分布式搜索系統(tǒng)的設(shè)計(jì)
一、介紹
如今,我們幾乎在每個(gè)網(wǎng)站上都看到一個(gè)搜索欄。搜索欄使我們能夠快速找到我們需要的內(nèi)容。
讓我們舉個(gè)例子。想象一下,如果YouTube沒有提供搜索欄,我們?nèi)绾卧跀?shù)百萬個(gè)視頻中找到特定的視頻,這些視頻多年來都已上傳到Y(jié)ouTube?用戶僅通過滾動(dòng)瀏覽很難找到他們想要的內(nèi)容。
在每個(gè)搜索欄背后,都有一個(gè)搜索系統(tǒng)。

二、需求
- 可用性:系統(tǒng)應(yīng)對用戶高度可用。
- 可擴(kuò)展性:系統(tǒng)應(yīng)能夠隨著數(shù)據(jù)量的增加而擴(kuò)展。換句話說,它應(yīng)能夠索引大量數(shù)據(jù)。
- 快速搜索大數(shù)據(jù):無論用戶搜索多少內(nèi)容,他們都應(yīng)該能夠快速獲取結(jié)果。
三、核心概念
倒排索引
- 索引 — 是組織和操作數(shù)據(jù)的過程,旨在促進(jìn)快速和準(zhǔn)確的信息檢索。
- 倒排索引 — 是一種類似于哈希映射的數(shù)據(jù)結(jié)構(gòu),它使用文檔-詞術(shù)矩陣。它不是將完整文檔存儲(chǔ),而是將文檔拆分為單個(gè)詞語。然后,文檔-詞術(shù)矩陣識(shí)別唯一的詞語,并丟棄頻繁出現(xiàn)的詞語,如“to”、“they”、“the”、“is”等等。
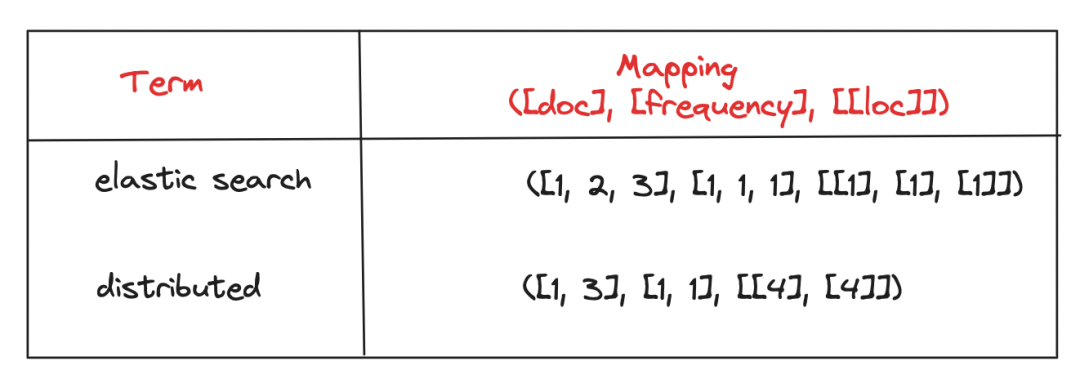
圖1.0:倒排索引
“映射”列中的每個(gè)條目都包括三個(gè)列表:
- 詞語出現(xiàn)的文檔列表。
- 統(tǒng)計(jì)詞語在每個(gè)文檔中出現(xiàn)的頻率的列表。
- 指出詞語在每個(gè)文檔中的位置的二維列表。一個(gè)詞語可以在同一文檔中出現(xiàn)多次,因此使用二維列表。
對于提取的每個(gè)詞語,我們要么在倒排索引中添加新行,要么在該詞語已經(jīng)在倒排索引中有條目的情況下更新現(xiàn)有條目。同樣,在刪除文檔時(shí),我們需要處理,找到已刪除文檔詞匯在倒排索引中的條目,然后相應(yīng)地更新倒排索引。
四、設(shè)計(jì)
在添加文檔或運(yùn)行搜索查詢時(shí),需要將倒排索引加載到主內(nèi)存中。為了效率,必須將倒排索引的大部分內(nèi)容適應(yīng)于機(jī)器的RAM中。
這意味著我們必須將大量數(shù)據(jù)加載到RAM中。不是增加單臺(tái)機(jī)器的資源來索引十億頁,而是要轉(zhuǎn)向分布式系統(tǒng),利用并行化的力量。
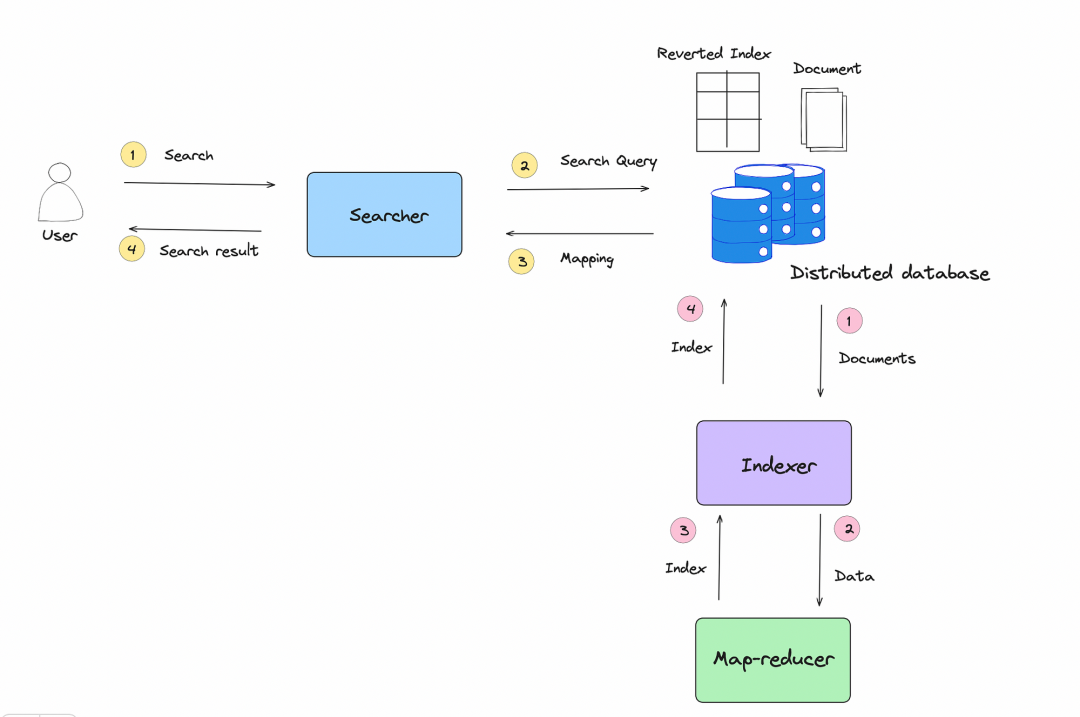
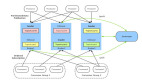
圖2.0:分布式搜索系統(tǒng)的高級設(shè)計(jì)
- 索引器從分布式存儲(chǔ)中獲取文檔,并使用MapReduce進(jìn)行索引,MapReduce運(yùn)行在分布式的普通機(jī)器集群上。索引器使用分布式數(shù)據(jù)處理系統(tǒng)(例如MapReduce)進(jìn)行并行和分布式索引構(gòu)建。構(gòu)建的索引表存儲(chǔ)在分布式存儲(chǔ)中。
- 使用分布式存儲(chǔ)來存儲(chǔ)文檔和索引。
- 用戶在搜索欄中輸入包含多個(gè)詞語的搜索字符串。
- 搜索器解析搜索字符串,從存儲(chǔ)在分布式存儲(chǔ)中的索引中搜索映射,并將最匹配的結(jié)果返回給用戶。
數(shù)據(jù)分區(qū)
為了實(shí)現(xiàn)成本效益,我們在索引中使用了眾多小節(jié)點(diǎn)。這個(gè)過程要求我們對輸入數(shù)據(jù)(文檔)進(jìn)行分區(qū)或拆分。
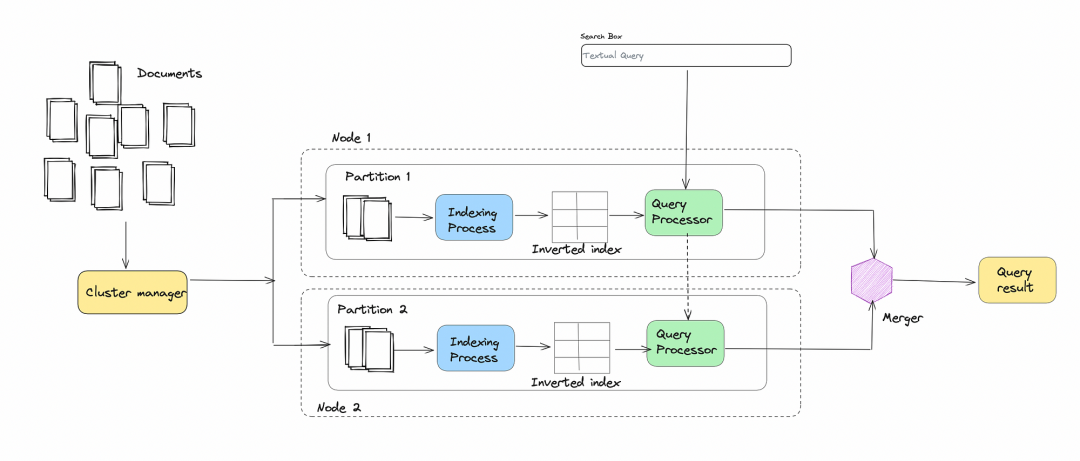
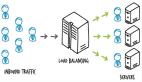
圖3.0:在多個(gè)普通機(jī)器集群中以并行方式進(jìn)行分布式索引和搜索
索引:
- 集群管理器將輸入文檔集分成N個(gè)分區(qū),其中N等于上圖中的2。每個(gè)分區(qū)的大小由集群管理器決定,考慮到數(shù)據(jù)的大小、計(jì)算、內(nèi)存限制和集群中的節(jié)點(diǎn)數(shù)量。由于各種原因,可能不是所有節(jié)點(diǎn)都可用。集群管理器通過定期心跳監(jiān)視每個(gè)節(jié)點(diǎn)的健康狀況。要將文檔分配給N個(gè)分區(qū)之一,可以使用哈希函數(shù)。
- 分區(qū)后,集群管理器在集群中的N個(gè)節(jié)點(diǎn)上同時(shí)運(yùn)行所有N個(gè)分區(qū)的索引算法。每個(gè)索引過程都會(huì)生成一個(gè)小型的倒排索引,存儲(chǔ)在節(jié)點(diǎn)的本地存儲(chǔ)中。這樣,我們生成了N個(gè)小型倒排索引,而不是一個(gè)大的倒排索引。
搜索:
- 在搜索階段,當(dāng)用戶查詢進(jìn)來時(shí),我們在存儲(chǔ)在節(jié)點(diǎn)本地存儲(chǔ)中的每個(gè)小型倒排索引上運(yùn)行并行搜索,生成N個(gè)查詢。
- 每個(gè)小型倒排索引的搜索結(jié)果都是與查詢詞語匹配的映射列表(我們假設(shè)用戶查詢是單個(gè)詞語/術(shù)語)。合并器聚合這些映射列表。
- 在聚合映射列表后,合并器根據(jù)每個(gè)文檔中詞語的頻率對文檔列表進(jìn)行排序。
- 排序后的文檔列表以升序順序返回給用戶。
復(fù)制
我們?yōu)樯煞峙浞謪^(qū)的索引節(jié)點(diǎn)創(chuàng)建副本。
通常,三個(gè)副本足夠。三個(gè)副本意味著三個(gè)節(jié)點(diǎn)托管相同的分區(qū)并生成索引。三個(gè)節(jié)點(diǎn)中的一個(gè)成為主節(jié)點(diǎn),而其他兩個(gè)是副本。同一分區(qū)將轉(zhuǎn)發(fā)到所有三個(gè)副本。我們假設(shè)每個(gè)副本都會(huì)獨(dú)立計(jì)算索引,這會(huì)導(dǎo)致資源的低效使用。與在副本上重新計(jì)算索引不同,我們只在主節(jié)點(diǎn)上計(jì)算倒排索引。接下來,我們將倒排索引(二進(jìn)制文件)傳輸?shù)礁北尽_@種方法的主要好處是避免了在副本上使用重復(fù)的CPU和內(nèi)存來進(jìn)行索引。
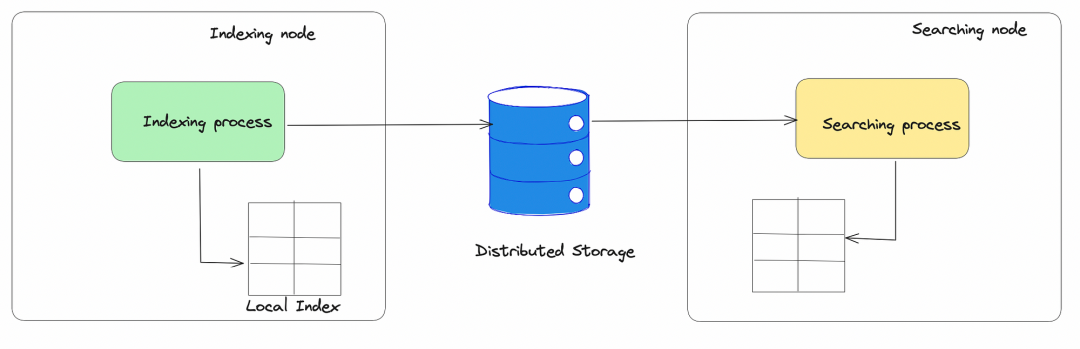
圖4.0:由索引節(jié)點(diǎn)生成的索引存儲(chǔ)在分布式存儲(chǔ)中,參與搜索的節(jié)點(diǎn)從分布式存儲(chǔ)中讀取索引以為用戶的查詢生成結(jié)果
索引和搜索之間有很強(qiáng)的分離,而沒有索引延遲的負(fù)面影響。由于這種分離,索引不會(huì)影響搜索可擴(kuò)展性,反之亦然。此外,與在副本上重新計(jì)算索引不同,我們只需復(fù)制索引文件。
在硬件故障的情況下,會(huì)添加新的搜索器或索引器機(jī)器,并從分布式存儲(chǔ)中檢索數(shù)據(jù)的副本。
五、評估
可用性
數(shù)據(jù)在分布式存儲(chǔ)中跨多個(gè)區(qū)域進(jìn)行復(fù)制,使索引和搜索的跨區(qū)域部署更加容易。因此,如果一個(gè)地方發(fā)生故障,我們可以在另一個(gè)集群中處理請求。
索引是離線執(zhí)行的,不在用戶的關(guān)鍵路徑上。我們不需要同步復(fù)制索引操作。無需在將新索引復(fù)制到響應(yīng)搜索查詢之前等待。這使得搜索對用戶可用。
可擴(kuò)展性
分區(qū)是搜索系統(tǒng)擴(kuò)展的重要組成部分。當(dāng)增加分區(qū)的數(shù)量并向索引和搜索集群添加更多節(jié)點(diǎn)時(shí),可以在數(shù)據(jù)索引和查詢方面實(shí)現(xiàn)擴(kuò)展。
索引和搜索過程之間的強(qiáng)分離有助于索引和搜索獨(dú)立和動(dòng)態(tài)地?cái)U(kuò)展。
大數(shù)據(jù)快速搜索
我們利用了多個(gè)節(jié)點(diǎn),每個(gè)節(jié)點(diǎn)在較小的倒排索引上并行執(zhí)行搜索查詢。然后,將每個(gè)搜索節(jié)點(diǎn)的結(jié)果合并并返回給用戶。