羅樹搜索)。這正是 AlphaGo 訓練策略網絡時所用的方法。上圖的結果證明:ExIt 訓練方法比傳統方法更高效。值得注意的是,在這個例子中訓練還沒有完全收斂,在更充足的訓練時間下,學徒還能進一步提升能力。
在論文中 [5],我們也運用了另一種能提升棋手性能的機制,也就是能夠讓學徒估計在自己獨自下棋時獲勝的概率的價值網絡 Vπ̂ (s)。策略網絡和價值網絡被結合起來以幫助指導最終受學徒輔助的蒙特卡羅樹搜索玩家(apprentice-aided MCTS player)。策略網絡和價值網絡使用一個和(1)近似,但是又有所修改(包含了學徒在 s 狀態的價值)的方程指導最終的 MCTS 玩家。(細節參考 [5])
我們最終的 MCTS 玩家表現超越了最著名的 Hex 機器玩家 MoHex,在 9X9 的棋局中勝率是 75%。考慮到訓練沒有完全收斂,表示這個結果更加卓越。[9] 中展示了一些我們使用 ExIt 訓練游的游戲機器玩家與目前最優的 MoHex 玩家對陣的情況。我們對比了從同一個狀態開始時不同算法的玩法。論文 [5] 中有更多的例子。

ExIt(黑方)VS MoHex(白方)
MoHex(黑方)VS ExIt(白方)
ExIt 為何會如此成功?
部分原因模仿學習一般比強化學習容易,因此 EXIT 要比像 REINFORCE 等任意模型(model-free)的算法更成功。
此外,唯有在搜索中,相對其他選擇來說,沒有缺點的行動才會被 MCTS 推薦。因此 MCTS 的選擇會比大多數潛在對手的選擇更好。相比之下,在常規的自我對弈(網絡自身充當對手角色)中,行動都是基于打敗當前僅有的一個對手而推薦的,(因此所訓練的棋手很有可能對當前的非最優對手過擬合)。我們認為這就是為什么 EXIT(使用 MCTS 作為專家時)會如此成功的關鍵因素 –事實上學徒在與很多對手的對戰中都能取得良好的表現。
與 ALPHAGO ZERO 的關系
AlphaGo Zero[10](在我們的工作 [11] 發表之后的幾個月之后問世)也實現了一種 ExIt 風格的算法,并且證明,在圍棋中可以在不使用人類棋手棋譜的情況下達到當前最佳水平。論文 [5] 中給出了詳細的對比。
總結
專家迭代是一種新的強化學習算法,它受啟發于人類思維的二元處理機制理論。ExIt 將強化學習分解為兩個獨立的子問題:泛化和規劃。規劃在具體分析的基礎上執行,并且在找到了強大的策略之后將之泛化。這將允許智能體做長期規劃,并進行更快速的學習,即使在極具挑戰的問題也能達到高水平表現。這個訓練策略在棋牌類人工智能玩家中是非常強大的,不需要任何人類專家的棋譜就能達到當前最佳性能。