直擊京東新一代數據庫技術:如何實現極致彈性能力?
京東彈性數據庫不是一個單一的產品,而是京東在對數據庫的使用、運維和開發過程中遇到的一系列問題的解決方案和運維經驗的總結升華進而形成的一套產品系列。
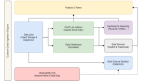
京東彈性數據庫主要包括三大功能模塊:
- 核心功能模塊:JED,提供數據查詢和寫入的自動路由、自動彈性伸縮、自動 FailOver、自動負載調度和數據庫服務智能自治的功能。
- 實時數據發布與訂閱模塊: BinLake,完全自助、無狀態、自動負載、完全自治、可橫向擴展的集群化 Binlog 采集和訂閱服務。
- 自動化運維模塊:DBS,實現了京東線上所有數據庫服務申請、DDL/DML上線、數據抽取等的流程化和自動化。
今天分為五個部分進行分享:
- 發展歷程
- 功能特性
- 整體架構
- 實現細節
- 使用情況
發展歷程
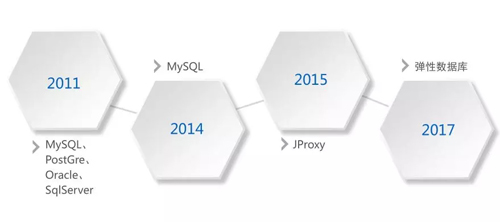
在 2011 年,我加入京東之初,京東的數據庫正處于諸侯混戰的階段,各種數據庫都有,包括:MySQL、PostGre、Oracle、SQL Sever。
在 2011 年之后,開始去 IOE,到了 2014 年,京東基本上完成了去 IOE,所有的業務系統都遷移到了 MySQL 上。
在大規模使用 MySQL 的過程中,我們發現,隨著業務數據量的增長,很多業務開始了漫長的分庫、分表之旅,起初各個業務系統在自己的業務代碼中維護分庫分表的路由規則。
而且各個業務系統的路由規則和整體設計都不一樣,后來由于人員更迭以至于業務代碼無法維護,不同業務使用的數據庫分庫分表模式不盡相同,導致數據庫的維護工作也難如登天。
這時我們開始重新思考應該提供什么樣的數據庫服務,得出了以下幾點:
- 統一分庫分表標準
- 路由針對業務透明
- 數據庫服務伸縮無感知
- 統一數據服務
- 業務研發自助申請服務
- 數據庫運維工作自動化
為了實現上述功能特點,我們分為兩步走:
- 優先解決業務和運維窘境,從而爭取足夠的時間和技術 buffer 進一步完善產品。
- 最終完美形態的產品研發。
因此,我們首先在 2015 年開發了 JProxy,優先解決緊急的業務和運維難題:分庫分表規則統一化和路由透明化。
在拿到充分的時間 buffer 后,我們從 2016 年開始以匠人的精神精雕細琢京東彈性數據庫。
功能特性
京東彈性數據庫是一個產品系列,主要是解決數據庫的運維、使用和研發過程中的問題,具備動態伸縮、高可用、查詢透明路由、集群化日志服務和自動化運維等功能,現就京東彈性數據庫三個核心模塊的功能進行詳細說明。
JED(JD Elastic DataBase)
JED 是 JProxy 功能的父集,它除了具備透明路由、統一分庫分表標準之外,還提供了五大功能,如下圖:

在線動態擴容
起初某個業務可能申請了 4 個分庫,后面隨著業務的發展,數據量越來越大,可能需要擴容到 8 個分庫。
一般的數據庫中間件在擴容時,需要與業務研發部門協商一個業務低谷期停業務,然后進行擴容,擴容完畢后重新啟動業務。
為了解決這個問題,JED 提供了在線動態擴容功能,擴容只會對業務造成秒級影響,且無需人工介入。
我們現在可以觸發自動擴容,設置的策略是當磁盤的使用率達到80%,就自動進行擴容。
自動 FailOver
Master 一旦出現宕機,哨兵檢測系統就會第一時間檢測到,會自動觸發注冊在哨兵檢測系統中的 Hook 程序。
Hook 程序就會選擇一個最新的 Slave 替換 Master,然后更新 ETCD 中的元數據信息,業務方的下一次請求就會發送到新的 Master 上。
兼容 MySQL 協議
JED 是完全兼容 MySQL 協議的,即通過 MySQL 的 Client 端或者標準的 JDBC Driver 都可以連接到 JED 的 Gate 層,然后進行查詢和計算。
多源數據遷移
我們基于 ghost 進行改造,開發了京東的數據傳輸和接入工具: JTransfer,實現了業務數據的動態遷移。
如果以前你的業務是運行在 MySQL 上的,現在要遷到 JED 上,你不需要停止任何業務,直接啟動 JTransfer 的數據遷移服務,就可以在后臺自動完成數據的同步和遷移。
遷移完畢后,JTransfer 會自行比對 JED 上的數據與原來數據的一致性和 lag 計算。
當數據完全一致, 且 lag 小于 5 秒時,就會郵件通知業務方進行復驗,復驗沒有問題,業務方直接將數據庫連接指向到 JED 就可以正常提供服務了。
數據庫審計
JED 具有數據庫審計的功能,該功能實現在 Gate 層,在 Gate 層我們會得到應用發送給 JED 的所有 SQL,然后將 SQL 語句或者 SQL 模板發送給 MQ。
由于是在 Gate 層實現的,而 Gate 層與 MySQL 服務不在一個容器上,因此對 MySQL 服務不會產生任何的負面影響。
BinLake
BinLake 只做一樣工作:集群化 Binlog 的采集和訂閱服務。
在 BinLake 之前,我們使用 Canal 進行 Binlog 采集,但我們發現存在資源浪費等問題:若一個業務需要采集 MySQL Binlog,并且還需要 HA 保證的話,我們至少需要兩臺服務器。
那多個業務怎么辦?于是我們開發了 BinLake,其功能特性如下:

無狀態集群化 BinLog 采集
BinLake 是一個集群化的 BinLog 采集和訂閱服務,并且與常規意義上的集群不一樣,我們的集群是沒有 Master 節點的。
而且集群中的所有工作節點都是完全平等的,這也就意味著,只要集群中的節點沒有全部宕機,BinLake 集群可以一直提供服務。
高可用與自動故障轉移
針對于某個 Mya 實例的采集 instance(每個 instance 代表一個線程)一旦掛掉,會在集群中的負載最低的工作節點上重新啟動一個 instance,繼續從上次掛掉的 Offset 進行采集,不會造成 BinLog 的丟失和重復。
負載自動均衡
假設所有 BinLog 的集群有八個節點,其中有七個節點的負載比較高。
當你在接入 BinLog 時,在沒有人工介入的衡量下,整個集群將以新接入的一個 instance 采集實例,自動選擇一個健康度最高的 Wave 服務,然后啟動 BinLog 采集。
支持多種 MQ
BinLake 采集到的所有 Binlog 的 event 會被封裝成 Message 發送給 MQ,目前我們支持 JMQ 和 Kafka 兩種 MQ 產品。
支持集群橫向擴容
當 BinLake 集群的服務能力達到了瓶頸,我們可以簡單地將新的工作節點啟動,只需要在新的工作節點配置文件中配置上與線上的工作節點相同的 ZooKeeper 路徑,新的工作節點就會自動加入到已存在的 BinLake 集群中。
DBS
DBS 主要完成自動化運維的工作。它可以完成數據庫服務的自動化交付、數據庫操作的流程化管理、數據庫健康指數全面監控、數據庫自動備份及結轉,以及調度作業的多樣化調度(包括定時、依賴以及觸發三種調度模式)。

整體架構
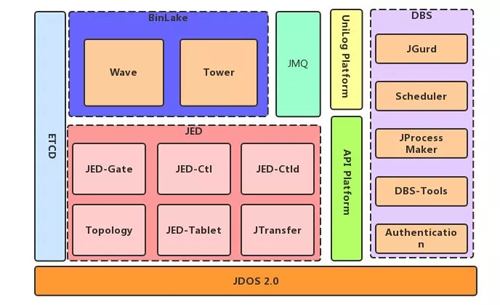
如上圖是京東數據庫的一個整體架構圖,最底層是 JDOS2.0,JDOS 2.0 是京東新一代的容器技術,是 Docker 的管理平臺。
實際上京東所有的數據庫服務現在已經完全運行在 Docker 之上了,這一點是讓我們比較引以為豪的工作成績,而這些都離不開京東 JDOS 的底層支持。
JED 包括六大組件:
- JED-Gate:實現分庫分表的透明化路由和審計功能。
- JED-Ctl:命令行控制工具。
- JED-Ctld:也提供集群控制功能,但是它是以服務的方式提供 API 接口。
- Topology:是整個 JED 的元數據管理中心,所有的元數據是通過 Topology 進行管理的。
- JED –Tablet:是每一個 MySQL 前端的 Proxy,提供 MySQL 查詢緩存和流復制等。
- JTransfer:在線數據遷移和接入工具。
BinLake 的服務角色比較簡單,只有兩種服務:Wave 和 Tower。
BinLake 整個集群是完全無狀態的。我們所知道的大部分集群化服務都是有狀態集群和不對等集群。
所謂不對等集群就是集群里要有 Master 服務角色,負責整個集群的管理;還要有 Worker 服務角色,負責實際任務的執行。
但整個 BinLake 是沒有任何 Master 的,只有一種服務角色:Wave,就是你的工作節點。Tower 只是一個可以與集群進行交互式操作的 HTTP 服務。
Tower 與傳統 Master 節點的不同之處在于:它不負責任何元數據的管理,它只是向 Topology 服務發送命令,更新或者獲取存儲在 ETCD 或 ZooKeeper 中的元數據信息。
DBS 是構建于我們的 API Platform 之上的,API Platform 是我們自己開發的一個簡單 Faas 平臺。
有了 API Platform,在京東只要是會寫代碼的人,不管你用何種開發語言,只要是滿足 Restful 協議的服務,都可以注冊到 API Platform 中,并不斷豐富 DBS。
DBS 包括幾個核心模塊:
- JGurd 是一個分布式檢測系統,它提供了對 MySQL 服務的完全分布式檢測,避免了因為網絡抖動而產生對 MySQL 健康狀況的誤判。
- Scheduler 是調度平臺,是基于 Oozie 改造開發的集群調度平臺。
- JProcess Maker 是 DBS 的流程引擎。
- DBS-Tools 是我們在數據庫運維過程中需要用到的一些數據庫工具,比如說 AWS 報告、監控工具、Master 切換工具、域名漂移工具等。
- Authentication 是京東內部的身份認證和權限控制組件。
下面我們針對 JED、BinLake 和 DBS 的架構進行詳細講解。
JED
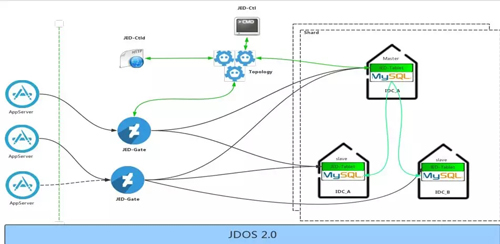
JED 的前端是 AppServer,從整體架構上,JED 和 AppServer 直接打交道的只有一個角色,就是 JED-Gate。
JED-Gate 完全兼容 MySQL 協議,AppServer 可以將一些查詢語句發送給 JED-Gate。
JED-Gate 層對所有查詢的查詢執行計劃都會做緩存,并且根據查詢執行計劃,通過 Topology 服務獲得查詢所涉及表的路由源數據信息,根據元數據信息將查詢語句改寫或者拆分發送到底層的 Shard 上去。
目前 JED 已經滿足了廣域分布架構,實現了異地多活。
BinLake
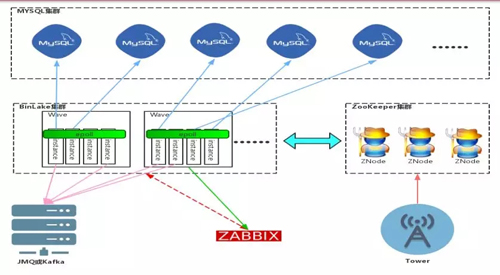
針對上圖的 BinLake 架構圖,可以看到 BinLake 集群中的每個工作節點叫做 Wave。
每個 Wave 節點上有多個 instance,這個 instance 就是針對于每個 MySQL 實例的 Binlog 采集線程,在同一個 Wave 實例上的多個 instance 實例通過 Epoll 模型實現高效網絡監聽和通訊。
當用戶新采集一個 MySQL 的 Binlog 或者某個 instance 線程掛掉了,會根據當前集群中各個 Wave 服務的健康狀況選擇一個健康度最高的 Wave 實例,去實例化這個新的 instance 線程。
而每個 Wave 實例上的健康度是根據 Zabbix 的監控數據進行動態計算的。
從圖中可以看到,Tower 服務其實沒有跟 Wave 服務做任何直接的通訊或者聯系。
Tower 只會跟 ZK 或 ETCD 集群直接做交互,它對 ZK 或者 ETCD 集群任何元數據的更改都被 Wave 服務及時發現,發現之后,Wave 服務會采取一系列相應的措施,來對元數據的更改進行響應。
DBS
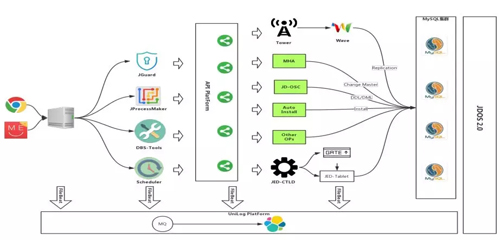
DBS 依賴于兩個基礎的服務進行構建,第一個是 API Platform,第二個是 JDOS。
通過 API Platform 實現 DBS 整個系統所有功能模塊的完全解耦,因為所有的底層操作都是單獨開發的符合 Restful 標準的 HTTP 服務,并通過 API Platform 暴露出來。
不管是研發人員還是 DBA,無論使用什么樣的開發語言,只要能夠開發出符合 Restful 的 HTTP 服務,就可以將其注冊到 API Platform 上,并實現 DBS 系統中特定的功能。
無論是 JGuard、JProcessMaker、DBS-Tools 還是 Scheduler,它們做的所有工作都只有一樣:調用 API Platform 上所暴露的接口。
API Platform 會根據你的注冊信息,去調用 Tower 暴露的 API 接口,或者是調用 MHA 的一些腳本或者其他接口。
另外,不管是 DBS 的應用服務器、MySQL 服務器、API Platform,后端寫的所有接口,我們都會采集這些服務上的所有日志,采集了之后接入到 Unilog Platform,用于后續的日志的審計和檢查。
實現細節
由于京東彈性數據庫包含的功能和組件很多,下面我選出幾個特定的功能,在實現細節上詳細說明。
動態在線擴容
Step 1:創建兩個目標 Shard
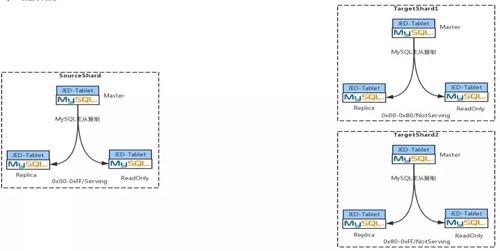
假設某個業務方在 JED 中起初申請了一個 Shard,這個 Shard 大家可以把它簡單地想象成是一套 MySQL 集群,這時我要將它擴容成兩個 Shard。
假設現在有一萬條記錄,要擴成兩個 Shard,那么每個目標 Shard 里面就有 5000 條。
在 JED 里,在觸發擴容這個動作時,首先會通過 JDOS 接口,將目標 Shard 的所有 POD 都創建并啟動起來。
如果每個目標 Shard 都是 1 主 2 從,總共會啟動 6 個POD,12 個 Container(一個 POD 中有 2 個 Container,1 個 Container 中是 Tablet 服務,1 個 Container 是 MySQL 服務)。
然后每個 POD 都是 Not Sevring 狀態,其中每三個 POD 實例組成一個 Target shard。
可以看到,Source Shard 中的 sharding key 對應的 key range 是:0x00-OxFF,這里的 KeyRange 也就是你的 sharding key 經過哈希之后能夠落到多大的范圍。
現在要將一個 Source Shard 分為兩個 Target Shard,所以 Source Target 對應的 Key Range 也就要一分為二。
可以看到兩個 Target Shard 對應的 KeyRange 是 0x00-Ox80,Ox80-Oxff,并且是 Not Serving 狀態。
Step 2:全量數據過濾克隆
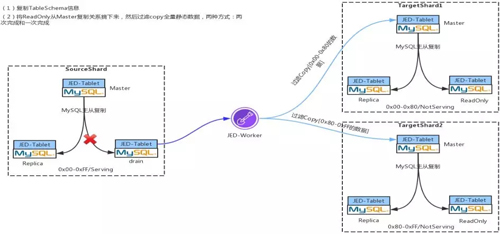
兩個 Target Shard 建立之后,會根據 ETCD 里的默認配置針對每個 Target Shard 建立 MySQL 的復制關系,比如:
- 一主兩從:一個 Master,一個 Replication,一個 ReadOnly。
- 一主三從,一個 Master,兩個 Replication,一個 Readonly。
- 一主四從,一個 Master,兩個 Replication 和兩個 ReadOnly。
建立完復制關系之后,首先會通過 JED-Worker 將 Source Shard 中的 Schema 信息復制到兩個 TargetShard 中。
然后將 Source Shard 中的 ReadOnly Pod 從 MySQL 復制關系中摘除下來。
最后通過 JED-Worker 將 ReadOnly 中的數據過濾拷貝到兩個 TargetShard 中。
Step 3:增量數據過濾到兩個目標 Shard
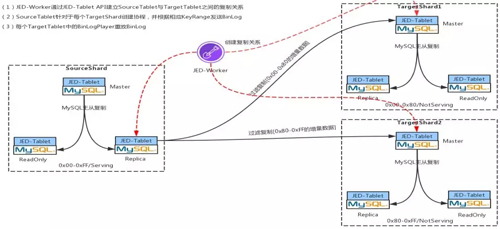
現在我們以最簡單的一拖二的方式來講述。當你的兩個 TargetShard 建立完成后,你要做的就是先把你的這一萬行記錄拷到兩個 shard 上,拷完之后去建立過濾復制。
完成了 Step2 的過濾拷貝之后,將 ReadOnly 重新掛到 Source Shard 上。
然后 JED-Worker 通過 Replication 中的接口創建 Binlog 的過濾復制,會在 Replication 上啟動兩個協程,并根據 TargetShard 的 KeyRange 分別將 Binlog 復制到對應的 TargetShard 上。
Step 4:數據一致性校驗
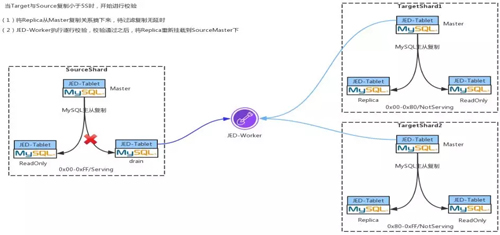
當 TargetShard 中的 Binglog 與 SourceShard 中的 Binlog 的 lag 小于 5 秒的時候,會啟動數據的一致性校驗,該過程是在 JED-Worker 上完成的。
過程很簡單,就是通過大量的后臺協程 Target 和 Source 上去取出數據一條一條對比,如果數據的一致性校驗通過,就開始進行 Shard 切換。
Step 5:切 Shard
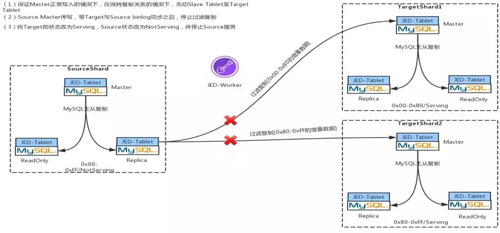
首先將 SourceShard 中 Slave 的 Serving 狀態切換成 Not Serving,同時將 TargetShard 中 Slave 的 Not Serving 狀態更改為 Serving。
最后將 Source 中的 Master 停寫,等 Target 中的 Master 與 Source 中的 Master 無復制延時后,將 Source Master 停寫,通過 JED-Worker 將過濾復制斷掉,然后將 Target 的 Master 置為 Serving 狀態,并接受寫入。
上述的所有 Serving 與 Not Serving 狀態的改變均是通過改變 ETCD 中的元數據來完成的。
當前端性業務再發送新的查詢過來時,Gate 就會根據最新的元數據信息,將你的這條 SQL 發送到最新的 TargetShard。
自動 FailOver
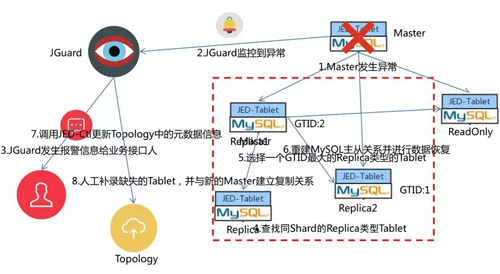
以 1 主 3 從的 MySQL 主從架構對 JED 的自動 FailOver 機制進行說明。
如果 Master 發生異常,JGuard 會通過分布式檢測(JGuard 是通過 ORC 改造之后形成的一個分支檢測服務)檢測異常。
檢測到異常之后會通過郵件和短信通知業務接口人,通知完之后,不會等業務接口人進行處理,直接從當前整個 MySQL 集群當中選擇一個 GTID 最大的一個 MySQL 實例,將這個 MySQL 實例切成 Master。
然后根據新的 Master 重建新 MySQL 主從復制關系,將剩余的 Replication 和 ReadOnly 重新掛載到新的 Master 上,再調用 JED-Ctrld 服務的接口更新 ETCD 中的元數據。
這樣后續的 DDL/DML 就會發到最新的 Master 之上,最后缺失的一個 Tablet 需要人工補入。
Streaming Process
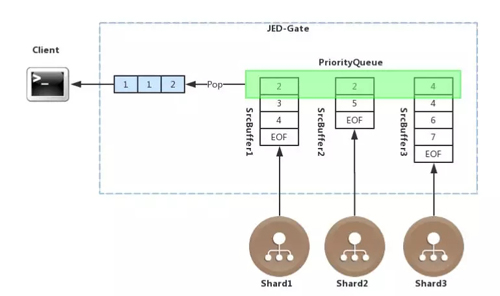
JED 實現了查詢的流式處理,以查詢語句 select table_a.age from table_a order by table_a.age 為例說明流式處理的過程。
JED-Gate 接收到該查詢語句之后,會根據 ETCD 中的分片元數據,將該語句分發到三個 Shard 中,各個 Shard 返回給 JED-Gate 數據本身就是有序的。
在 JED-Gate 中針對每個 Shard 都會有一個 buffer 與之對應,每個 buffer 用來流式的接收每個 Shard 返回的排序完畢的數據,因此該 buffer 中的數據也是有序的。
然后將每個 buffer 的首地址存儲到一個 PriorityQueue 里面, PriorityQueue 是一個堆排序的優先級隊列,會根據每個 buffer 中的首元素不斷的進行排序。
每從 PriorityQueue 中取出一個元素,PriorityQueue 都會調整 buffer 的先后順序,JED-Gate 會將元數一個一個地取出來,以流式的方式發給前端,從而實現整體流式排序。
Join 處理
現在我們看下如何在 JED 上執行 Join 查詢的,在下面所有的說明中,我們都有一個假設條件,就是所有的表的 sharding key 都是 ID。
對 Join 查詢的處理,要分情況:
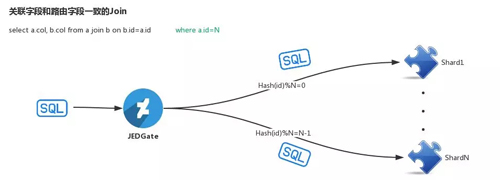
第一種情況:Join Key 與 Sharding Key 相同。
這種情況下由于 Join Key 和 Sharding Key 是完全相同的,因此是可以將 Join 查詢語句直接發送到下面的每個 shard,在 JED-Gate 匯聚各個 shard 的部分查詢結果,并返回給前端應用。
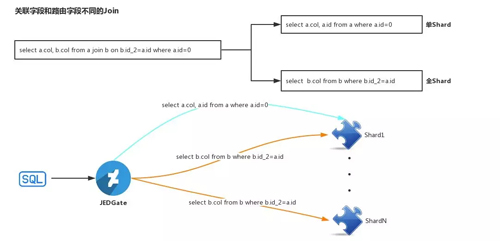
第二種情況:Join Key 與 Sharding Key 相同。
如上圖所示,比如 Select a.col,b.col.from a join b on b.id_2=a.id where a.id=0。
針對該查詢語句,JED-Gate 首先對其進行 SQL 語句改寫,改寫為兩條語句:
- select a.col,a.id from a where a.id=0
- select b.col from b where b.id_2=a.id
在第二個查詢語句中的 a.id 是綁定變量。JED-Gate 會首先根據 select a.col,a.id from a where a.id=0,定位到該 SQL 需要定位到哪個 shard,將 SQL 發送到相應的 Shard 執行,并流式的獲取其結果。
然后將結果中的 a.id 字段的值取出,并將值賦給 select b.col from b where b.id_2=a.id 語句中的綁定變量 a.id,將復制后的第二條 SQL 語句依次發送給所有的 shard,并將結果與第一條 SQL 語句中的結果組合,流式地返回給前端。
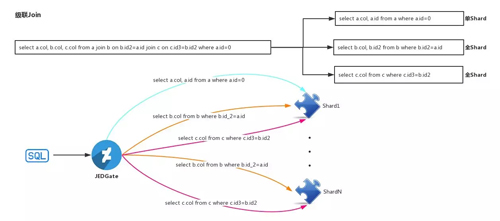
當多級 Join 的時候,也是相同的思路,這里不再贅述。
BinLake 元數據架構圖
前面已經提到 BinLake 有一個很大的特點:一個完全無狀態的集群,沒有 Master 管理節點,而要實現這個特性最重要的就是要有合理的元數據設計。
之所以沒有 Master 節點,是因為把 Master 節點的功能委托給了 ZooKeeper 或 ETCD。
通過借助 ZooKeeper 中的 ephemeral znode 實現了 Wave 服務乃至 instance 的自動發現和 HA,并最終實現了無 Master,無狀態的完全對等集群。
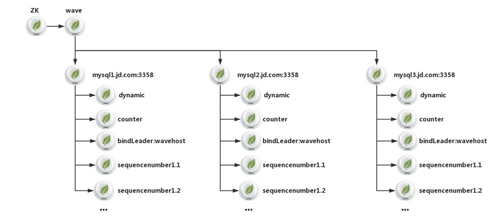
根據上面的元數據架構我們對 BinLake 的所有元數據進行詳細說明。
一個 BinLake 集群的 root znode 是一個名為 wave 的 znode,在 wave 之下是一系列的形式為:MySQL 域名命名:port 的 znode。
這樣的每個 znode 都對應了一個 MySQL 實例,而在每個 MySQL 實例對應的 znode 下面是該 MySQL 實例的管理、信息保存和選舉 znode。
其中 counter 節點中記錄了當前 MySQL 實例對應的 instanc 重啟了幾次,若連續重啟超過 7 次,就會發出報警信息。
而 dynamic 節點則記錄了每個 MySQL 實例對應的 Binlog 采集線程對應的快照信息包括:當前采集到的 Binlog 文件、Offset、Timestamp、GTID、最近的 10 個時間點 Binglog 位置和 Filter Rules 等。
從而保證 instance 重啟后,可以利用這些信息繼續進行 Binlog 采集。
后面的 sequencenumber 對應的一系列 znode 是由 Curator 自動創建的 znode,來保證選舉的正確性和防止羊群效應。
而“Bingdleader:wavehost”對應的 znode,主要用于人工介入 binlake,從而指定讓下次 instance leader 選舉的時候,固定在 wavehost 對應的 Wave 節點上。
如果我某個 MySQL 采集的 instance 掛了,Curator 就會在后面的第一個 znode 對應的 wave 服務上首先進行 leader 選舉。
若成功選舉,就接入,否則依次對后面對應的每個 Wave 實例進行選舉,直到成功選舉出 leader。
選舉出新的 leader 之后,就會在對應的 Wave 服務上重啟 Binlog 采集的 instance 線程,該 instance 就會根據 dynamic znode 中存儲的快照信息重建 MySQL 的復制關系,繼續進行 Binlog 采集。
集群化 Binlog 訂閱
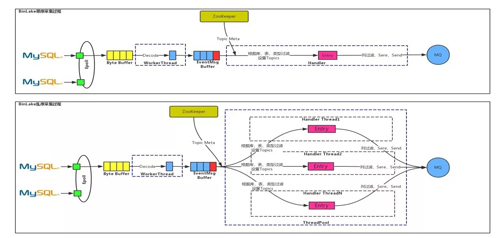
BinLake 中的 Binlog 采集方式有兩種:
- 時序
- 亂序
時序:通過 NIO 實現的類似 Epoll 的網絡模型監聽所有與 MySQL 之間的鏈接的網絡事件等,檢測到與某個 MySQL 之間的連接有 byte 流到達時,就會盡量多的讀取所有的 byte 流。
將其全部放到一個 Byte Buffer 里,然后通過 Worker Thread 對 ByteBuffer 中的 Byte 進行 Decode,并解析成一個個的 EventMsg,進而將 EventMsg 也放到一個 MessageBuffer 中。
在 MessageBuffer 后面有一個 Handler 線程,這個 Handler 線程會根據 ZooKeeper 里的一些元數據信息(比如:Topics、FilterRules、MQ 類型和地址等)對 EventMessage 進行處理。
然后使用 protobuff 進行序列化后發送到正確 MQ 中的特定的 Topic 里。這里的處理包括:根據庫表類型過濾、列過濾、事務頭 Event 和尾 Event 過濾等。
亂序:從上圖中可以看出亂序處理與時序處理的前半部分是相同的,只是在 EventMessage Buffer 后面是通過線程池進行并發處理的,測試結果表明亂序處理的性能是時序處理性能的 10 倍。
落地使用
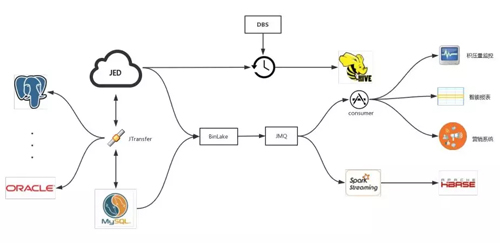
從上圖可以看出,JED 數據庫中間件服務通過 JTransfer 來實現 MySQL 和 JED 之間的數據正反向同步和傳輸。
現在 JED 可以實現 MySQL 向 Oracle、Postgre 等多種數據庫的實時數據同步和傳輸。
BinLake 可以對 MySQL 和 JED 中的 Binlog 進行采集,并發送到 JMQ 或者 Kafka。
在 MQ 后端有兩種使用方式:
- 通過 Spark Streaming 把它同步到 HBase 里,目前京東內部實際上是有一個項目叫做實時數據快照,就是通過這種方式,實現了 HBase 中的數據與線上 MySQL 實例中的數據的完全實時同步更新。
- 下游各個業務部門各自通過 Consumer 消費,進而進行訂單積壓監控、智能報表以及營銷實時推薦等。當然 JED 以及 BinLake、Jtransfer 都是通過 DBS 進行自動化運維、調度和管理的。
京東彈性數據庫落地狀況
這些是在 9 月份從 DBS 系統里面拿到的數據,服務線上業務是指上線項目的個數。
目前京東彈性數據庫服務了線上 3122 個項目,管理的 MySQL 實例個數有將近兩萬個,管理的 Table 就比較多了,有 660 多萬個,并且完成了自動在線切換 2700 余次,自動化上線有 27000 余次。
現在京東有一般的業務都遷到了 JED 上,當然還有一半的業務正在容器化的 MySQL 服務上并逐步地進行遷移。
分片數與 OPS、延時的關系情況
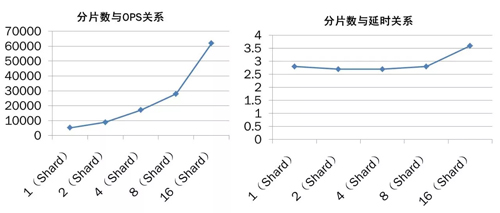
上圖是 JED 的分片數與 OPS 以及分片數延時的一些關系。從圖中可以看出,隨著分片數的增加 JED 的服務能力也出現線性增長的趨勢。而隨著分片數的增加延時幾乎沒有變化(延時的單位是毫秒)。
Gate 數與 OPS、延時的關系情況
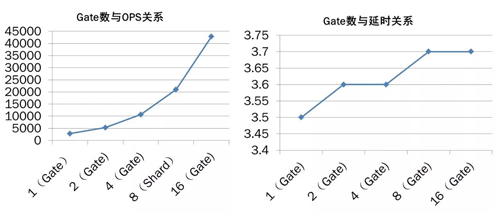
上圖是 Gate 數目與 OPS 以及 Gate 數目與延時的關系。從圖中可以看出,通過簡單的增加 Gate 的數目而實現 JED 數據庫服務能力的橫向擴展,不會導致明顯的延時增加。
呂信,京東商城數據庫技術部資深架構師,擁有多年數據產品研發及架構經驗。在京東及國內主導多種數據產品開發及社區建設,積極活躍于數據產品領域,對數據庫及大數據領域各個產品具有豐富經驗,目前在京東商城主導彈性數據庫研發及推廣使用。