一千個微服務之死
沒問題制造問題
有一則頗為滑稽的場景,講述了一位工程師向項目經理解釋一個過于復雜的微服務系統是如何工作的,以便獲取用戶的生日,但最終仍然解釋不清楚。
 圖片
圖片
這一場景準確地描述了當前IT文化的荒謬之處。然而在現實中,如果你跟面試官講了這個笑話,你猜他會怎么看你,大概率你不會通過面試的。
為什么會變成這樣呢?我們的目標本來應該是讓系統正常的運行起來,滿足業務的需要,但是現在卻變成了要解決根本沒有的問題(微服務帶來的問題),結果就是熬了好多個夜,掉了好多根頭發,給服務器運營商分了不少錢,結果呢?
完美風暴
近年來,有幾件事可能導致了當前局勢。
首先,大批使用 JavaScript 前端開發者開始自稱為“全棧”,涉足服務器開發和異步代碼,比如node,比如 Vercel 對 React 的魔幻操作。JavaScript就是JavaScript,使用它創建什么不重要, 用戶界面、服務器、游戲還是嵌入式系統。對吧?
Node當時還只是一個人的學習項目,早期的JavaScript是服務器開發盡量要避免的,或者不可能選擇的語言。但你如果和一些固執的 JavaScript、Node開發者來說,會遭到對方的鄙夷。畢竟,這是他們知道的全部,Node之外的世界實際上是不存在,Node就是唯一的選項,因此這是我們至今要處理的固執、教條主義思維的起源。
另外,還有一大批大廠向外輸送的“人才”涌入初創公司或者小公司隊伍中。用大廠的那一套模式和方法來指導團隊,即使這套模式并不合適。那不是他要考慮的。“我不管,怎么沒有單獨的用戶服務呢?將來怎么擴展呢,兄弟!”
還有一個不得不說的事實,在國內凡是面試,必定要問微服務,從來也不看看線上用戶才多少,開發團隊才幾個人。這就導致很多沒有接觸過微服務的開發者,愿意在平時的項目中嘗試微服務,因為能夠積累一些經驗,方面以后跳槽能拿到更多的錢。
在早些時候,分布式系統是受到尊重、畏懼和普遍盡量避免的,僅作為處理特別棘手問題的最后手段。一旦涉及分布式系統,就會變得更具挑戰性、更加耗時,無論是開發、調試、部署、測試。
但是現在卻變得超級容易了,因為有了各種各樣的框架和工具,比如docker、k8s,以及像 Spring Cloud、Dubbo 等各式各樣拿來即用的框架。
這里的摘要讓我印象深刻,因為它充滿了常識性的結論:有一份關于5年初創公司審計摘要:那些表現最好的初創公司,通常對工程學采取了一種竭盡所能“保持簡單”的方法。純粹為了耍聰明是被鄙視的。相反,那些讓我們感到“哇,這些人真是聰明極了”的公司,大部分都已經消失了。
許多初創公司遇到了一種“冒牌綜合癥”的問題。在構建直截了當、簡單、高性能系統時,那些一開始沒有使用微服務的公司,常常會疑惑“只要一個Spring Boot單體維護就可以,由幾個工程師維護,還有一個MySQL實例,難道系統不應該這么做嗎?”。答案是“沒有”。
同樣,有經驗的開發者在當今 IT 環境中常常會陷入自我懷疑和自我否定。好消息是,這可能不是你的問題。
在今天的技術世界中,一些團隊或開發者往往假裝他們在做高并發、超復雜的系統,但他們可能甚至不知道數據庫索引的基礎知識。我們正處在一個充滿不合理的過度自信、浪費的海洋中,那么真正的騙子是誰呢?
單體架構沒有錯
如果你沒有一個看起來像臭名昭著的阿富汗戰爭戰略圖式的系統架構圖,你就無法成長,這種想法是一個笑話。
 圖片
圖片
Dropbox、Twitter、Netflix、Facebook、GitHub、Instagram、Shopify、StackOverflow ,這些公司和其他公司都以單一代碼庫開始。其中許多公司的核心仍然是單體。StackOverflow引以為傲的是他們運行龐大網站所需的硬件非常少。Shopify仍然是一個Rails單體,利用了經過驗證的Resque來處理數十億個任務。
WhatsApp是以Erlang單體和一個相對較小的團隊開發而最終成功的。并一直將團隊人員保持在較小規模,只有大約50名工程師。每個Team也很小,由1-3名工程師組成,每個Team都擁有很大的自主權。
在服務器方面,WhatsApp更傾向于使用較少數量的服務器,并將每臺服務器縱向擴展到最大程度。縱向擴展就是加強單機配置,比如增加 CPU、內存、存儲等,相對而言,增加多臺服務器叫做橫向擴展。
Instagram被以數十億美元收購 ,團隊只有12個人。
不要解決您沒有的問題
這是一個簡單的問題,您解決的是什么問題?是規模問題嗎?
當你準備將系統做成復雜的微服務架構時,你就要面對下面眾多的問題:
- 系統的拆分策略是什么,哪些功能要歸結為一個服務,哪些要隔離開;
- 分布式系統是為高并發、穩定性而建立的。您的系統是否可以同時擴展性和穩定性?
- 如果其中一個服務崩潰或變慢會發生什么?會影響到其他服務嗎?
- 你是否考慮了如果將會發生了變化,將如何應對?
- 要做壓力測試,要有斷容器,有隊列,分布式事務等等。
- 每個接口都有合理的超時時間嗎?
- 有沒有絕對安全的保護措施,以確保簡單的變更不會導致整個系統崩潰?
這是,需要了解和調整的配置和功能就是無窮無盡的,這樣,我們在解決業務問題的同時,又增加許多本來不必要的問題,甚至這些不必要的問題超過了原本的業務問題。
事實上,大多數公司永遠不會達到真正需要構建真正分布式系統的規模,這實際上可能只是在浪費金錢和時間。
比分布式系統更糟糕的是錯誤的分布式系統。
拆成微服務,每個團隊都只維護自己的 API?
將問題分解為更小的部分,然后逐個解決,是一種常見方法。那么,是不是你將一個服務分解為多個服務,一切都會變得更容易呢?
這個說法是充滿理想主義的,每個微服務都由一個專門的團隊維護,圍繞著一個漂亮的、向后兼容的、有版本的API。從此之后,你就很少甚至不必與這個團隊溝通了, 就好像這個微服務是由一個第三方供應商維護的一樣。
但事實往往是事與愿違的。事實上,公司各種群聊中充斥著來自團隊的消息,這些消息涉及發布、錯誤、配置更新、破壞性更改等等。每個人都需要隨時了解所有的內容,甚至比之前更多的內容。
多個微服務如何維護
構建微服務有很多陷阱,要么完全沒有得到充分認識,要么被簡單地忽視了。
很有可能是,團隊花費很長時間編寫高度定制的工具,并且得到了跟核心產品毫不相關的教訓。這里只是一些經常被忽視的方面:
每個服務往往都充滿了冗余的樣板文件,樣板代碼。很多時候,這種樣板的開銷很大,而為了保持微服務的“微小”,這些冗余、通用的部分會被抽離出去,那么,這些抽離出去代碼怎么維護呢?
弄一個通用庫嗎?如何更新通用庫呢?還是到處保留不同的版本?又或者定期強制更新呢?還是允許每一個微服務有重復呢?
到最后就變成了,去你的,還是按照自己習慣的方式重新發明輪子吧。
在單體架構中,更新和打補丁很容易,因為一切都在一起。在微服務中,打個補丁可能意味著在整個復雜系統中蜂群一般的更改。如果有十個微服務依賴于同一項更改,怎么確定是哪十個微服務依賴了更改?如果不知道,那么這些更改如何處理?或者更糟糕的是,如果一個團隊拒絕進行更改怎么辦?那可能會在重新啟動微服務時發現一個甚至多個詭異的問題。
返璞歸真
最近,有不少的企業,還是比較大的企業將一些原本是微服務架構的系統回歸到了單體架構。
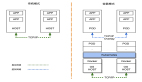
亞馬遜的 Prime Video 團隊將微服務架構遷移到了單體,云成本降低了 90%。
 圖片
圖片
在Uber,正在將許多微服務遷移到所謂的 "寬松服務"(well-sized services)。確實,測試和維護數千個微服務不僅很困難,而且長期來看可能會比解決短期問題帶來更多麻煩。
 圖片
圖片
打個比喻,要從北京到上海,是建造一艘復雜的宇宙飛船呢,還是買一張高鐵票來的實在?
英文原文地址:https://renegadeotter.com/2023/09/10/death-by-a-thousand-microservices.html