PostgreSQL邏輯優化—這樣搭建整體架構
一棵完成 transform 和 rewrite 操作的查詢樹是否是一棵***的查詢樹?如果不是,那么又該如何對該查詢樹進行優化?而優化所使用的策略正是本文要討論的重點內容,而且優化部分也是整個查詢引擎的難點。
子鏈接(SubLink)如何優化?子查詢(SubQuery)又如何處理?對表達式(Expression)如何進行優化?如何尋找***的查詢計劃(Cheapest Plan)?哪些因素會影響 JOIN 策略(Join Strategies)的選擇,而這些策略又是什么?查詢代價(Cost)又是如何估算的?何時需對查詢計劃進行物化(Plan Materialization)處理等一系列的問題。
在查詢計劃的優化過程中,對不同的語句類型有著不同的處理策略:
(1)對工具類語句(例如,DML、DDL 語句),不進行更進一步的優化處理。
(2)當語句為非工具語句時,PostgreSQL 使用 pg_plan_queries 對語句進行優化。
與前面一樣,PostreSQL 也提供定制化優化引擎接口,我們可以使用自定義優化器 planner_hook,或者使用標準化優化器 standard_planner。
Pg_plan_queries 的函數原型如下所示。

邏輯優化——整體架構介紹
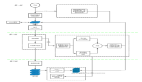
在未使用第三方提供的優化器時,PostgreSQL 將 planner 函數作為優化的入口函數,并由函數 subquery_planner 來完成具體的優化操作。從下圖中的 Call Stack 我們可以看出 planner 與 subquery_planner 之間的調用關系。

函數以查詢樹作為輸入參數,并以優化后語句作為返回值。
在 standard_planner 中,首先處理 “DECLARE CURSOR stmt” 形式的語句,即游標語句,并設置 tuple_fraction 值。那么 tuple_fraction 又是什么呢?
tuple_fraction 描述我們期望獲取的元組的比例,0 代表我們需要獲取所有的元組;當 tuple_factionÎ(0,1) 時,表明我們需要從滿足條件的元組中取出 tuple_faction 這么多比例的元組;當 tuple_factionÎ [1,+¥ ) 時,表明我們將按照所指定的元組數進行檢索,例如,LIMIT 語句中所指定的元組數。
完成對 tuple_faction 的設置后,進入后續優化流程,subquery_planner 的函數原型如下所示。

這里也許你也許會迷惑,為什么是 subquery_planner 呢?從名字上看該函數像是用來處理子查詢,那么為什么用來作為整個查詢語句優化的入口呢(Primary Entry Point)?
子查詢語句作為查詢語句的一部分,很大程度上與父查詢具有相似的結構,同時兩者在處理方式和方法上也存在著一定的相似性:子查詢的處理流程可以在對其父查詢的過程中使用。例如,本例中的子查詢語句 SELECT sno FROM student WHERE student.classno = sub.classno,其處理方式與整個查詢語句一樣。因此,使用 subquery_planner 作為我們查詢優化的入口,雖然從函數名上來看其似乎是用于子查詢語句的處理。
由 gram.y 中給出的 SelectStmt 的定義可以看出,其中包括了諸如 WINDOWS、HAVING、ORDER BY、GROUP BY 等子句。那du么 subquery_planner 函數似乎也應該有相應于這些語句的優化處理。就這點而言,subquery_planner 與原始語法樹到查詢樹的轉換所采取的處理方式相似。根據上述分析,我們可給出如下所示的 subquery_planner 的函數原型。

按照上述給出的原型,只要完成假定的 process_xxx 函數,就可以實現對查詢語法樹的優化工作。是不是覺得很簡單?當然不是,原理很簡單,但是理論與實際還有一定的距離。
例如,如何處理查詢中大量出現的子鏈接?如何對 d 算子執行 “下推”?如何選擇索引?如何選擇 JOIN 策略?這些都需要我們仔細處理。
PostgreSQL 給出的 subquery_planner 如下所示。


由 PostgreSQL 給出的實現可以看出,核心處理思想與我們討論的相一致:依據類型對查詢語句進行分類處理。
這里需要注意的一點就是查詢計劃的生成部分,PostgreSQL 將查詢計劃的生成也歸入 subquery_planner 中,但為了方便問題的討論,我們并未將查詢計劃的生成部分在 subquery_planner 中給出。我們將查詢優化的主要步驟總結如下:
處理 CTE 表達式,ss_process_ctes; 上提子鏈接,pull_up_sublinks; FROM 子句中的內聯函數,集合操作,RETURN 及函數處理,inline_set_returning_ functions; 上提子查詢,pull_up_subqueries; UNION ALL 語句處理,flatten_simple_union_all; 處理 FOR UPDATE(row lock)情況,preprocess_rowmarks; 繼承表的處理,expand_inherited_tables; 處理目標列(target list),preprocess_expression; 處理 withCheckOptions,preprocess_expression; 處理 RETURN 表達式,preprocess_expression; 處理條件語句 - qual,preprocess_qual_conditions; 處理 HAVING 子句,preprocess_qual_conditions; 處理 WINDOW 子句,preprocess_qual_conditions; 處理 LIMIT OFF 子句,preprocess_qual_conditions; WHERE 和 HAVING 子句中的條件合并,如果存在能合并的 HAVING 子句則將其合并到 WHERE 條件中,否則保留在 HAVING 子句中; 消除外連接(Outer Join)中的冗余部分,reduce_outer_joins; 生成查詢計劃,grouping_planner。