火箭發射:一種有效輕量網絡訓練框架
原創摘要
像點擊率預估這樣的在線實時響應系統對響應時間要求非常嚴格,結構復雜,層數很深的深度模型不能很好的滿足嚴苛的響應時間的限制。為了獲得滿足響應時間限制的具有優良表現的模型,我們提出了一個新型框架:訓練階段,同時訓練繁簡兩個復雜度有明顯差異的網絡,簡單的網絡稱為輕量網絡(light net),復雜的網絡稱為助推器網絡(booster net),相比前者,有更強的學習能力。兩網絡共享部分參數,分別學習類別標記,此外,輕量網絡通過學習助推器的soft target來模仿助推器的學習過程,從而得到更好的訓練效果。測試階段,僅采用輕量網絡進行預測。我們的方法被稱作“火箭發射”系統。在公開數據集和阿里巴巴的在線展示廣告系統上,我們的方法在不提高在線響應時間的前提下,均提高了預測效果,展現了其在在線模型上應用的巨大價值。
研究背景
響應時間直接決定在線響應系統的效果和用戶體驗。比如在線展示廣告系統中,針對一個用戶,需要在幾ms內,對上百個候選廣告的點擊率進行預估。因此,如何在嚴苛的響應時間內,提高模型的在線預測效果,是工業界面臨的一個巨大問題。
已有方法介紹
目前有2種思路來解決模型響應時間的這個問題:
一方面,可以在固定模型結構和參數的情況下,用計算數值壓縮來降低inference時間,同時也有設計更精簡的模型以及更改模型計算方式的工作,如Mobile Net和ShuffleNet等工作;
另一方面,利用復雜的模型來輔助一個精簡模型的訓練,測試階段,利用學習好的小模型來進行推斷,如KD, MIMIC。這兩種方案并不沖突,在大多數情況下第二種方案可以通過第一種方案進一步降低inference時間,同時,考慮到相對于嚴苛的在線響應時間,我們有更自由的訓練時間,有能力訓練一個復雜的模型,所以我們采用第二種思路,來設計了我們的方法。
研究動機及創新性
火箭發射過程中,初始階段,助推器和飛行器一同前行,第二階段,助推器剝離,飛行器獨自前進。在我們的框架中,訓練階段,有繁簡兩個網絡一同訓練,復雜的網絡起到助推器的作用,通過參數共享和信息提供推動輕量網絡更好的訓練;在預測階段,助推器網絡脫離系統,輕量網絡獨自發揮作用,從而在不增加預測開銷的情況下,提高預測效果。整個過程與火箭發射類似,所以我們命名該系統為“火箭發射”。
訓練方式創新
我們框架的創新在于它新穎的訓練方式:
1. 繁簡兩個模型協同訓練,協同訓練有以下好處:
a) 一方面,縮短總的訓練時間:相比傳統teacer-student范式中,teacher網絡和student網絡先后分別訓練,我們的協同訓練過程減少了總的訓練時間,這對在線廣告系統這樣,每天獲得大量訓練數據,不斷更新模型的場景十分有用。
b) 另一方面,助推器網絡全程提供soft target信息給輕量網絡,從而達到指導輕量網絡整個求解過程的目的,使得我們的方法,相比傳統方法,獲得了更多的指導信息,從而取得更好的效果。
2. 采用梯度固定技術:
訓練階段,限制兩網絡soft target相近的loss,只用于輕量網絡的梯度更新,而不更新助推器網絡,從而使得助推器網絡不受輕量網絡的影響,只從真實標記中學習信息。這一技術,使得助推器網絡擁有更強的自由度來學習更好的模型,而助推器網絡效果的提升,也會提升輕量網絡的訓練效果。
結構創新
助推器網絡和輕量網絡共享部分層的參數,共享的參數可以根據網絡結構的變化而變化。一般情況下,兩網絡可以共享低層。在神經網絡中,低層可以用來學習信息表示,低層網絡的共享,可以幫助輕量網絡獲得更好的信息表示能力。
方法框架:
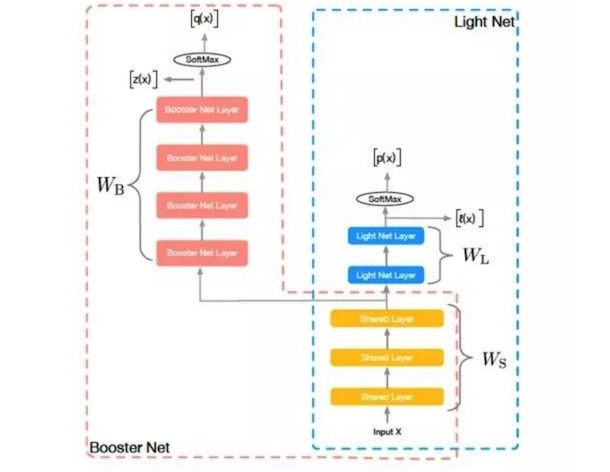
圖1:網絡結構
如圖1所示,訓練階段,我們同時學習兩個網絡:Light Net 和Booster Net, 兩個網絡共享部分信息。我們把大部分的模型理解為表示層學習和判別層學習,表示層學習的是對輸入信息做一些高階處理,而判別層則是和當前子task目標相關的學習,我們認為表示層的學習是可以共享的,如multi task learning中的思路。所以在我們的方法里,共享的信息為底層參數(如圖像領域的前幾個卷積層,NLP中的embedding), 這些底層參數能一定程度上反應了對輸入信息的基本刻畫。
整個訓練過程,網絡的loss如下:
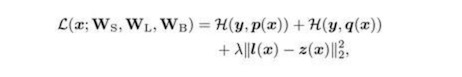
Loss包含三部分:第一項,為light net對ground truth的學習,第二項,為booster net對ground truth的學習,第三項,為兩個網絡softmax之前的logits的均方誤差(MSE),該項作為hint loss, 用來使兩個網絡學習得到的logits盡量相似。
Co-Training
兩個網絡一起訓練,從而booster net 會全程監督輕量網絡的學習,一定程度上,booster net指導了light net整個求解過程,這與一般的teacher-student 范式下,學習好大模型,僅用大模型固定的輸出作為soft target來監督小網絡的學習有著明顯區別,因為booster net的每一次迭代輸出 雖然不能保證對應一個和label非常接近的預測值,但是到達這個解之后有利于找到最終收斂的解 。
Hint Loss


Gradient Block

實驗結果
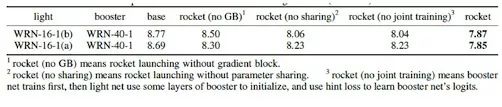
實驗方面,我們驗證了方法中各個子部分的必要性。同時在公開數據集上,我們還與幾個teacher-student方法進行對比,包括Knowledge Distillation(KD), Attention Transfer(AT)。為了與目前效果出色的AT進行公平比較,我們采用了和他們一致的網絡結構寬殘差網絡(WRN)。實驗網絡結構如下:
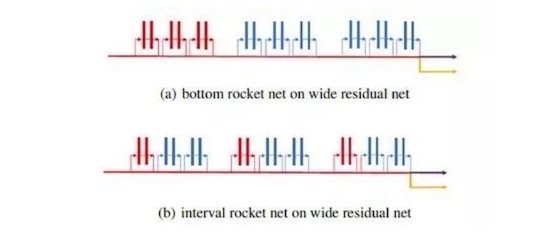
圖2:實驗所用網絡結構
紅色+黃色表示light net, 藍色+紅色表示booster net。(a)表示兩個網絡共享最底層的block,符合我們一般的共享結構的設計。(b)表示兩網絡共享每個group最底層的block,該種共享方式和AT在每個group之后進行attention transfer的概念一致。
各創新點的效果
我們通過各種對比實驗,驗證了參數共享和梯度固定都能帶來效果的提升
各種LOSS效果比較

輕量網絡層數變化效果圖
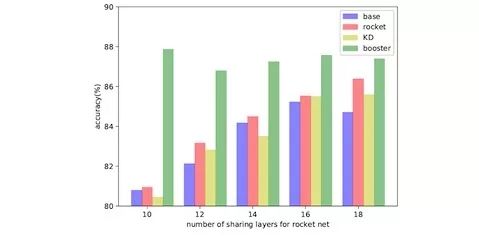
固定booster net, 改變light net的層數,rocket launching始終取得比KD要好的表現,這表明,light net始終能從booster net中獲取有價值的信息。
可視化效果
通過可視化實驗,我們觀察到,通過我們的方法,light net能學到booster net的底層group的特征表示。

公開數據集效果比較
除了自身方法效果的驗證,在公開數據集上,我們也進行了幾組實驗。
在CIFAR-10上, 我們嘗試不同的網絡結構和參數共享方式,我們的方法均顯著優于已有的teacher-student的方法。在多數實驗設置下,我們的方法疊加KD,效果會進一步提升
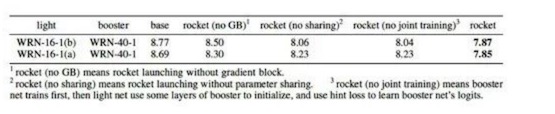
這里WRN-16-1,0.2M 表示wide residual net, 深度為16,寬度為1,參數量為0.2M.
同時在CIFAR-100和SVHN上,取得了同樣優異的表現

真實應用
同時,在阿里展示廣告數據集上,我們的方法,相比單純跑light net, 可以將GAUC提升0.3%.
我們的線上模型在后面的全連接層只要把參數量和深度同時調大,就能有一個提高,但是在線的時候有很大一部分的計算耗時消耗在全連接層(embedding 只是一個取操作,耗時隨參數量增加并不明顯),所以后端一個深而寬的模型直接上線壓力會比較大。表格里列出了我們的模型參數對比以及離線的效果對比:

總結
在線響應時間對在線系統至關重要。本文提出的火箭發射式訓練框架,在不提高預測時間的前提下,提高了模型的預測效果。為提高在線響應模型效果提供了新思路。目前Rocket Launching的框架為在線CTR預估系統弱化在線響應時間限制和模型結構復雜化的矛盾提供了可靠的解決方案,我們的技術可以做到在線計算被壓縮8倍的情況下性能不變。在日常可以減少我們的在線服務機器資源消耗,雙十一這種高峰流量場景更是保障算法技術不降級的可靠方案。
來源
《Rocket Launching: A Universal and Efficient Framework for Training Well-performing Light Net》
團隊名稱:阿里媽媽事業部
作者:周國睿、范穎、卞維杰、朱小強、蓋坤
完整版點擊:PDF