淺談互聯網分布式架構的演進
互聯網的系統常常面臨龐大的用戶群體,意味著系統需要時刻面臨著大量高并發請求,海量的數據存儲等問題的挑戰,在解決這些問題的同時還要保證系統的高可用性。同時互聯網行業更新迭代快,很多互聯網巨頭的發展初始階段,為了快速把產品上線發布以占據用戶流量,會以最簡單的應用架構形態對系統進行部署,不會過多地考慮未來的應用架構的發展,所以很多互聯網公司發展到一定規模,都會進行相應的架構重構與改進,以便適應業務的發展。
我這幾年經歷過很多家公司,從幾個開發人員的小公司到擁有 10+ 億用戶規模的公司都經歷過,因此我對互聯網公司的系統應用架構的演進有著一些深刻的感悟。
單點應用
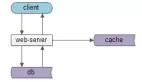
公司發展初期,由于用戶量少,系統的并發請求并不高,且數據量少,往往只需要將應用單點部署即可滿足業務的需求:
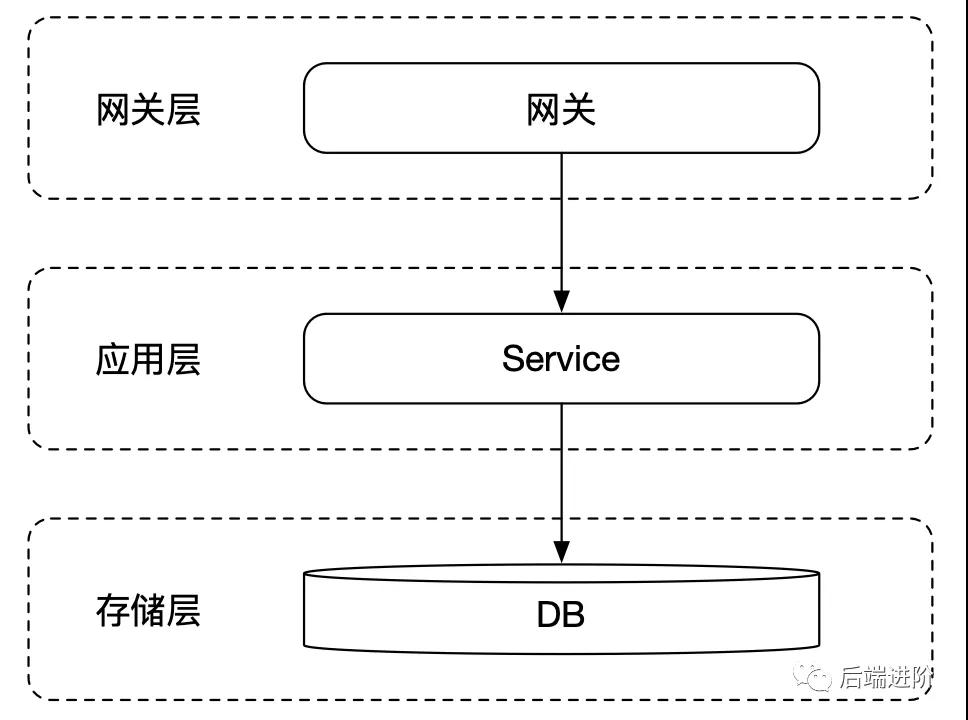
以上就是一個典型的早期互聯網應用的架構模式,應用只需要部署在單臺服務器上,甚至數據庫都放在同一臺服務器,流量直上直下,一桿子到底。
由于應用和數據庫都是單體形式,所以缺點明顯,不能進行故障轉移,一旦應用或者數據庫其中之一遇到故障,則整個系統不可用。
應用 SOA 化
1、水平拆分
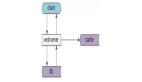
單體應用缺乏故障轉移,同時隨著請求數量的增多,單體應用部署的請求處理不過來了,常見的問題是應用連接數被打滿,用戶的請求超時,而且響應耗時長。
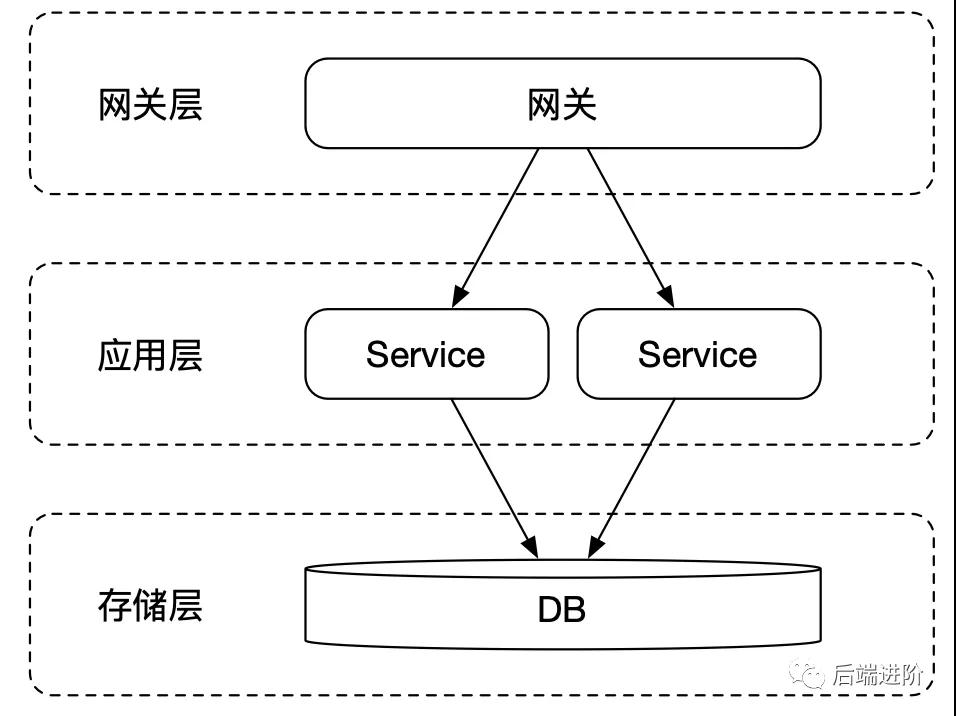
如上圖所示,將系統進行水平化拆分,部署多個應用實例,同時網關將流量進行平均分配,有效減少單個應用的請求壓力,同時應用服務具備故障轉移,當服務遇到故障,只要還保持著一個以上應用實例,系統就能夠運轉(還需要考慮降級處理)。
這是初級的應用 SOA 化階段。
2、垂直拆分
隨著公司業務的高速發展,業務的體量越來越大,一個應用承載了全部的業務,所有的業務代碼都放在同一個代碼倉庫中,雖然這樣容易部署,運維成本低,但缺點非常明顯,隨著業務的體量越來越大,項目的代碼急劇增加,各個業務間的越來越復雜,耦合度越來越高。而且擴展性隨著代碼量的增多越來越差,而且發布周期窗口會越來越長,無法做到快速迭代快速上線。
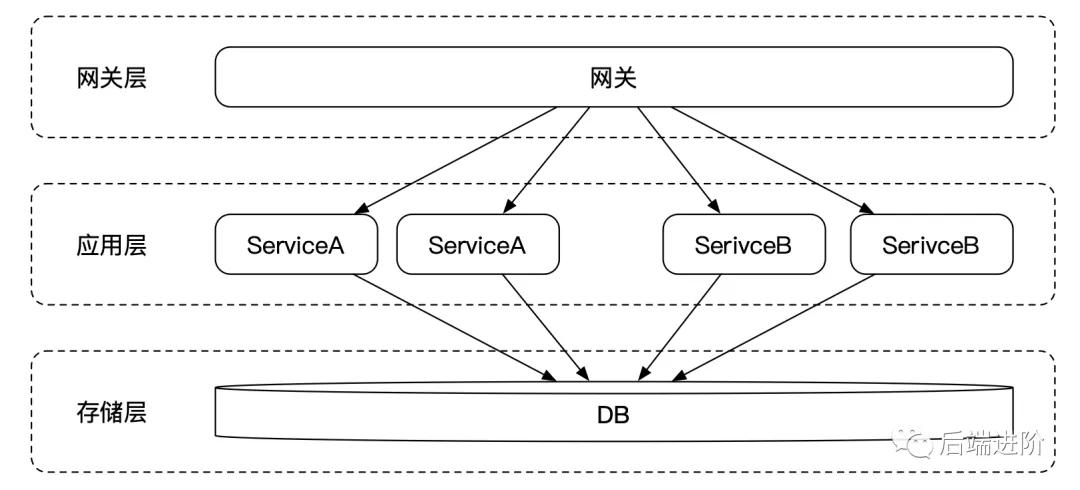
為了解決以上問題,我們可以對系統按照業務的維度進行垂直拆分,比如商城系統,可以拆分成用戶服務、交易服務、訂單服務等,如上圖所示。
到這里,系統經過水平拆分和垂直拆分,應用層基本完成了 SOA 化。
存儲拆分
1、存儲讀寫分離
隨著業務的發展,這時發現應用服務不再是負擔,但數據層成為了整個系統的唯一單點,這時候,隨著系統 TPS 的增多,應用的實例部署越來越多,單個數據庫的連接數變多,數據的寫入效率變慢了,單主庫無法維持整個系統的數據讀寫。
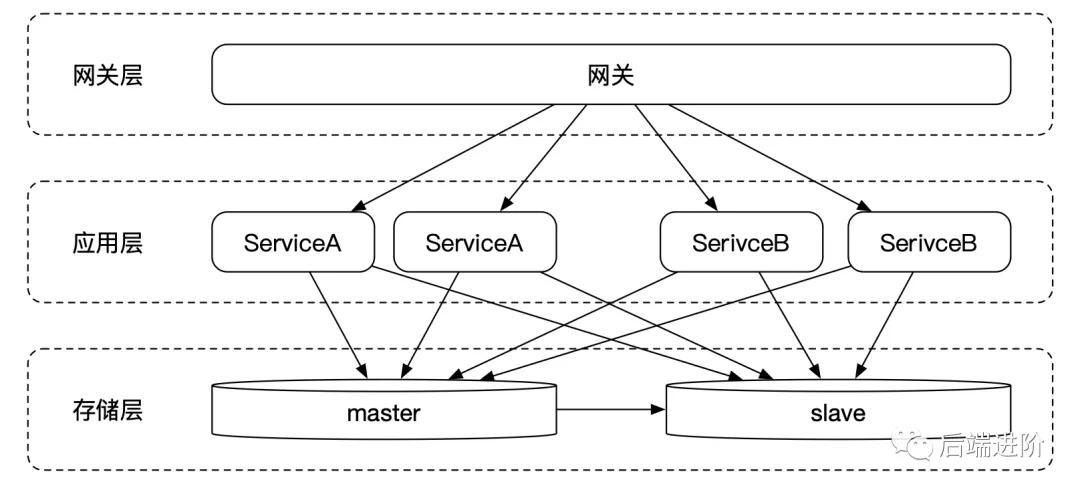
這時將數據層進行讀寫分離,將數據庫拆分成一個主數據庫和若干個從數據庫,數據的寫入還是由主數據庫負責,讀數據則由從數據庫負責,這樣就可以大大減輕了數據寫入的負擔。但讀寫分離就是讀和寫不是嚴格同步的,主數據庫同步數據給從數據庫需要一定的時間,但大部分的數據延遲都能夠接受。
2、存儲垂直拆分
數據讀寫分離之后,數據寫入減輕了一定的負擔,但我們發現,整個系統全局只有只有一個主庫,各個業務域的數據寫入都嚴重依賴于這個主庫,流量一旦上來,單主數據庫根本扛不住。
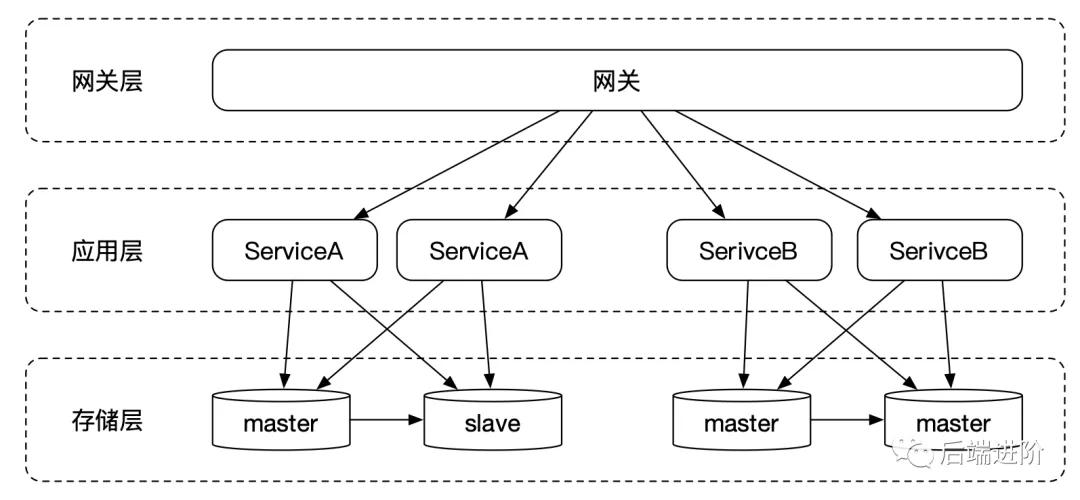
與應用垂直拆分類似,存儲層的垂直拆分,同樣根據業務維度去拆分,拆分成若干個庫,比如商城系統,可以拆分成用戶庫、訂單庫等。從上圖可以看到,數據寫入的流量,各個業務域獨自負擔自己的數據讀寫。
至此,一個基本完整的分布式應用架構基本成型了,隨之而來的就是要解決因數據庫拆分而伴生的分布式事務問題。
3、存儲水平拆分
當業務發展到一定量級,單庫單表不足以承擔起各自業務域的數據讀寫,那這時怎么辦呢?
這時我們可以按照用戶維度,對數據進行水平拆分,比如按照用戶 ID 最后兩位,將一張大表切分成 100 張小表,再新建 100 個庫(當然數據庫可以少于表的數量),我們可以將這種分庫分表規則稱為百庫百表模式。
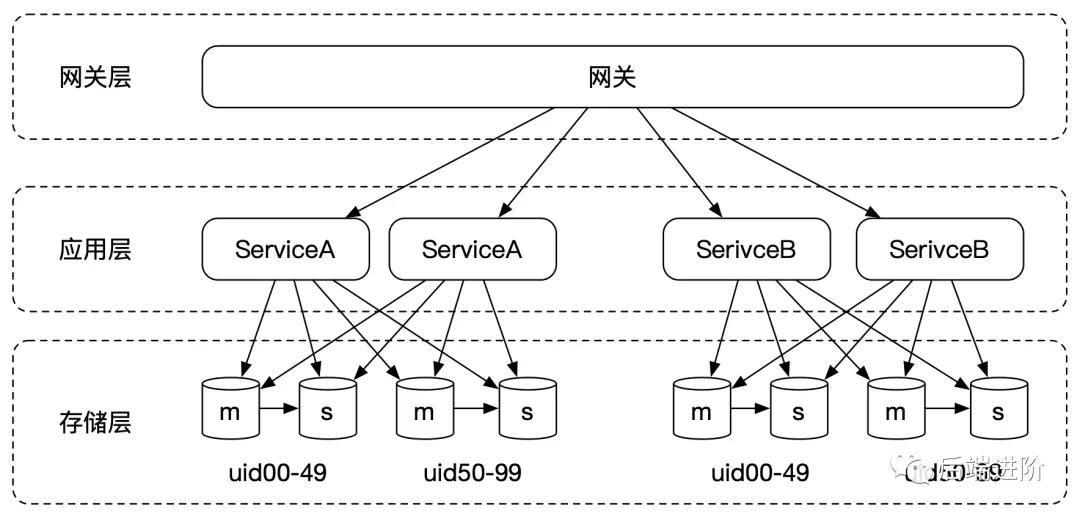
分庫分表可以有效減少單表數據的數據量,還可以按照用戶維度將流量分散到各個庫和表中,性能得到了全面的提升。
至此,一個完整的分布式架構已經成型,事實上這是很多大型互聯網公司當前的部署架構現狀。
單元化部署
隨著業務的進一步發展,類似某些擁有 10 億+用戶量級的巨頭公司,因此他們的應用實例部署規模都非常大,這隨著而來會伴隨著數據庫連接數量不夠的問題,從上圖我們可以看出,隨著應用實例的增加,數據庫的鏈接數量就會增多。
為什么呢?
因為每個數據庫的實例,都是被應用實例所共享的,那你可能要問為什么要共享,那是因為網關的流量是按平均分配的,你的每個請求,都有可能落到任意的應用實例中,那么這時應用實例就必須要根據你的用戶 ID,將數據落在指定的表中,這時應用實例必須要擁有所有數據庫的連接才能做到。
那么像 10 億+用戶量級的系統,本身流量已經非常高了,每當讓服務進行水平擴容,都異常艱難,甚至已經到了數據庫連接的上限,服務不能繼續水平擴容了。
那應該怎么辦?
既然數據可以按照用戶維度進行分庫分表,那么請求的流量何嘗不能按照用戶維度進行水平拆分呢?
我們將按照用戶維度對應用實例進行單元化隔離,每個單元都部署了系統所有的服務,用戶可在某個單元內走完所有的業務流程,如下圖所示:
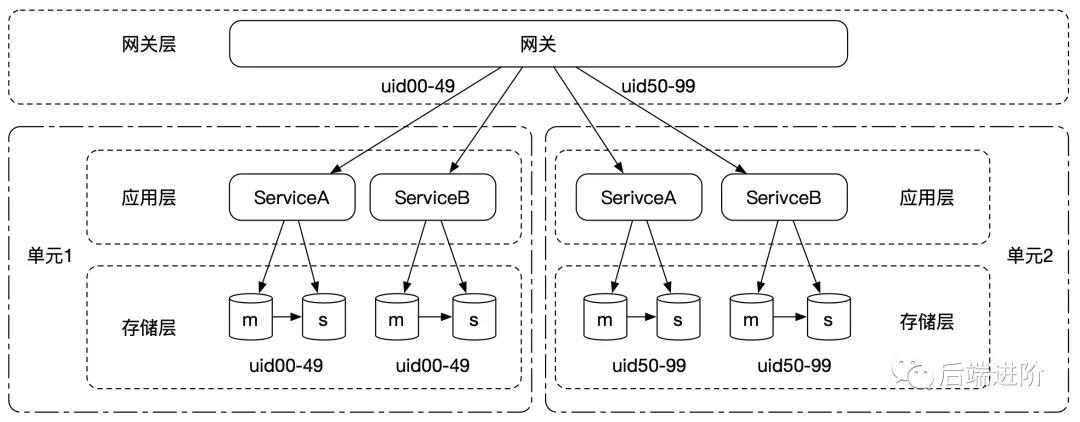
可以看出,經過單元化隔離,數據庫的連接數量成倍地減少,如果單元化粒度拆分更小,那么數據庫的連接數量會更少。
數據分區
對于大型互聯網公司來說,往往擁有多個物理機房,在多個機房中,部署模式主要分成兩種:
垂直部署(擴展模式):將系統的服務、數據庫劃分為若干份,每個機房擁有部分服務和數據庫,這樣可以解決機房容量問題,但是要完成一個業務,可能需要經過多個機房協作,且某個機房出現故障,會導致整個系統不可用,不具備容災能力;
水平部署(鏡像模式):每個機房擁有所有的服務,即每個機房都能夠完成一個業務的流轉,具備容災能力。
一般大多數公司都會采用第二種水平部署模式,但是這種模式下,需要解決數據分區問題,我們知道應用都是無狀態的,我們可以很容易地將流量隨機分配給各個機房,讓每個機房承載一定的流量。但是數據卻不行,要做到每個機房擁有獨立的數據庫是一件挺難的事情。
那怎么解決數據分區問題呢?
前面我們已經談到單元化部署,由于一個單元包含了系統所有的服務,我們可將其稱作一個邏輯數據中心(Logical Data Center),簡稱 LDC。
同樣,水平部署模式下,一個物理機房也擁有所有的服務,我們可將其稱作一個互聯網數據中心(Internet Data Center),簡稱 IDC。
那么,它們的關系:
LDC 是對 IDC 的一種邏輯劃分。
用大白話講就是:
LDC 則是在 IDC 的基礎上進行的一個邏輯劃分,一個 LDC 邏輯數據中心被稱為一個「單元」,每個單元都擁有所有部署的應用,每個單元可以分配到任意一個物理機房,每個物理機房可以擁有若干個單元,如下圖所示:
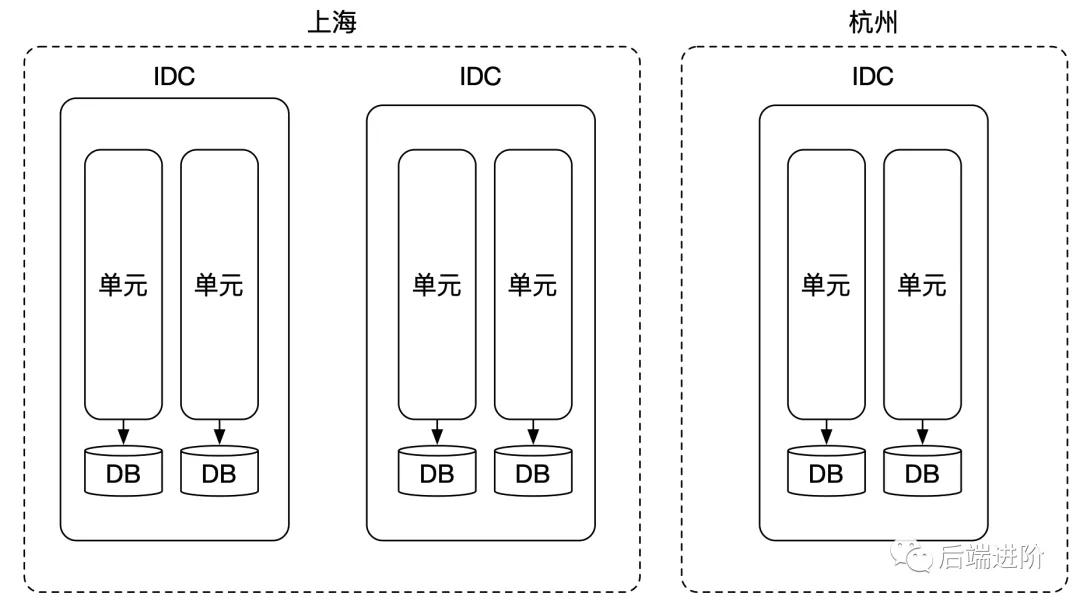
如上圖所示,物理機房在水平部署模式下,單元化如何解決數據分區問題呢?
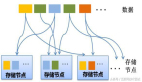
前面我們說了我們按照用戶維度進行單元化隔離部署的,那么我們也可以對數據進行分區,將數據按照用戶維度對數據進行分區,比如將用戶最后 2 位進行數據分區,一共將數據拆分成 100 份,每個單元負責若干份數據,比如系統一共有 10 個單元,那么每個單元負責 10 個分區的數據。
這樣,每個單元下都有獨立的數據分區,完全可以做到數據的隔離。
如何擴容
在單元化部署架構下,如何進行擴容呢?
應用擴容
系統經過單元化隔離部署之后,通常情況下數據庫連接已不再是瓶頸,這也是單元化部署帶來的收益之一,這時我們很容易通過將單元中的每個服務增加若干個應用實例來達到擴容的目的。
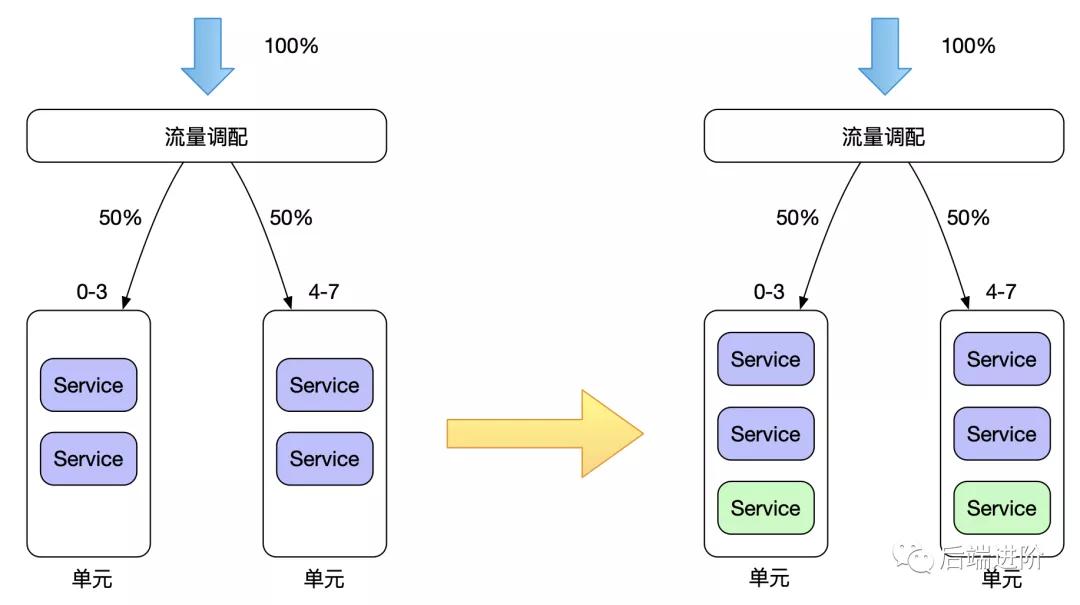
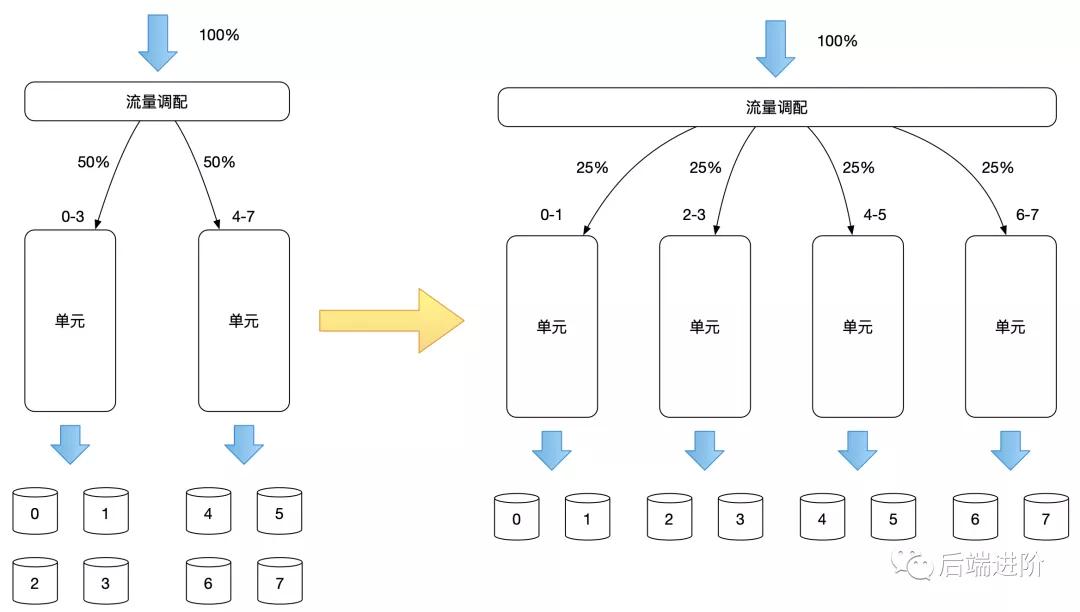
單元擴容
增加單元數量,增加后的每個單元,流量重新分配,但需要注意的是,增加單元數據,并不意味著數據分區會增加,數據層與應用層的擴容完全沒有關系,但值得一提的是,單元擴容可以有效減少數據庫的連接數,每個單元所連接的數據分區,是按照單元所負責的用戶維度的流量來區分的,如下圖所示:
存儲擴容
增加一個單元很容易,但是要在原有的數據分區下進行擴容,就不好做了,因為涉及到表路由規則的變更,需要對數據進行遷移,且一般在進行分庫分表時,都會提前預估未來業務的容量需求,各個用戶維度已經提前進行了 Pre-Sharding 處理了,所以如果數據要進行擴容,則需要對數據進行重新 sharding 處理,這里涉及到數據遷移,就不細展開了。
本文轉載自微信公眾號「后端進階」,可以通過以下二維碼關注。轉載本文請聯系后端進階公眾號。