













機器學習如何優化策略游戲
為營造積極的游戲體驗,游戲設計者通常會反復調整游戲中的平衡性:
- 通過測試用戶成千上萬次的游戲會話進行壓力測試
- 整合反饋,重新設計游戲
- 重復步驟 1 和 2,直到游戲測試人員和設計者都滿意為止
這個過程不僅耗時,而且明顯存在不足:游戲越復雜,細微的缺陷就越容易被忽視。當游戲中有多個可供扮演的角色和大量相互關聯的技能時,要達到平衡便更為困難。
今天,我們將介紹一種機器學習 (ML) 方法:訓練模型充當游戲測試人員來調整游戲平衡,并在數字卡牌游戲原型 Chimera 上演示這種方法。先前,我們也用相同的測試平臺演示了 ML 生成的藝術。這種基于 ML 的游戲測試方法使用訓練好的智能體 (Agent) 通過數百萬次模擬收集數據,讓游戲設計者可以更高效地將游戲打造得更有趣、更平衡的同時也符合設計預期。
Chimera
https://www.youtube.com/watch?v=hMWjerCqRFA&t=239s
Chimera
我們開發的 Chimera 是一個游戲原型,在開發過程中依賴了大量的機器學習。對于游戲本身,我們有針對性地設計了規則,擴大了可能性空間,使得很難通過傳統的人工構建的 AI 來進行游戲。
Chimera 的玩法圍繞奇美拉(Chimera,神話生物)展開,這些生物混合體將由玩家強化和進化。游戲的目標是打敗對手的奇美拉。游戲設計中的關鍵點如下:
- 玩家可以:
- 操控生物,可發出攻擊(使用攻擊統計,attack stat)或受到攻擊(減少生命統計,health stat);
- 使用法術,產生特殊效果。
- 生物被召喚到容量有限的生物群系,實際放置于牌桌空間。每個生物都有對應的偏好生物群系,如果被放置于不正確的生物群系或超出容量的生物群系則會受到重復傷害。
- 玩家控制的是一只奇美拉,奇美拉最開始處于基本的“蛋”狀態,通過吸收生物來進化和強化。為此,玩家還必須通過各種游戲機制獲得一定的鏈接能量。
- 當玩家成功將對方奇美拉的生命降至 0 時,游戲就會結束。
學習玩 Chimera
Chimera 是一款具有較大狀態空間的不完美信息博弈 (Imperfect Information) 卡牌游戲,我們預計這會讓 ML 模型難以學習,并且我們的目標還是一個相對簡單的模型。我們的方法受 AlphaGo 等早期對弈智能體使用的方法啟發,其中卷積神經網絡 (CNN) 被訓練來預測給定任意對弈狀態下的獲勝概率。在隨機移動的對局上訓練初始模型后,我們設置智能體與自己對戰,反復收集對局數據,然后用于訓練新的智能體。每次迭代后,訓練數據的質量都會提高,智能體的游戲能力也會增強。
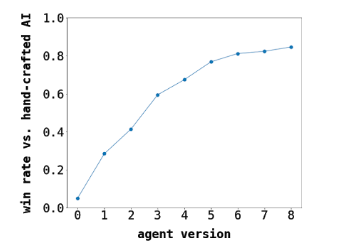
隨著訓練的推進,與性能最好的人工構建的 AI 相比,ML 智能體的表現情況:最初的 ML 智能體(版本 0)隨機移動
AlphaGo
https://deepmind.com/research/case-studies/alphago-the-story-so-far
對于模型接收為輸入的實際游戲狀態表征,我們發現將“圖像”編碼傳遞給 CNN 可獲得最佳表現,結果超過了所有基準程序智能體和其他類型的網絡(如完全連接)。選擇的模型架構足夠小,可以在合理時間內在 CPU 上運行。我們因此能夠下載模型權重,并使用 Unity Barracuda 在 Chimera 游戲客戶端中實時運行智能體。
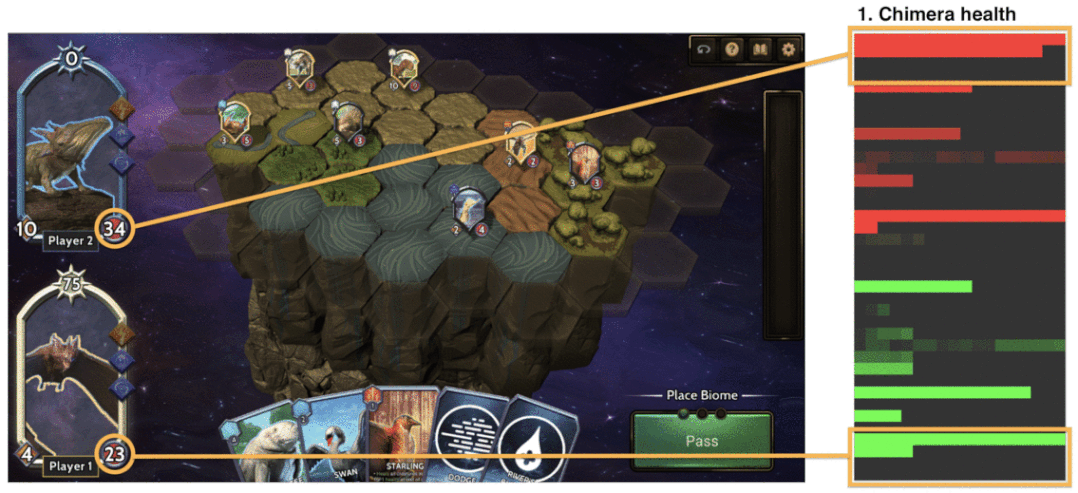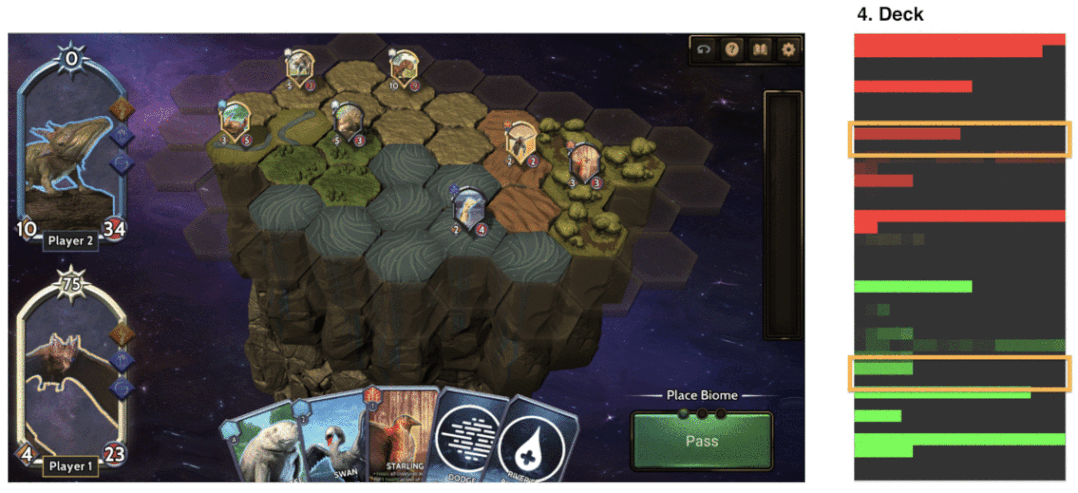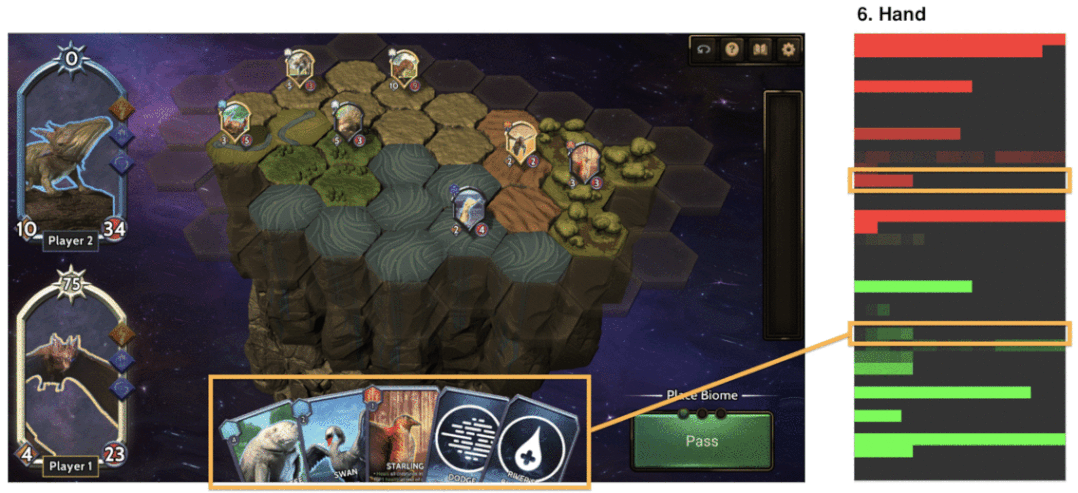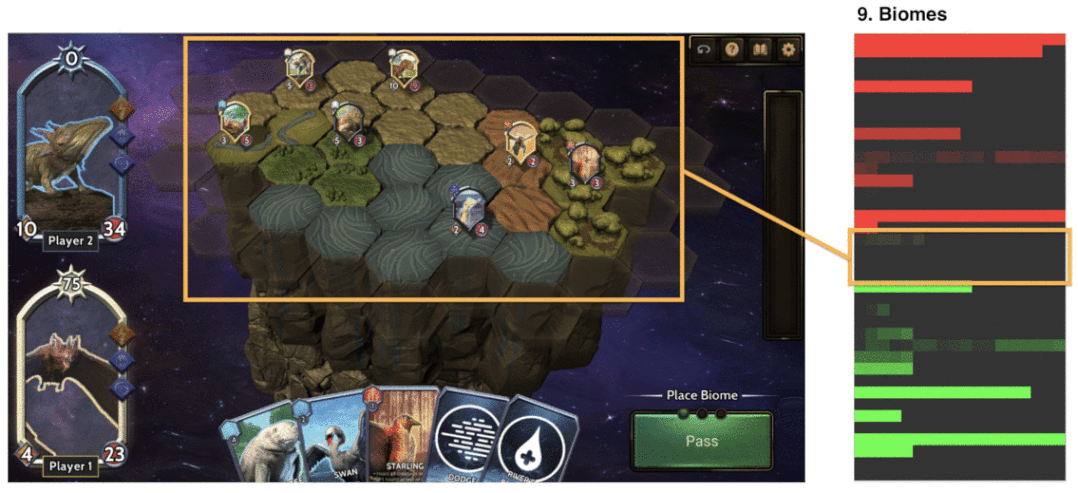
用于訓練神經網絡的示例游戲狀態表征
Unity Barracuda
https://github.com/Unity-Technologies/barracuda-release

除了為游戲 AI 做出決策,我們還使用該模型顯示玩家在游戲過程中的估計獲勝概率
平衡 Chimera
在相同時間內,模擬方法可比真實玩家能夠完成的對局多出數百萬場。在收集了表現最好的智能體的游戲數據后,分析結果顯示出我們設計的兩種玩家卡組之間的不平衡。
首先,Evasion Link Gen 卡組的法術和生物能產生額外的鏈接能量進化玩家的奇美拉。它還包含使生物能夠閃避攻擊的法術。相比之下,Damage-Heal 卡組的生物具有多種實力和專注于治療與造成輕微傷害的法術。雖然我們將這兩套卡組設計為具有相同的實力,但是 Evasion Link Gen 卡組在與 Damage-Heal 卡組對戰時取得了 60% 的勝率。
在我們收集與生物群系、生物、法術和奇美拉進化相關的各種統計數據后,有兩個結果立刻浮現出來:
- 進化奇美拉可以帶來顯著優勢 - 奇美拉進化次數更多的智能體更有可能贏得對局。然而,每場對局的平均進化次數并沒有達到我們的預期。為了讓它成為更核心的游戲機制,我們要增加總體平均進化次數,同時保持其使用策略。
- 霸王龍生物過于強大。它的出現與勝利密切相關,而且模型將始終選擇霸王龍,不考慮召喚到錯誤或過度擁擠的生物群系的懲罰。
根據這些分析結果,我們對游戲做出了一些調整:
- 為了強調奇美拉進化是游戲的核心機制,我們將進化奇美拉所需的鏈接能量從 3 減少到 1。
- 我們還為霸王龍生物增加了一個“冷卻”期,使其從任何行動中恢復的時間都增加了一倍。
使用更新后的規則重復“自我對局”訓練程序,結果顯示這些調整將游戲推向了預期的方向 - 每局游戲的平均進化次數有所增加,霸王龍的優勢逐漸被削弱。
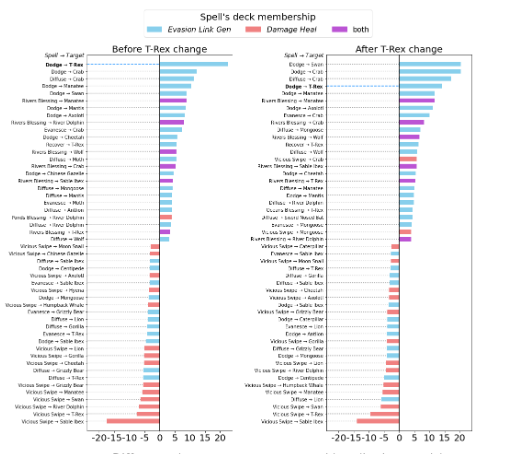
霸王龍平衡前后的影響力比較示例:圖表呈現了當卡組發起特定法術互動(如,使用“閃避”法術強化霸王龍)時獲勝(或失敗)的對局數量。左:改動前,霸王龍在所有檢查指標上都具有很強的影響力 - 最高的生存率,最有可能被無視懲罰地召喚,獲勝時吸收的生物最多。右:改動后,霸王龍遠不如先前強勢
霸王龍的削弱成功減少了 Evasion Link Gen 卡組對強勢生物的依賴。即便如此,兩套卡組的勝率依然是 60/40,而不是 50/50。經過對各個游戲日志的深入研究,我們發現玩法的策略性通常低于預期。再次搜索收集的數據后,我們又發現幾個需要改動的地方。
首先,我們增加了兩個玩家的初始生命值以及治療法術可以補充的生命值。這是為了鼓勵更長時間的游戲,發展更多樣的策略。特別是這使 Damage-Heal 卡組能夠存活足夠長的時間來發揮其治療策略。為了鼓勵符合設計的召喚和戰略性生物群系放置,我們提升了將生物放入不正確或擁擠生物群系時受到的懲罰。最后,我們通過小范圍的屬性調整,縮小了最強和最弱生物之間的差距。
在新的調整到位后,我們得出了這兩套卡組的最終游戲平衡數據:

結論
通常,在新的原型游戲中找出不平衡可能需要幾個月的游戲測試。通過這種新方法,我們不僅能夠發現潛在的不平衡,還能在幾天之內做出調整加以改良。
我們發現,相對簡單的神經網絡便足以在與人類和傳統游戲 AI 的競爭中表現出較高的水準。這些智能體還可以用于其他目的,例如指導新玩家或發現意外策略。我們希望這項成果能夠激發更多關于機器學習用于游戲開發的可能性的探索。






















