MySQL 一千個(gè)不用 Null 的理由
港真,Null 貌似在哪里都是個(gè)頭疼的問(wèn)題,比如 Java 里讓人頭疼的 NullPointerException,為了避免猝不及防的空指針異常,千百年來(lái)程序猿們不得不在代碼里小心翼翼的各種 if 判斷,麻煩而又臃腫,為此 java8 引入了 Optional 來(lái)避免這一問(wèn)題。
下面咱們要聊的是 MySQL 里的 null,在大量的 MySQL 優(yōu)化文章和書(shū)籍里都提到了字段盡可能用NOT NULL,而不是NULL,除非特殊情況。但卻都只給結(jié)論不說(shuō)明原因,猶如雞湯不給勺子一樣,讓不少初學(xué)者對(duì)這個(gè)結(jié)論半信半疑或者云里霧里。本文今天就詳細(xì)的剖析下使用 Null 的原因,并給出一些不用 Null 的理由。
1、NULL 為什么這么多人用?
NULL是創(chuàng)建數(shù)據(jù)表時(shí)默認(rèn)的,初級(jí)或不知情的或怕麻煩的程序員不會(huì)注意這點(diǎn)。
很多人員都以為not null 需要更多空間,其實(shí)這不是重點(diǎn)。
重點(diǎn)是很多程序員覺(jué)得NULL在開(kāi)發(fā)中不用去判斷插入數(shù)據(jù),寫(xiě)sql語(yǔ)句的時(shí)候更方便快捷。
2、是不是以訛傳訛?
MySQL 官網(wǎng)文檔:
- NULL columns require additional space in the rowto record whether their values are NULL. For MyISAM tables, each NULL columntakes one bit extra, rounded up to the nearest byte.
Mysql難以?xún)?yōu)化引用可空列查詢(xún),它會(huì)使索引、索引統(tǒng)計(jì)和值更加復(fù)雜。可空列需要更多的存儲(chǔ)空間,還需要mysql內(nèi)部進(jìn)行特殊處理。可空列被索引后,每條記錄都需要一個(gè)額外的字節(jié),還能導(dǎo)致MYisam 中固定大小的索引變成可變大小的索引。
—— 出自《高性能mysql第二版》
照此分析,還真不是以訛傳訛,這是有理論依據(jù)和出處的。
3、給我一個(gè)不用 Null 的理由?
- (1)所有使用NULL值的情況,都可以通過(guò)一個(gè)有意義的值的表示,這樣有利于代碼的可讀性和可維護(hù)性,并能從約束上增強(qiáng)業(yè)務(wù)數(shù)據(jù)的規(guī)范性。
- (2)NULL值到非NULL的更新無(wú)法做到原地更新,更容易發(fā)生索引分裂,從而影響性能。
注意:但把NULL列改為NOT NULL帶來(lái)的性能提示很小,除非確定它帶來(lái)了問(wèn)題,否則不要把它當(dāng)成優(yōu)先的優(yōu)化措施,最重要的是使用的列的類(lèi)型的適當(dāng)性。
- (3)NULL值在timestamp類(lèi)型下容易出問(wèn)題,特別是沒(méi)有啟用參數(shù)explicit_defaults_for_timestamp
- (4)NOT IN、!= 等負(fù)向條件查詢(xún)?cè)谟?NULL 值的情況下返回永遠(yuǎn)為空結(jié)果,查詢(xún)?nèi)菀壮鲥e(cuò)
- create table table_2 (
- `id` INT (11) NOT NULL,
- user_name varchar(20) NOT NULL
- )
- create table table_3 (
- `id` INT (11) NOT NULL,
- user_name varchar(20)
- )
- insert into table_2 values (4,"zhaoliu_2_1"),(2,"lisi_2_1"),(3,"wangmazi_2_1"),(1,"zhangsan_2"),(2,"lisi_2_2"),(4,"zhaoliu_2_2"),(3,"wangmazi_2_2")
- insert into table_3 values (1,"zhaoliu_2_1"),(2, null)
- -- 1、NOT IN子查詢(xún)?cè)谟蠳ULL值的情況下返回永遠(yuǎn)為空結(jié)果,查詢(xún)?nèi)菀壮鲥e(cuò)
- select user_name from table_2 where user_name not in (select user_name from table_3 where id!=1)
- mysql root@10.48.186.32:t_test_zz5431> select user_name from table_2 where user_name not
- -> in (select user_name from table_3 where id!=1);
- +-------------+
- | user_name |
- |-------------|
- +-------------+
- 0 rows in set
- Time: 0.008s
- mysql root@10.48.186.32:t_test_zz5431>
- -- 2、單列索引不存null值,復(fù)合索引不存全為null的值,如果列允許為null,可能會(huì)得到“不符合預(yù)期”的結(jié)果集
- -- 如果name允許為null,索引不存儲(chǔ)null值,結(jié)果集中不會(huì)包含這些記錄。所以,請(qǐng)使用not null約束以及默認(rèn)值。
- select * from table_3 where name != 'zhaoliu_2_1'
- -- 3、如果在兩個(gè)字段進(jìn)行拼接:比如題號(hào)+分?jǐn)?shù),首先要各字段進(jìn)行非null判斷,否則只要任意一個(gè)字段為空都會(huì)造成拼接的結(jié)果為null。
- select CONCAT("1",null) from dual; -- 執(zhí)行結(jié)果為null。
- -- 4、如果有 Null column 存在的情況下,count(Null column)需要格外注意,null 值不會(huì)參與統(tǒng)計(jì)。
- mysql root@10.48.186.32:t_test_zz5431> select * from table_3;
- +------+-------------+
- | id | user_name |
- |------+-------------|
- | 1 | zhaoliu_2_1 |
- | 2 | <null> |
- | 21 | zhaoliu_2_1 |
- | 22 | <null> |
- +------+-------------+
- 4 rows in set
- Time: 0.007s
- mysql root@10.48.186.32:t_test_zz5431> select count(user_name) from table_3;
- +--------------------+
- | count(user_name) |
- |--------------------|
- | 2 |
- +--------------------+
- 1 row in set
- Time: 0.007s
- -- 5、注意 Null 字段的判斷方式, = null 將會(huì)得到錯(cuò)誤的結(jié)果。
- mysql root@localhost:cygwin> create index IDX_test on table_3 (user_name);
- Query OK, 0 rows affected
- Time: 0.040s
- mysql root@localhost:cygwin> select * from table_3 where user_name is null\G
- ***************************[ 1. row ]***************************
- id | 2
- user_name | None
- 1 row in set
- Time: 0.002s
- mysql root@localhost:cygwin> select * from table_3 where user_name = null\G
- 0 rows in set
- Time: 0.002s
- mysql root@localhost:cygwin> desc select * from table_3 where user_name = 'zhaoliu_2_1'\G
- ***************************[ 1. row ]***************************
- id | 1
- select_type | SIMPLE
- table | table_3
- type | ref
- possible_keys | IDX_test
- key | IDX_test
- key_len | 23
- ref | const
- rows | 1
- Extra | Using where
- 1 row in set
- Time: 0.006s
- mysql root@localhost:cygwin> desc select * from table_3 where user_name = null\G
- ***************************[ 1. row ]***************************
- id | 1
- select_type | SIMPLE
- table | None
- type | None
- possible_keys | None
- key | None
- key_len | None
- ref | None
- rows | None
- Extra | Impossible WHERE noticed after reading const tables
- 1 row in set
- Time: 0.002s
- mysql root@localhost:cygwin> desc select * from table_3 where user_name is null\G
- ***************************[ 1. row ]***************************
- id | 1
- select_type | SIMPLE
- table | table_3
- type | ref
- possible_keys | IDX_test
- key | IDX_test
- key_len | 23
- ref | const
- rows | 1
- Extra | Using where
- 1 row in set
- Time: 0.002s
- mysql root@localhost:cygwin>
(5)Null 列需要更多的存儲(chǔ)空間:需要一個(gè)額外字節(jié)作為判斷是否為 NULL 的標(biāo)志位
- alter table table_3 add index idx_user_name (user_name);
- alter table table_2 add index idx_user_name (user_name);
- explain select * from table_2 where user_name='zhaoliu_2_1';
- explain select * from table_3 where user_name='zhaoliu_2_1';
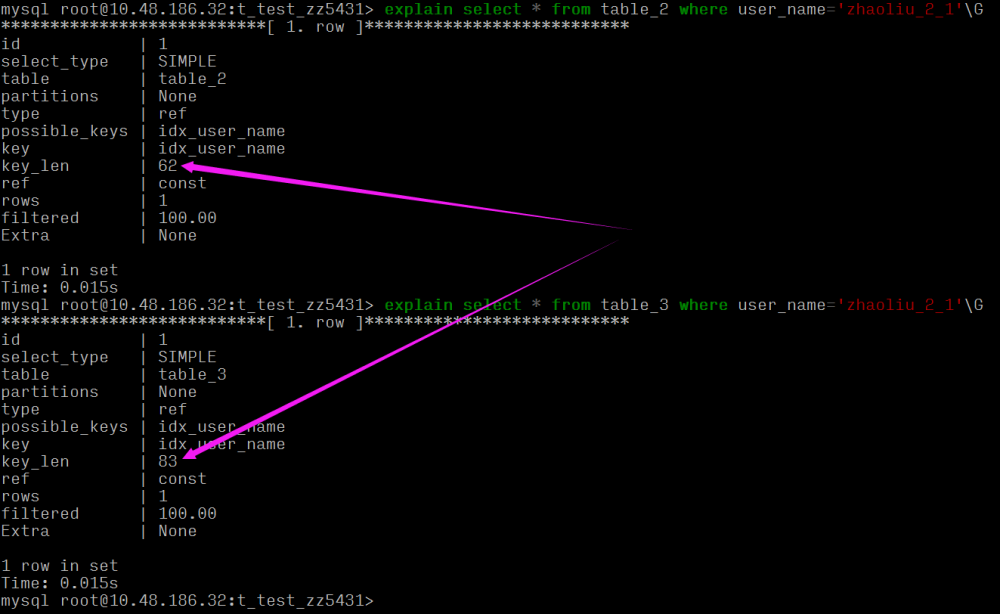
可以看到同樣的 varchar(20) 長(zhǎng)度,table_2 要比 table_3 索引長(zhǎng)度大,這是因?yàn)椋?/p>
- 兩張表的字符集不一樣,且字段一個(gè)為 NULL 一個(gè)非 NULL。
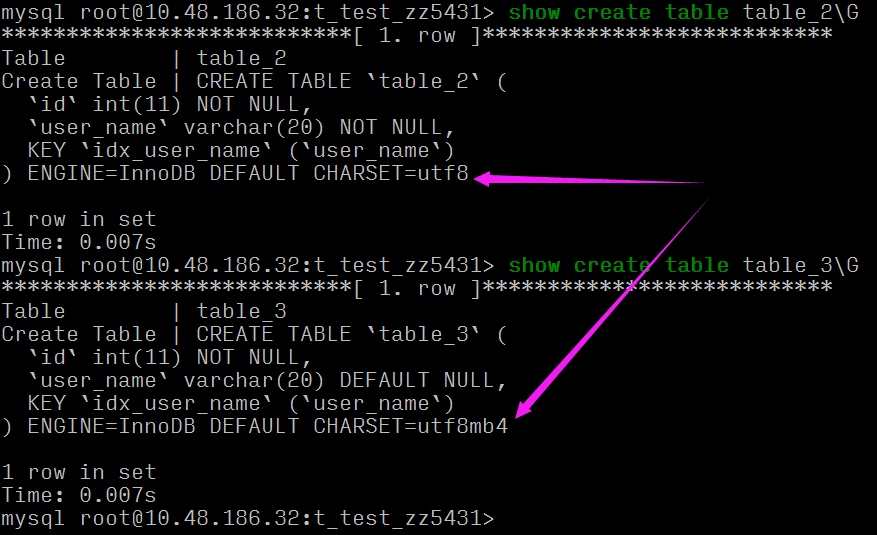
key_len 的計(jì)算規(guī)則和三個(gè)因素有關(guān):數(shù)據(jù)類(lèi)型、字符編碼、是否為 NULL
key_len 62 == 20*3(utf8 3字節(jié)) + 2 (存儲(chǔ) varchar 變長(zhǎng)字符長(zhǎng)度 2字節(jié),定長(zhǎng)字段無(wú)需額外的字節(jié))
key_len 83 == 20*4(utf8mb4 4字節(jié)) + 1 (是否為 Null 的標(biāo)識(shí)) + 2 (存儲(chǔ) varchar 變長(zhǎng)字符長(zhǎng)度 2字節(jié),定長(zhǎng)字段無(wú)需額外的字節(jié))
所以說(shuō)索引字段***不要為NULL,因?yàn)镹ULL會(huì)使索引、索引統(tǒng)計(jì)和值更加復(fù)雜,并且需要額外一個(gè)字節(jié)的存儲(chǔ)空間。基于以上這些理由和原因,我想咱們不用 Null 的理由應(yīng)該是夠了 🙂