分布式高并發緩存設計系統
概述
緩存概述
什么是緩存
緩存在wiki上的定義:用于存儲數據的硬件或軟件的組成部分,以使得后續更快訪問相應的數據。緩存中的數據可能是提前計算好的結果、數據的副本等。典型的應用場景:有cpu cache, 磁盤cache等。本文中提及到緩存主要是指互聯網應用中所使用的緩存組件。
為什么引入緩存
傳統的后端業務場景中,訪問量以及對響應時間的要求均不高,通常只使用DB即可滿足要求。這種架構簡單,便于快速部署,很多網站發展初期均考慮使用這種架構。但是隨著訪問量的上升,以及對響應時間的要求提升,單DB無法再滿足要求。這時候通常會考慮DB拆分(sharding)、讀寫分離、甚至硬件升級(SSD)等以滿足新的業務需求。但是這種方式仍然會面臨很多問題,主要體現在:
性能提升有限,很難達到數量級上的提升,尤其在互聯網業務場景下,隨著網站的發展,訪問量經常會面臨十倍、百倍的上漲。
成本高昂,為了承載N倍的訪問量,通常需要N倍的機器,這個代價難以接受。
一丶分布式高并發緩存設計系統
總體架構圖
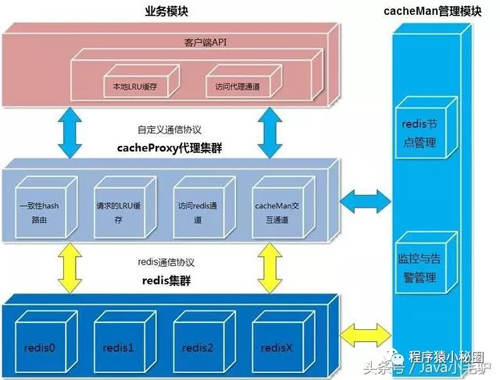
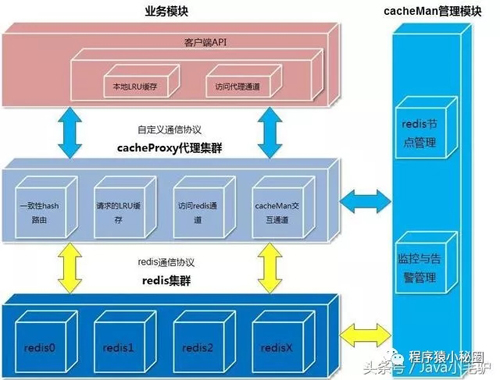
1.2自定義的客戶端協議
業務模塊采用自定義應用層協議和cacheProxy交互
整個cache后端采用什么協議,什么存儲(redis,memcached等)對業務模塊透明
cache后端和業務端進行了隔離,修改互不影響
1.2負載均衡與容錯機制
采用一致性hash算法,即使部分節點down機,也不會導致全部的緩存失效,新增節點也不會導致大量緩存失效和重建
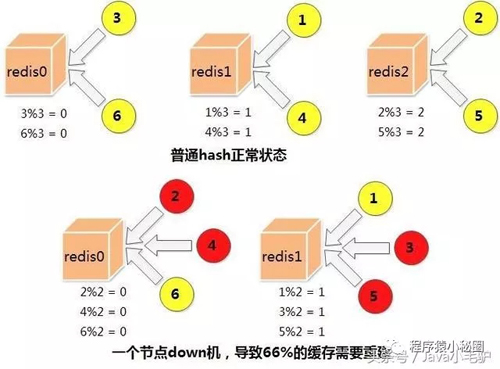
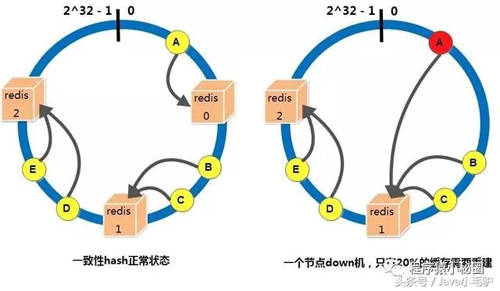
一份緩存數據保留兩份,當前hash節點和下一個真實的hash節點,單個節點down機時,緩存也不會馬上失效
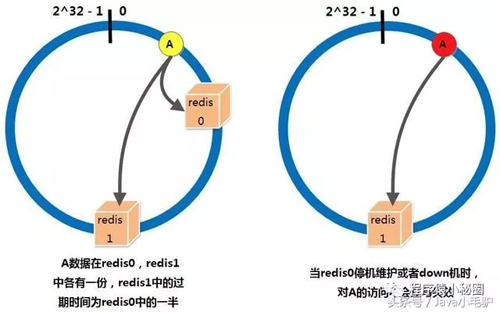
cacheMan是一個弱的管理節點,負責監控,刪除節點,新增節點,可以任意啟停
1.3緩存維護與淘汰機制
redis原生超時機制+三層LRU緩存架構,減少最終穿透到redis實例上的請求。
客戶端LRU緩存
cacheProxy代理LRU緩存
redis實例內存總量限制+LRU緩存
1.4安全機制
redis實例都會開啟auth功能
redis實例都監聽在內網ip
1.5核心流程
新增redis節點
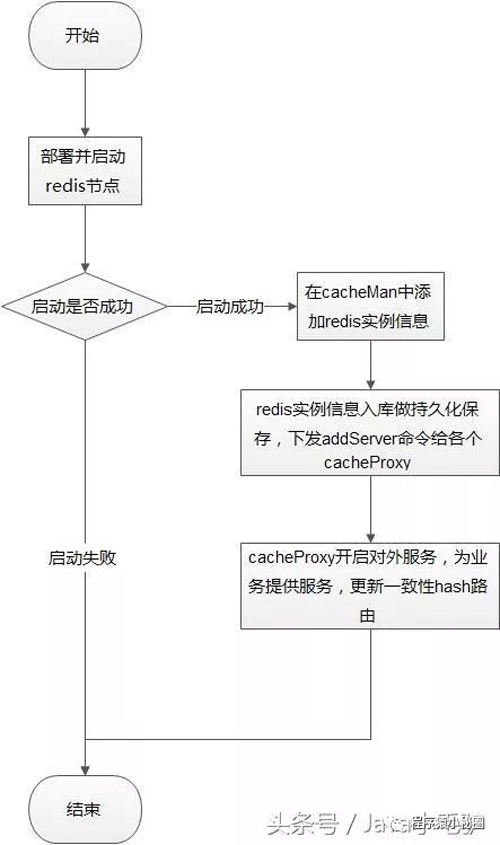
刪除redis節點

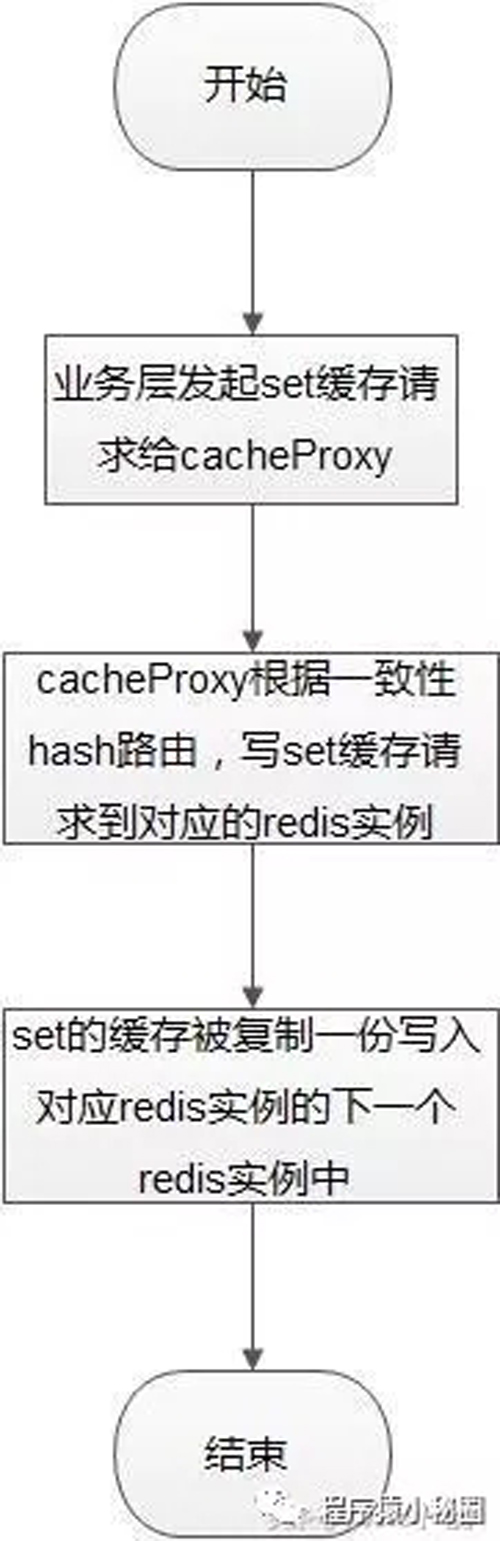
set緩存
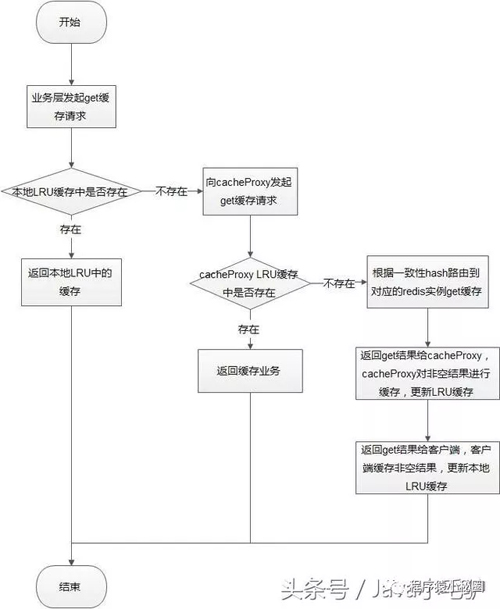
get緩存
二、問題
任何平臺隨著用戶規模的擴大、功能不斷的添加,持久化數據庫層承受的讀寫壓力會越來越大,一旦數據庫承壓過大會導致讀寫性能陡然下降,嚴重時會導致大量的業務請求超時,進而發生“雪崩”引發嚴重的故障。
三、解決方案
在業務層和數據庫持久層之間引入一層內存緩存層,對于復雜且業務邏輯上不會變化的查詢結果進行緩存,業務請求再次發起時,每次都先從緩存層中查詢,從而大大減少對數據庫的查詢,減小對數據庫的壓力。
四、分布式內存緩存、本地單點緩存、應用層緩存對比
類型穩定性擴展性通用性對代碼的侵入性
應用層緩存應用會頻繁重啟更新,緩存易丟失,穩定性不佳差,受限于進程的資源限制差,不同應用難以復用代碼侵入性小,無網絡操作,只需要操作應用進程內存
本地單點緩存獨立的緩存應用(redis、memcached等),不會頻繁重啟,穩定性一般,但有單點故障問題一般,受限于單服務器資源限制一般,業務應用和緩存應用有強耦合代碼侵入性一般,需要引入對應的api通常有網絡操作
分布式內存緩存分布式系統,具備故障自動恢復功能,無單點故障問題,穩定性佳好,支持水平擴展好,對業務層提供通用接口,后端具體的緩存應用對業務透明代碼侵入性一般,需要引入通用的api通常有網絡操作。