百億級訪問量的實時監控系統如何實現?
原創【51CTO.com原創稿件】筆者自2016年加入WiFi***鑰匙,現任WiFi***鑰匙高級架構師,擁有10年互聯網研發經驗,喜歡折騰技術。主要專注于:分布式監控平臺、調用鏈跟蹤平臺、統一日志平臺、應用性能管理、穩定性保障體系建設等領域。
在本文中,筆者將與大家分享一下在實時監控領域的一些實戰經驗,介紹WiFi***鑰匙是如何構建APM端到端的全鏈路監控平臺,從而實現提升故障發現率、縮短故障處理周期、減少用戶投訴率、樹立公司良好品牌形象等目標。
WiFi***鑰匙開發運維團隊的困擾
始于盛大創新院的WiFi***鑰匙,截至到2016年底,我們總用戶量已突破9億、月活躍達5.2億,用戶分布在全球223個國家和地區,在全球可連接熱點4億,日均連接次數超過40億次。
隨著日活躍用戶大規模的增長,WiFi***鑰匙各產品線服務端團隊正進行著一場無硝煙的戰爭。越來越多的應用服務面臨著流量激增、架構擴展、性能瓶頸等問題。為了應對并支撐業務的高速發展,我們邁入了SOA、Microservice、API Gateway等組件化及服務化的時代。
伴隨著各系統微服務化的演進,服務數量、機器規模不斷增長,線上環境也變得日益復雜,工程師們每天都會面臨著諸多苦惱。例如:線上應用出現故障問題時無法***時間感知;面對線上應用產生的海量日志,排查故障問題時一籌莫展;應用系統內部及系統間的調用鏈路產生故障問題時難以定位等等。
綜上所述,線上應用的性能問題和異常錯誤已經成為困擾開發人員和運維人員***的挑戰,而排查這類問題往往需要幾個小時甚至幾天的時間,嚴重影響了效率和業務發展。WiFi***鑰匙亟需完善監控體系,幫助開發運維人員擺脫煩惱,提升應用性能。依據公司的產品形態及業務發展,我們發現監控體系需要解決一系列問題:
◆面對全球多地域海量用戶的WiFi連接請求,如何保障用戶連接體驗?
◆如何通過全鏈路監控提升用戶連接WiFi的成功率?
◆隨著微服務大規模推廣實施,鑰WiFi***鑰匙產品服務端系統越來越復雜,線上故障的發現、定位、處理難度也隨之增長,如何通過全鏈路監控提升故障處理速度?
◆移動出海已經進入深入化發展的下半場,全鏈路監控如何應對公司全球化的業務發展?
◆……
全鏈路監控
早期為了快速支撐業務發展,我們主要使用了開源的監控方案保障線上系統的穩定性:Cat、Zabbix,隨著業務發展的需要,開源的解決方案已經不能滿足我們的業務需求,我們迫切需要構建一套滿足我們現狀的全鏈路監控體系:
◆多維度監控(系統監控、業務監控、應用監控、日志搜索、調用鏈跟蹤等)
◆多實例支撐(滿足線上應用在單臺物理機上部署多個應用實例場景需求等)
◆多語言支撐(滿足各團隊多開發語言場景的監控支撐,Go、C++、PHP等)
◆多機房支撐(滿足國內外多個機房內應用的監控支撐,機房間數據同步等)
◆多渠道報警(滿足多渠道報警支撐、內部系統對接,郵件、掌信、短信等)
◆調用鏈跟蹤(滿足應用內、應用間調用鏈跟蹤需求,內部中間件升級改造等)
◆統一日志搜索(實現線上應用日志、Nginx日志等集中化日志搜索與管控等)
◆……
監控目標
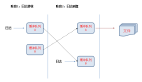
從“應用”角度我們把監控體系劃分為:應用外、應用內、應用間。如下圖所示:

應用外:主要是從應用所處的運行時環境進行監控(硬件、網絡、操作系統等)
應用內:主要從用戶請求至應用內部的不同方面(JVM、URL、Method、SQL等)
應用間:主要是從分布式調用鏈跟蹤的視角進行監控(依賴分析、容量規劃等)
羅馬監控體系的誕生
根據自身的實際需求,WiFi***鑰匙研發團隊構建了羅馬(Roma)監控體系。之所以將監控體系命名為羅馬,原因在于:
1、羅馬不是一天成煉的(線上監控目標相關指標需要逐步完善);
2、條條大路通羅馬(羅馬通過多種數據采集方式收集各監控目標的數據);
3、據神話記載特洛伊之戰后部分特洛伊人的后代鑄造了古代羅馬帝國(一個故事的延續、一個新項目的誕生)。
一個***的監控體系會涵蓋IT領域內方方面面的監控目標,從目前國內外各互聯網公司的監控發展來看,很多公司把不同的監控目標劃分了不同的研發團隊進行處理,但這樣做會帶來一些問題:人力資源浪費、系統重復建設、數據資產不統一、全鏈路監控實施困難。目前,各公司在監控領域采用的各解決方案,如下圖所示:

正如圖中所示,羅馬監控體系希望能夠汲取各方優秀的架構設計理念,融合不同的監控維度實現監控體系的“一體化”、“全鏈路”等。
高可用架構之道
面對每天40多億次的WiFi連接請求,每次請求都會經歷內部數十個微服務系統,每個微服務的監控維度又都會涉及應用外、應用內、應用間等多個監控指標,目前羅馬監控體系每天需要處理近千億次指標數據、近百TB日志數據。面對海量的監控數據羅馬(Roma)如何應對處理?接下來,筆者帶大家從系統架構設計的角度逐一進行剖析。
架構原則
一個監控系統對于接入使用方應用而言,需要滿足如下圖中所示的五點:
• 性能影響:對業務系統的性能影響最小化(CPU、Load、Memory、IO等)
• 低侵入性:方便業務系統接入使用(無需編碼或極少編碼即可實現系統接入)
• 無內部依賴:不依賴公司內部核心系統(避免被依賴系統故障導致相互依賴)
• 單元化部署:監控系統需要支撐單元化部署(支持多機房單元化部署)
• 數據集中化:監控數據集中化處理、分析、存儲等(便于數據統計等)
整體架構
Roma系統架構如下圖所示:

Roma架構中各個組件的功能職責、用途說明如下:

Roma整體架構中劃分了不同的處理環節:數據采集、數據傳輸、數據同步、數據分析、數據存儲、數據質量、數據展示等,數據流處理的不同階段主要使用到的技術棧如下圖所示:

數據采集
對于應用內監控主要是通過client客戶端同所在機器上的agent建立TCP長連接的方式處理,agent同時也需要具備通過腳本調度的方式獲取系統性能指標數據。

面對海量的監控指標數據,羅馬監控通過在各層中預聚合的方式進行匯總計算,比如在客戶端中相同URL請求的指標數據在一分鐘內匯總計算后統計結果為一條記錄(分鐘內相同請求進行累加計算,通過占用極少內存、減少數據傳輸量),對于一個接入并使用羅馬的系統,完全可以根據其實例數、指標維度、采集頻率等進行監控數據規模的統計計算。通過各層分級預聚合,減少了海量數據在網絡中的數據傳輸,減少了數據存儲成本,節省了網絡帶寬資源和磁盤存儲空間等。
應用內監控的實現原理(如下圖所示):主要是通過客戶端采集,在應用內部的各個層面進行攔截統計: URL、Method、Exception、SQL等不同維度的指標數據。

應用內監控各維度指標數據采集過程如下圖所示:針對不同的監控維度定義了不同的計數器,最終通過JMX規范進行數據采集。

數據傳輸
數據傳輸TLV協議,支持二進制、JSON、XML等多種類型。

每臺機器上都會部署agent(同客戶端建立TCP長連接),agent的主要職責是數據轉發、數據采集(日志文件讀取、系統監控指標獲取等),agent在獲取到性能指標數據后會發送至kafka集群,在每個機房都會獨立部署kafka集群用于監控指標數據的發送緩沖,便于后端的節點進行數據消費、數據存儲等。
為了實現數據的高效傳輸,我們對比分析了消息處理的壓縮方式,最終選擇了高壓縮比的GZIP方式,主要是為了節省網絡帶寬、避免由于監控的海量數據占用機房內的網絡帶寬。針對各個節點間數據通信的時序圖如下圖所示:建立連接->讀取配置->采集調度->上報數據等。

數據同步
海外運營商眾多,公網覆蓋質量參差不齊,再加上運營商互聯策略的不同,付出的代價將是高時延、高丟包的網絡質量,鑰匙產品走向海外過程中,首先會對整體網絡質量情況有正確的預期,比如如果需要對于海外機房內的應用進行監控則依賴于在海外建立站點(主機房)、海外主站同國內主站進行互聯互通,另外需要對監控指標數據分級處理,比如對于實時、準實時、離線等不同需求的指標數據采集時進行歸類劃分(控制不同需求、不同數據規模等指標數據進行采樣策略的調整)
由于各產品線應用部署在多個機房,為了滿足各個應用在多個機房內都可以被監控的需求,羅馬監控平臺需要支持多機房內應用監控的場景,為了避免羅馬各組件在各個機房內重復部署,同時便于監控指標數據的統一存儲、統一分析等,各個機房內的監控指標數據最終會同步至主機房內,最終在主機房內進行數據分析、數據存儲等。
為了實現多機房間數據同步,我們主要是利用kafka跨數據中心部署的高可用方案,整體部署示意圖如下圖所示:

在對比分析了MirrorMaker、uReplicator后,我們決定基于uReplicator進行二次開發,主要是因為當MirrorMaker節點發生故障時,數據復制延遲較大,對于動態添加topic則需要重啟進程,黑白名單管理完全靜態等。雖然uReplicator針對MirrorMaker進行了大量優化,但在我們的大量測試之后仍遇到眾多問題,我們需要具備動態管理MirrorMaker進程的能力,同時我們也不希望每次都重啟MirrorMaker進程。
數據存儲
為了應對不同監控指標數據的存儲需求,我們主要使用了HBase、OpenTSDB、Elasticsearch等數據存儲框架。

數據存儲我們踩過了很多的坑,總結下來主要有以下幾點:
• 集群劃分:依據各產品線應用的數據規模,合理劃分線上存儲資源,比如我們的ES集群是按照產品線、核心系統、數據大小等進行規劃切分;
• 性能優化:Linux系統層優化、TCP優化、存儲參數優化等;
• 數據操作:數據批量入庫(避免單條記錄保存),例如針對HBase數據存儲可以通過在客戶端進行數據緩存、批量提交、避免客戶端同RegionServer頻繁建立連接(減少RPC請求次數)
數據質量
我們的系統在持續不斷地產生非常多的事件、服務間的鏈路消息和應用日志,這些數據在得到處理之前需要經過Kafka。那么,我們的平臺是如何實時地對這些數據進行審計呢?
為了監控Kafka數據管道的健康狀況并對流經Kafka的每個消息進行審計,我們調研并分析了Uber開源的審計系統Chaperone,在經過各種測試之后,我們決定自研來實現需求,主要是因為我們希望具備任意節點任意代碼塊內的數據審計需求,同時需要結合我們自己的數據管道特點,設計和實現達成一系列目標:數據完整性與時延;數據質量監控需要近實時;數據產生問題時便于快速定位(提供診斷信息幫助解決問題);監控與審計本身高度可信;監控平臺服務高可用、超穩定等;
為了滿足以上目標,數據質量審計系統的實現原理:把審計數據按照時間窗口聚合,統計一定時間段內的數據量,并盡早準確地檢測出數據的丟失、延遲和重復情況。同時有相應的邏輯處理去重,晚到以及非順序到來的數據,同時做各種容錯處理保證高可用。
數據展示
為了實現監控指標的數據可視化,我們自研了前端數據可視化項目,同時我們也整合了外部第三方開源的數據可視化組件(grafana、kibana),在整合的過程中我們遇到的問題:權限控制問題(內部系統SSO整合)主要是通過自研的權限代理系統解決、去除kibana官方提供的相關插件、完善并自研了ES集群監控插件等。
核心功能及落地實踐
系統監控
我們的系統監控主要使用了OpenTSDB作為數據存儲、Grafana作為數據展示,TSDB數據存儲層我們通過讀寫分離的方式減輕存儲層的壓力,TSDB同Grafana整合的過程中我們也遇到了數據分組展示的問題(海量指標數據下查詢出分組字段值,通過建立獨立的指標項進行數據查詢),如下圖某機器系統監控效果:

應用監控
針對各個Java應用,我們提供了不同的監控類型用于應用內指標數據的度量。

業務監控
針對業務監控,我們可以通過編碼埋點、日志輸出、HTTP接口等不同的方式進行業務監控指標采集,同時支持多維度數據報表展示,如下圖所示:

我們的業務監控通過自助化的方式讓各應用方便捷的接入,如下圖監控項定義:

日志搜索
為了支撐好研發人員線上排查故障,我們開發了統一日志搜索平臺,便于研發人員在海量日志中定位問題。

未來展望
隨著IT新興技術的迅猛發展,羅馬監控體系未來的演進之路:
• 多語言支撐:滿足多語言的監控需求(性能監控、業務監控、日志搜索等)
• 智能化監控:提高報警及時性、準確性等避免報警風暴(ITOA、AIOps)
• 容器化監控:隨著容器化技術的驗證落地實施,容器化監控開啟布局;
總結
羅馬(Roma)是一個能夠對應用進行深度監控的全鏈路監控平臺,主要涵蓋了應用外、應用內、應用間等不同維度的監控目標,例如應用監控、業務監控、系統監控、中間件監控、統一日志搜索、調用鏈跟蹤等。能夠幫助開發者進行快速故障診斷、性能瓶頸定位、架構梳理、依賴分析、容量評估等工作。
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】