如何通過機器學習還原圖像色彩
在本文中,作者提出了使用k-means算法來對圖像進行色彩還原,介紹算法的步驟,同時應用在圖像上,通過對比還原前后的圖像,來證明k-means算法的有效性。
k-means是機器學習中***、最廣泛使用的算法之一。在這篇文章中,將使用k-means算法來減少圖像上的顏色(但不減少像素),從而也減少了圖像的大小。在這個領域不需要任何基礎知識,因為可執行應用程序文件(大小為150MB,這是由于長時間的Spark依賴)已經提供了友好的用戶界面。所以你可以很容易地用不同的圖像來做實驗。在GitHub上有完整可用的執行代碼。
K-Means 算法
k-mean算法是一種非監督型學習算法,將相似的數據分成不同的類別或集群。它是無監督型算法,因為數據沒有被標記,而且算法不需要對相似數據進行分類的反饋(可能是預期類別的數量——稍后再討論)。
應用
k- means算法的一些應用包括客戶服務、集群計算、社交網絡和天文數據分析。
客戶服務
假設有大量與客戶相關的數據,并且希望更多地了解所擁有的客戶類型,從而可以更好地為特定群體服務。也許你要生產牛仔褲和t恤,所以你需要在一個特定的國家將人以身材大小進行分組,這樣你就能知道生產什么尺寸更合適。
集群計算
從性能角度來看,將某些計算機分組在一起比較好;例如,從網絡的角度來看,交換機適合聚集在一起工作,或者提供相似的計算服務。K-means算法可以將相似功能的計算機分在一組,這樣就可以進行更好的布局和優化。
社交網絡
在社交網絡中,你可以通過客戶關系、偏好、相似性等來對他們進行分組,并從營銷的角度更好地對客戶進行定位。基于提供的數據的輸入,k-means算法可以幫助我們從不同的角度對相同的數據進行分類。
天文數據分析
k-means也用于了解星系的形成,以及在天文數據中尋找內聚性。
它是如何工作的
k-means算法有兩個步驟。假設把數據分成四組,執行以下步驟。
注意:在開始任何步驟之前,k-means算法會從數據中隨機抽取三個樣本,稱為聚類中心。
- 它檢查每一個數據樣本,會根據它們與開始隨機選擇的聚類中心的相似程度,來對它們進行分類。
- 它使聚類中心與相似的同類點更接近(第1步的分組)。
重復這些步驟,直到聚類中心沒有顯著的移動。下面使用簡單數據進行算法執行。
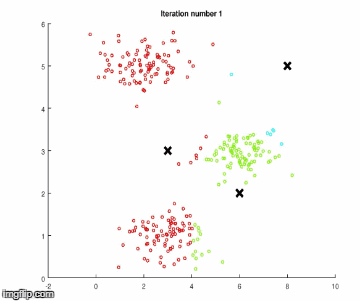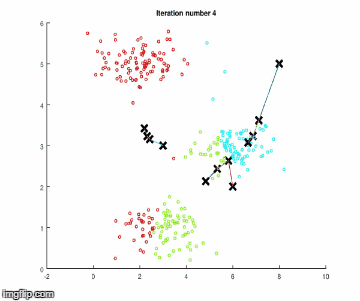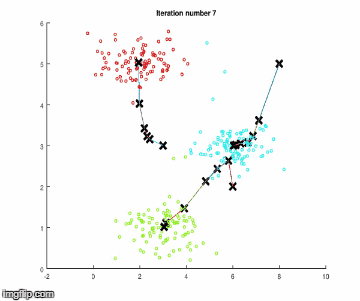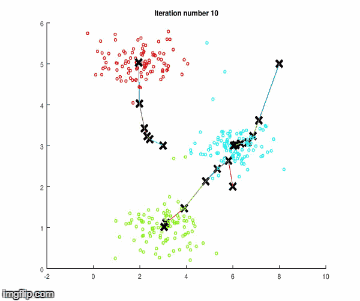
步驟1
現在繼續解釋步驟1是如何實現的。如果你不熟悉多維特性數據。首先來介紹一些變量:
k:集群的數量
Xij:示例i的第j個特征值
μij:示例i的第j個特征的聚類中心(類似于X,因為聚類中心是隨機選擇的)
在這個步驟中,通過迭代,計算它們與聚類中心的相似度,并將它們放入合適的類別中。更確切地說,這是通過一個樣本的歐幾里得距離來計算的,并從最微小的距離中選取中心。由于中心點是隨機選擇的,因此將所有特征點與中心點的歐幾里德距離相加。
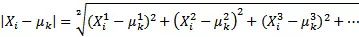
或者,更簡化,計算量更少:
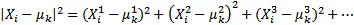
步驟2
從圖上看,這一步將中心點向步驟1中相似的分組進行移動。更準確地說,就是取所有與中心點相似或屬于該分組的點的平均值(步驟1的分組),來計算每個中心的新位置。
例如,如果有4個集群和第1步驟之后的103個示例,那么有以下結果:
μ1 = 20表示標號1-20示例的特征中心是20
μ2=10 表示標號21-31示例的特征中心是10
μ3=30表示標號32-62示例的特征中心是30
μ4=40 表示標號63-103示例的特征中心是40
新的計算方法如下:
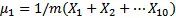
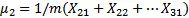
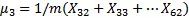
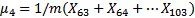
這是所有數據的平均值,類似于一個特定的中心。
重復,重復,重復…何時停止?
重復第1步和第2步,直到如圖形上顯示的,中心向數據集群移動的越來越近,才會得出新的中心。該算法會一直運行,直到對結果滿意時,就需要明確地告訴它,這樣它就可以停止了。一種方法是,當迭代時,中心體不會在圖中移動,或者它的移動非常少。形式上說,可以計算成本函數,這基本上就是在步驟1中所計算的平均值:
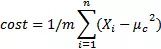
μc是Xi的中心值。每個示例都可以是不同組或中心的一部分。每次迭代成本都會與之前的成本相比較,如果變化真的很低,就停止它。例如,如果改進(成本函數的差異)是0.00001(或者其他認為合適的值),那就可以停止了,因為繼續下去就沒有意義了。
算法會出錯嗎?
通常不會出錯,但眾所周知,k-means算法僅能達到局部***,而不是全局***。在這種情況下,k-means算法無法發現更加明顯的分組,如下圖所示:
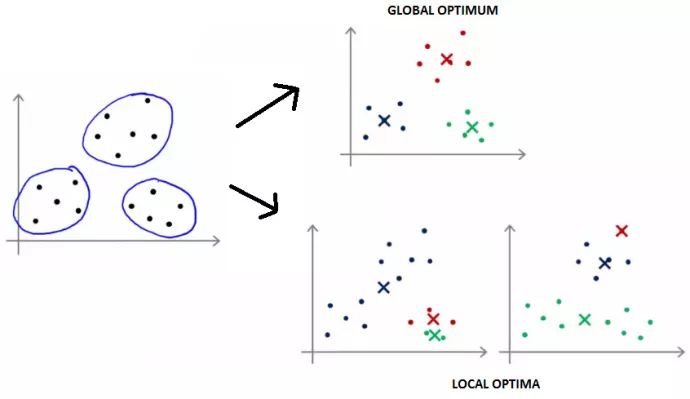
幸運的是,解決方案相當簡單——只要用k-means算法多運行幾次,然后選擇***的結果就好了。這個解決方案很有幫助,因為在一開始,隨機初始化k-means算法,比方說,運行10次,那么會得出局部***解。當然,這增加了運行時間,因為它運行了很多次,卻只需要一個結果。另一方面,完全可以在并行的甚至是不同的集群上運行算法,所以通常可以作為一個工作解決方案。
當然,k-means算法比我所介紹的要多,所以強烈推薦這篇文章,以獲得更深入的見解。
算法的執行和結果
在本節中,將運行應用程序(也可以下載代碼),并通過一些細節來了解k-means算法如何進行色彩還原。
色彩還原
需要說明的是,k-means算法不是減少圖像上的像素,而是通過將相似的顏色組合在一起,以此來減少圖像的顏色數量。一個正常的圖像通常有幾千個甚至更多的顏色,所以減少顏色的數量可以顯著減少文件的大小。
為了說明減少顏色的數量有助于減少圖像大小,來看一個例子。假設有一個1280x1024像素的圖像,對于每個像素,有一個簡單的顏色表示(RGB 24位,8位紅,8位綠色,8位藍色)。總而言之,需要1280 * 1024 * 24 = 31457280位或30MB來表示圖像。現在,把整體顏色減到16種,這意味著不需要24位像素,而是4位來代表16種顏色。現在,有1280 * 1024 * 4 = 5MB,這也就少占了6倍的內存。當然了,圖像看起來不會像之前那樣***(現在只有16種顏色),但肯定能找到一個合適的圖像。
執行和結果
執行算法的最簡單方法是下載JAR包,并使用自己的圖像來執行(需要安裝Java)。我的電腦大約需要花一分鐘的時間來運行,使顏色減少到16種(高CPU和內存會更好,因為Spark是并行運行的)。在用戶界面中,可以選擇想要嘗試的圖像文件,也可以選擇減少圖像上顏色的數量。下面是一個用戶界面和結果的例子:
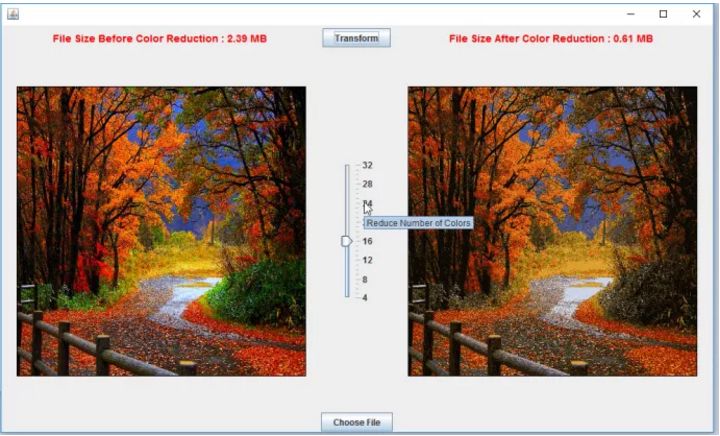
可以注意到,文件大小減少了4倍,但最終的圖像看起來并不是那么糟糕。多運行幾次它可能會帶來更好的效果。再試試24種顏色:
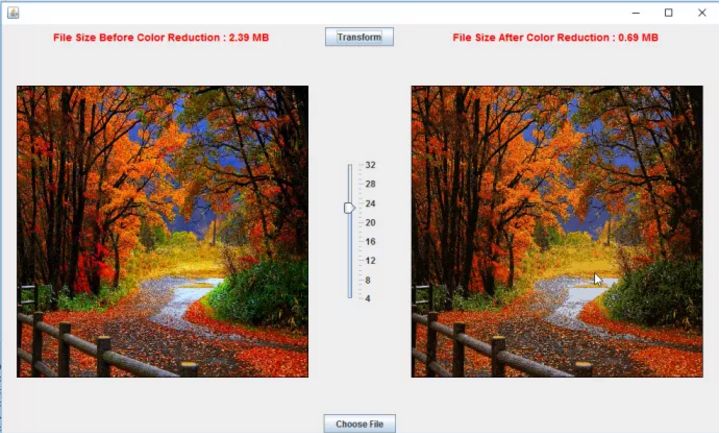
這看起來明顯好一些,尺寸也沒有增加多少(只有0.08 MB)。似乎在24到28之間是這個圖像***的視覺效果。
盡管結果看起來不錯,但選擇***圖像是一項手工任務。畢竟,我們正在執行和挑選最適合視覺的圖像。
相信這個問題可以用多種方法來解決。
其中一個解決方案是簡單地計算原始圖像上的所有顏色,并在此基礎上,定義用于圖像的顏色數量,同時仍然保持圖像看起來不錯。這一過程可以通過使用像線性回歸這樣的機器學習預測算法來完成。通過賦予圖像不同的顏色來訓練算法,同時,對于每個圖像來說,它們看起來仍然很好。在給出了一些重要的示例之后,該算法根據不同的圖像學習了如何減少到***顏色數量。現在是時候讓線性回歸算法預測下一個圖像的顏色會減少多少了。
可以下載代碼(https://github.com/klevis/KMeansImageColorReduction)并在Java IDE上運行它。當然,如果不想在源代碼中運行,只需下載代碼并運行maven:mvn clean install exec:java。