攜程運維自動化平臺讓上萬服務器變更也可以很輕松!
今天給大家分享的主題是基于 StackStorm 的攜程運維自動化平臺。
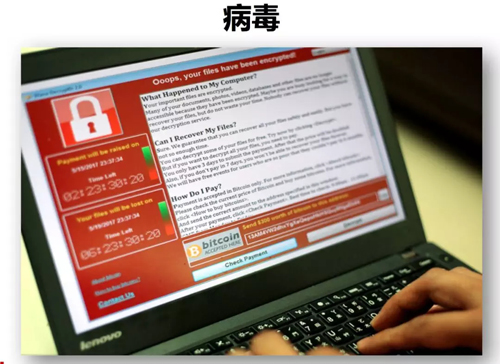
去年 5 月,勒索病毒爆發(fā),席卷全球,影響了政府部門、醫(yī)療機構(gòu)、公共交通、學校、企業(yè)等等,給全世界帶來了巨大損失。
如果有投資眼光的人,遇到這個事情,考慮的可能是購買比特幣。而作為運維工程師,考慮的只是如何防止病毒影響自己公司的業(yè)務。相信很多運維同行,都參與到了應對勒索病毒的戰(zhàn)役中。
關(guān)于這個病毒,雖然傳播廣,看起來威力巨大,但是也有很多應對措施。比如關(guān)閉 445 端口防止病毒傳播,或者內(nèi)網(wǎng)建立開關(guān)域名防止病毒運行。
當然,這些只是 workaround 的方案,最根本的還是要及時更新服務器的安全補丁。

如果只有幾臺、幾十臺服務器,補丁更新很簡單,登陸上去點下安裝或者敲一條命令就可以搞定。
當你有成千上萬臺服務器的時候靠人工是不可能的,如果一下子發(fā)一條命令下去到所有服務器也不合適,可能對業(yè)務造成巨大影響。

那么該如何自動給上萬臺服務器打補丁呢?我們先看一下,一臺服務器上怎么操作打補丁。
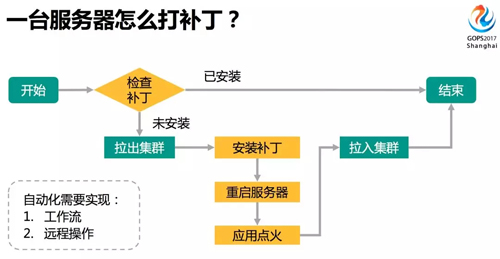
上圖是個比較簡單的操作流程。首先,檢查服務器是否已經(jīng)安裝了補丁,如果已經(jīng)安裝流程就結(jié)束。
如果還沒有安裝,先將服務器拉出集群脫離生產(chǎn),然后安裝補丁,重啟服務器讓補丁生效。
在拉入集群之前,可能還需要給應用點火,比如讓應用建緩存,讓應用恢復到正常狀態(tài)再接入生產(chǎn)流量。
這其中還有一些復雜問題,比如一個集群拉出部分服務器后,剩余服務器可能扛不住,要考慮集群可用性。
這樣一個給一臺服務器打補丁的過程,如果要實現(xiàn)自動化,就要完成兩方面的任務:
- 實現(xiàn)圖中整個工作流的運轉(zhuǎn)。
- 不可能一臺臺登陸服務器操作,所以要實現(xiàn)遠程操作,也就是圖中的黃色部分。
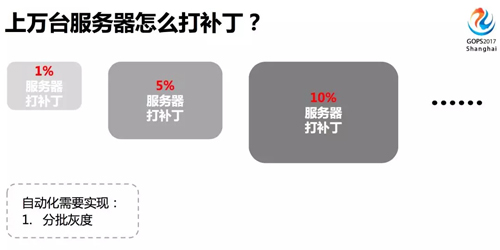
實現(xiàn)了一臺服務器自動打補丁后,再從 1 擴展到 1000、10000,給成千上萬臺服務器打補丁,要做的一件事就是灰度、灰度、灰度,重要的事情說三遍。
不管你操作多么熟練,技術(shù)多么高超,對自己開發(fā)的工具多么自信,在做生產(chǎn)大批量運維操作的時候,都要謹慎再謹慎。
而分批灰度是做到謹慎的很好的方法,可以大大減小對生產(chǎn)的影響,提高網(wǎng)站可用性。

綜合上述對實現(xiàn)上萬臺服務器自動打補丁的需求,我們搭建了一套自動化運維平臺,包括三個模塊:
- 使用 SaltStack 實現(xiàn)遠程控制。
- 使用 StackStorm 實現(xiàn)操作流程。
- 使用我們自己開發(fā)的工具 Jobs 實現(xiàn)分批灰度。
而這樣一套系統(tǒng),不只是可以完成打補丁這樣一個功能,基本可以覆蓋各種日常運維操作自動化需求,所以拿出來和大家分享,下面將從三方面進行具體介紹。
遠程控制
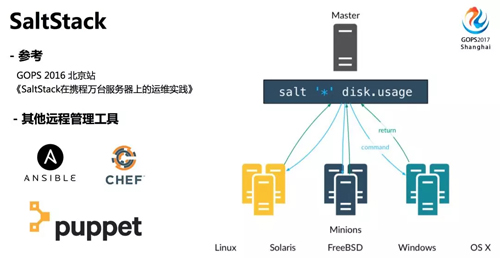
SaltStack 是一個開源的遠程管理平臺,可以管理各種操作系統(tǒng)的服務器,主要有 minion 和 master 兩部分。
minion 安裝在要管理的服務器上,啟動后與 master 建立長連接,master 下發(fā)任務給 minion,minion 運行完成后,將任務結(jié)果返回給 master。
類似的遠程管理工具還有 ansible、chef、puppet,大家可以根據(jù)實際應用場景選擇。
操作流程
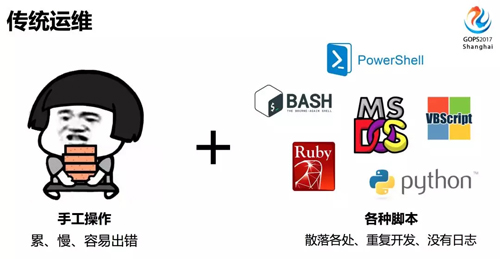
我們從運維發(fā)展的過程來看,首先是傳統(tǒng)運維,主要靠手工操作。比如上線一臺服務器,登陸服務器按照操作文檔一步一步操作,更高級一點,把配置命令寫到腳本里,運行一個或多個腳本完成配置。
有什么缺點呢?首先,人每天重復這樣的工作,很累,又沒有體現(xiàn)價值,交付效率低,疲勞時還容易出錯,忘記某些配置。
使用腳本呢,容易出現(xiàn)相同功能重復開發(fā),很多腳本不專門記錄日志,查找歷史操作比較困難。
使用腳本進行運維操作,發(fā)生了故障,由于沒有統(tǒng)一的運維操作日志,無法及時了解誰做了什么。
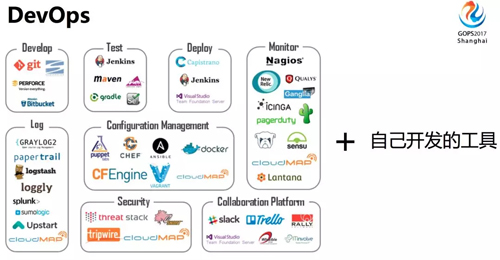
隨著時間的發(fā)展,運維發(fā)展到更高級的 DevOps 時代,我們也正處于這個時代。
這個時代有一個明顯的特征,就是各種各樣開源工具的使用,同時自己會開發(fā)很多工具。工具帶來了效率的提升,大大加速了運維自動化的進程。

有這么多的工具可以使用,也會存在一些問題。比如下面這些問題:
- 做一個復雜變更要操作很多工具
- 不同腳本或工具的代碼里,相同操作重復造輪子
- 對別人開發(fā)的腳本或工具,不清楚具體操作邏輯
- 沒有統(tǒng)一的運維操作日志
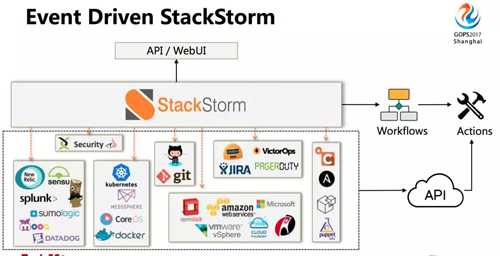
針對上面這些問題,我們考慮使用基于事件驅(qū)動的開源自動化運維平臺 StackStorm。
你有各種各樣的工具,會提供很多操作的 API,你把這些 API 調(diào)用實現(xiàn)成 action 放在 StackStorm 上,然后可以把這些 action 組合成復雜的 Workflow 實現(xiàn)不同的任務。
StackStorm 可以實現(xiàn)操作插件化、操作邏輯可視化、運維日志統(tǒng)一化。
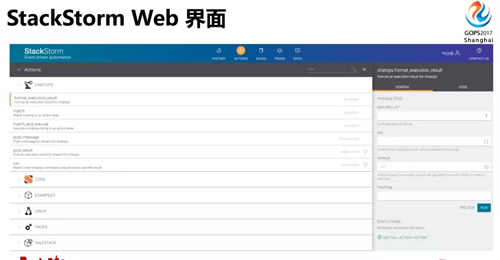
StackStorm 提供了 Web 界面,也提供了 API。你把各種工具的操作放在里面,選中一個操作,填入?yún)?shù),就可以點擊運行。
使用 StackStorm 具體能做一些什么事情呢?

我們?nèi)粘S泻芏嗖煌淖兏僮鳎墙?jīng)常會重復做一些相同的事情,比如安裝軟件、重啟服務、拉入拉出集群等。
如果把不同變更操作過程進行拆分,就會拆出這樣一個個小的運維原子操作。
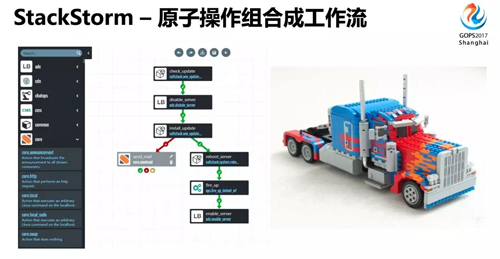
反過來,我們可以把這些運維原子操作進行組合,像樂高積木可以拼出各種各樣的模型,我可以將原子操作組合成各種各樣的變更流程。
這樣相同的操作只需要實現(xiàn)一次,就可以重復使用,避免了重復造輪子,大大提高了開發(fā)效率。
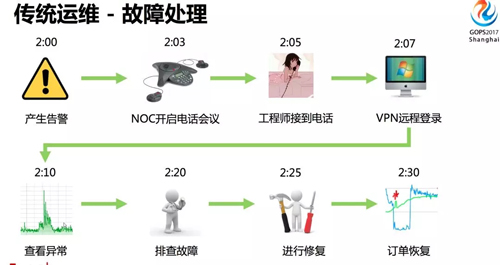
在故障處理方面,我們來看一個常規(guī)的 oncall case。
比如凌晨 2 點,出現(xiàn)了一個訂單下跌的告警,NOC 開啟電話會議,將相關(guān)工程師 call 進來,工程師接到電話后迷迷糊糊地爬起來,問出現(xiàn)了什么問題,NOC 需要陳述一遍。
然后工程師匆匆忙忙打開電腦,通過 VPN 登陸到內(nèi)網(wǎng)查看相關(guān)監(jiān)控指標,利用自己的經(jīng)驗進行故障排查,花了很多時間終于定位到故障,然后進行修復操作,最后故障恢復。

這樣的故障處理過程,存在什么問題呢?
- 修復時間長
- 半夜處理故障,操作容易出錯,而且影響第二天上班
- 隨著業(yè)務增長,報警增多,無法及時處理
- 導致網(wǎng)站可用性下降
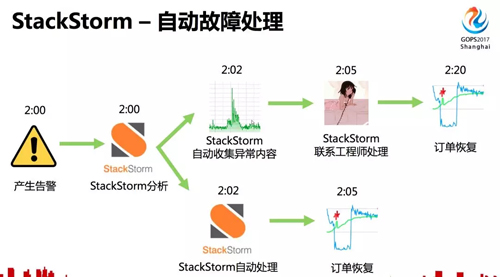
如果使用 StackStorm,故障處理的過程是怎么樣的呢?
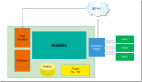
StackStorm 有 webhook 可以監(jiān)聽報警,當一個報警發(fā)送給 StackStorm 后,StackStorm 可以先進行一些分析,基于專家經(jīng)驗或者基于機器學習,分析完成之后,判斷這個報警是否可以自動處理,如果可以就執(zhí)行故障修復操作,故障恢復。
如果自己無法處理,會收集故障異常內(nèi)容,以及初步分析結(jié)果,發(fā)送給相應的工程師,為工程師節(jié)省了一些收集信息和排查的時間,工程師可以快速進行故障修復。
對于一些常規(guī)的頻繁發(fā)生的故障,如果已經(jīng)有一些固定的處理方法,完全可以交給 StackStorm 自動處理。
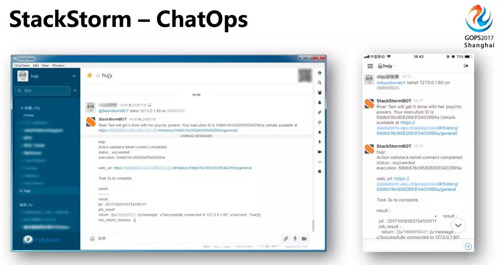
StackStorm 可以與 ChatOps 結(jié)合,進行日常運維操作,比如你正在參加 GOPS,StackStorm 將報警和初步分析發(fā)給你,你通過手機在 Chat Room 下發(fā)指令給 StackStorm,快速進行故障修復。
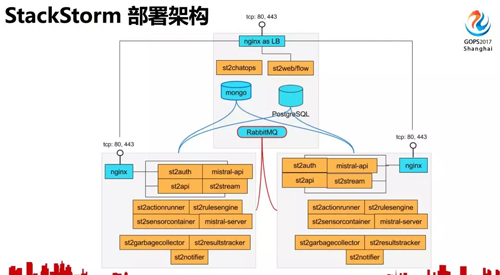
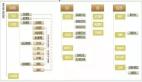
了解了 StackStorm 的一些功能,再來看看 StackStorm 的部署架構(gòu)。
圖中黃色的部分是 StackStorm 的主要模塊,包括認證、api、規(guī)則引擎、worker、chatops、webui 等等。
mistral 作為 Workflow 引擎,以 PostgreSQL 作為數(shù)據(jù)庫,MongoDB 存儲 action 定義、日志,RabbitMQ 是所有任務的消息隊列。這是一個高可用的架構(gòu),每一臺服務器上都運行著 worker 和 mistral。
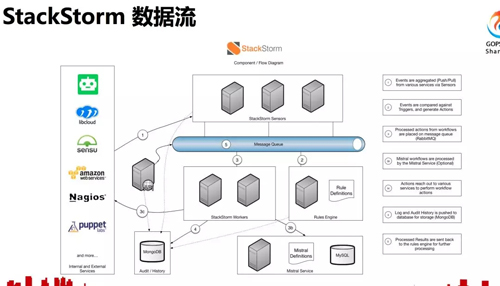
這是 StackStorm 的數(shù)據(jù)流圖,StackStorm 將 chat message 對應到動作是通過這里的規(guī)則引擎,上面提到的運維原子操作組合成工作流,工作流的解析由 mistral 來完成,每一個具體 action 的執(zhí)行由 worker 完成。

StackStorm 有下面三大好處:
- 提高了自動化開發(fā)效率
- 操作邏輯可視化
- 運維任何操作都有明細的記錄
分批灰度

雖然 StackStorm 有很多優(yōu)點,但是當你想對上萬臺服務器做一個操作時,你一定不會希望自己手動分批次,手動輸入到 StackStorm 里面點擊運行,運行如果出錯,還要去看 StackStorm 不便于閱讀的輸出及報錯堆棧。
你想要的,是建一個任務,指定一批服務器,在某個時間,執(zhí)行某個任務,最后給出一個運行結(jié)果統(tǒng)計。所以基于大批量服務器自動操作需求,我們開發(fā)了稱作 Jobs 的工具。
主要為了實現(xiàn)三個目標:
- 可以根據(jù)選擇的分批策略自動分批,比如按服務器比例 1%、5%、10% 這樣分批。
- 操作是插件化的,操作運行代碼不在 Jobs 中實現(xiàn),這里就要結(jié)合 StackStorm,Jobs 將命令下發(fā)給 StackStorm,具體的運行邏輯在 StackStorm 中實現(xiàn)。
- 可以進行結(jié)果統(tǒng)計,多少成功了,多少失敗了,在任務詳情頁可以很明確地看到。
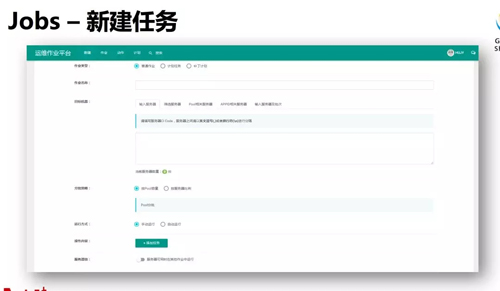
上圖就是 Jobs 系統(tǒng)的新建任務界面,有分批策略、篩選服務器等等。
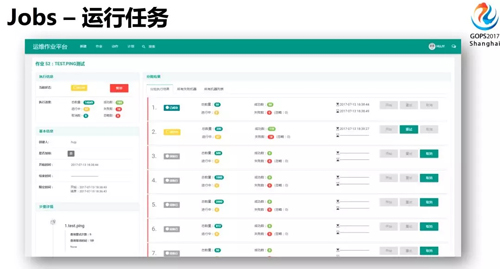
上圖是 Jobs 任務詳情頁,左邊是任務信息,右邊是具體的分批的情況。分批運行任務,即使任務運行造成了故障,可以及時發(fā)現(xiàn)及時停止,控制影響范圍。
總結(jié)
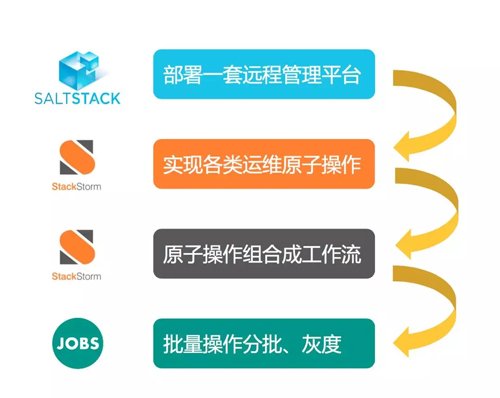
如果想搭建一套運維自動化的平臺,首先部署一套遠程管理框架,可以是 saltstack 或者 ansible 等。
然后在 StackStorm 上實現(xiàn)日常的運維原子操作,再根據(jù)具體的操作需求,將原子操作組合成工作流。
最后,對于大批量服務器運維任務,可以考慮開發(fā)一套具有分批灰度功能的系統(tǒng),完成自動化操作。
胡俊雅,攜程資深技術(shù)支持工程師,負責公司 SaltStack、StackStorm 等運維平臺管理,運維自動化工具開發(fā)。