互聯網分布式存儲入門
在Google、Amazon、騰訊等大型互聯網公司里,因為業務廣泛,有大量的用戶數據需要保存,因此分布式存儲系統往往成為該類公司的一個基礎設施。分布式存儲涉及到單機存儲引擎、分布式系統協議等眾多領域,該篇文章作為一個入門,帶領大家認識分布式存儲系統的基本概念。
分布式存儲應該滿足的基本條件
- 可擴展
以微信朋友圈的圖片為例,隨著微信運營時間的增長,需要保存的朋友圈圖片必然是越來越多的,因此保存這些圖片的分布式存儲系統必須可擴展。
- 低成本
對于大型互聯網公司來講,要保存的數據量非常大,因此成本是考量一個存儲系統是否可上線運營非常重要的一個指標。
- 高性能
無論是對整個分布式存儲集群還是針對單機的存儲引擎,都需要高性能的保證,否則低成本就無從談起。
- 易用性
分布式存儲系統作為一個基礎設施,必須具備足夠的易用性,才能更好地服務于各個業務。比如Amazon的S3,接口形式統一,接入簡單。
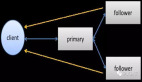
分布式存儲系統面臨的主要技術挑戰
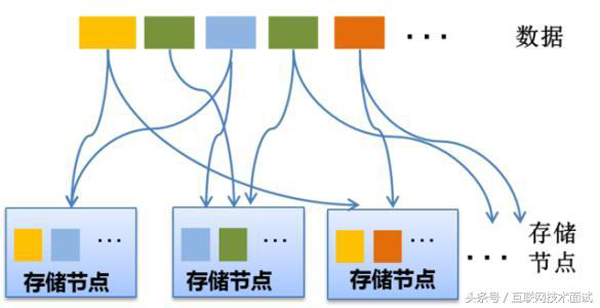
- 數據分布
整個存儲系統是一個集群,如何保證數據均勻分布到多臺服務器?假設某一數據被拆分存儲到多臺服務器后,又該如何實現跨服務器讀寫?
- 一致性
出于數據可靠性的考慮,同一份數據必然是保存多份的,如何保證這多份數據的一致性?
- 容錯
對于一個集群而言,機器出現故障是必然的。如何在出現故障時做到及時發現,并且自動把故障機器上的數據和服務遷移到非故障機器?
- 負載均衡
任何一個集群系統都存在負載均衡的策略問題,分布式存儲系統自然不例外。
- 事務與并發控制
如果要求該分布式存儲系統支持事務和并發控制功能,該如何實現?
- 易用性
易用性前面有提,不再贅述。
- 壓縮/解壓縮
怎樣根據數據的特點設計、選用合理的壓縮/解壓縮算法以平衡壓縮帶來的空間節省和消耗的CPU計算資源。
分布式存儲系統存儲的數據分類
互聯網業務涉及的數據一般可以分為三大類:
1.非結構化數據
典型的如圖片、音視頻文件等。
2.結構化數據
傳統的用關系型數據庫保存的二維表結構數據。
3.半結構化數據
介于結構化數據和非結構化數據之間,典型的比如HTML文檔。
分布式存儲系統分類
基于上述數據類型存儲的實際需要,分布式存儲系統逐漸演化為以下四種類型:
1.分布式文件系統
一般用于存儲非結構化數據。比如HDFS、TFS(Taobao File System)、FastDFS等。
2.分布式鍵值系統
可以通俗地理解為hash表,如淘寶的Tair、Redis、memcached等,一般用于存儲半結構化數據。
3.分布式表格系統
也用于存儲非結構化數據,相比分布式鍵值系統,不單單提供基于主鍵的讀寫,還支持對某個主鍵范圍進行掃描,典型的比如Google的Big Table。
4.分布式數據庫
由單機數據庫發展而來,用于存儲結構化數據。典型的如MySQL Sharding集群。