微信海量數據監控的設計與實踐
本文分享的是微信運維監控系統的具體設計實踐。在分享開始之前,我們先看如下圖中微信后臺系統的現狀。
面對龐大的調用量及復雜的調用鏈路,單靠人力難以維護,只能依賴一個全方位監控、穩定、快速的運維監控系統。

我們的運維監控系統主要有三個功能:
- 故障報警
- 故障分析和定位
- 自動化策略
今天我們的分享主題,主要有以下三部分:
- 監控數據收集輕量化
- 微信數據監控的發展過程
- 海量監控分析下的數據存儲設計思路
監控數據收集輕量化
先看一下常見的數據收集流程,一般從日志里面采集,然后本地匯總打包,再發到全局服務器里面匯總。
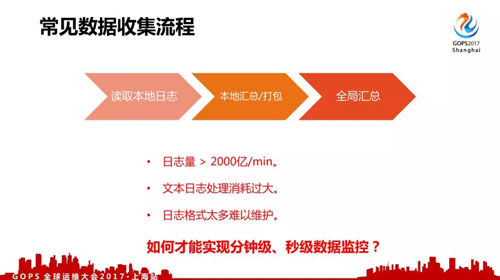
但是對于微信來說,200w/min 調用量產生的是 2000億/min 的監控數據上報,這個還是比較保守的估計數據。
早期我們使用過自定義文本類型日志上報,但由于業務及后臺服務非常多,日志格式增長非常快,難以持續進行維護,而且不管是 CPU、網絡、存儲、統計都出現非常大的壓力,難以保證監控系統本身的穩定。
為了實現穩定的分鐘級、甚至秒級的數據監控,我們進行了一系列改造。
對于我們內部監控數據處理分為兩個步驟:
- 數據分類
- 定制處理策略
我們對數據進行分類,在我們內部來說有三種數據:
- 實時故障監控分析。
- 非實時數據統計,比如說業務報表等。
- 單用戶異常分析,比如說用戶一個報障過來還要單獨對用戶故障進行分析。
下面先簡單介紹一下非實時數據統計及單用戶異常分析,再重點介紹實時監控數據的處理。
非實時數據
對于非實時數據來說,我們有一個配置管理頁面。
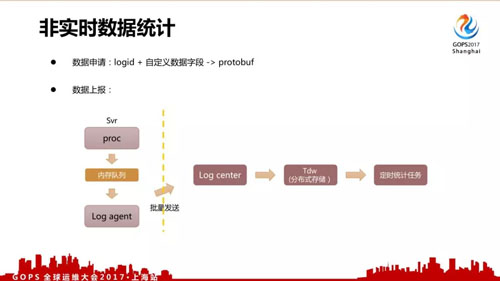
用戶在上報的時候會先申請 logid + 自定義數據字段,上報并非使用寫日志文件的方式,而是采用共享內存隊列、批量打包發送的方式減少磁盤 IO、日志服務器的調用壓力。統計使用分布式統計,目前已經是常規做法。
單用戶異常分析
對于單個用戶異常分析來說,我們關注的是異常,所以上報路徑跟剛才非實時的路徑比較相近。
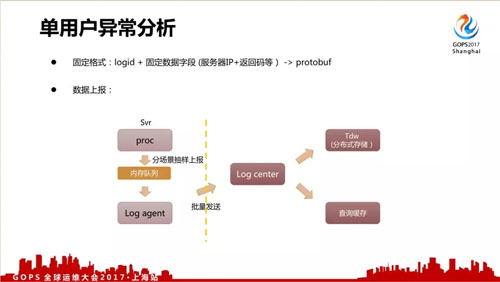
采用固定的格式: logid + 固定數據字段(服務器 IP+返回碼等)。
數據上報量比剛才的非實時日志還要大很多,所以我們是抽樣上報的,除了把數據存入到 Tdw 分布式存儲里面,還會把它轉發到另外一個緩存里面進行一個查詢緩存。
實時監控數據
實時監控數據是重點分享的部分,這部分數據也是 2000億/min 日志上報中的絕大多數。
為了實現分方位的監控,我們的實時監控數據也有很多種類型,其格式、來源、統計方式都有差異。
為了實現快速穩定的數據監控,我們對數據進行了分類,然后針對性的對各類數據進行簡化、統一數據格式,再對簡化后的數據采取***的數據處理策略。
對我們數據來說,我們覺得有下面幾種:
- 后臺數據監控,用于微信后臺服務的監控數據。
- 終端數據監控,除了后臺,我們還需要關注終端方面具體的性能、異常監控及網絡異常。
- 對外監控服務,我們現在有商戶和小程序等外部開發者提供的服務,我們及外部服務開發者都需要知道這個服務和我們微信之間有些怎么樣的異常,所以我們還提供了對外的監控服務。
后臺數據監控
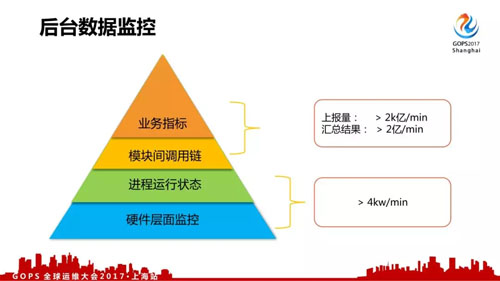
對于我們后臺數據監控來說,我們覺得按層次來說分成四類,每種有不同的格式和上報方式:
- 硬件層面監控,比如服務器負載、CPU、內存、IO、網絡流量等。
- 進程運行狀態,比如說消耗的內存、CPU、IO 等。
- 模塊間調用鏈,各個模塊、機器間的調用信息,是故障定位的關鍵數據之一。
- 業務指標,業務總體層面上的數據監控。
不同類型的數據簡化成如下格式,方便對數據進行處理。其中底下兩層都用 IP+Key 的格式,后來出現了容器后,使用 ContainerID、IP、Key 的格式。
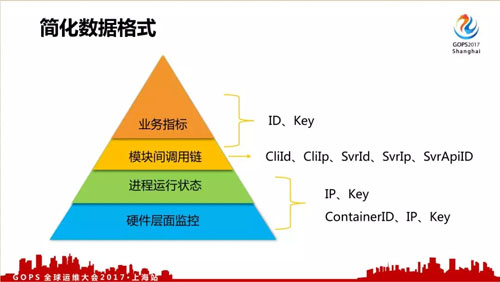
而模塊調用信息,又把模塊的被調總體信息抽出來,跟業務指標共用 ID、Key 的數據格式。
我們重點說一下 IDKey 數據。這個 IDKey 數據是早期的重點監控數據,但其上報量占了數據上報的 9 成以上,像剛才所說,用文本型數據上報難以做到穩定、快速。
所以我們定制了一個非常簡化、快速的上報方式,直接在內存進行快速匯總,具體上報方案可以看下面這個圖。

每個機器里面都申請了兩塊共享內存,有兩塊的原因是方便進行周期性的數據收集(6s 收集一次),每塊內存的格式是:uint32_t[MAX_ID][MAX_KEY]。
我們內部只允許有三種上報方式:
- 累加
- 設置新值
- 設置***值
這三種方式都是操作一個 uint32_t,性能消耗非常小,而且還有一個***的優點,就是實時在內存進行匯總,每次從內存提取的記錄只有平均 1000 條左右,大幅降低秒級統計的難度。
后臺數據里面還有一個重要數據是調用關系數據,在故障分析定位中有非常大的作用。
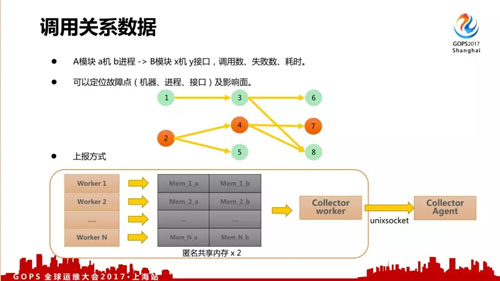
具體格式如上,可以定位故障點(機器、進程、接口)及影響面。它的上報量是小于 IDKey 的第二大數據,每次后臺調用都產生一條數據,所以使用日志方式還是很難處理。
我們在服務內部用了另外一種跟 IDKey 接近的共享內存統計方式,比如說一個服務有 N 個 Worker,每個 Worker 會分配兩塊小共享內存進行上報,再由收集線程對數據打包后對外發送。
這個上報是框架層進行的上報,服務開發者不需要手工增加上報代碼(微信 99% 都是使用內部開發的服務框架)。
終端數據監控
后臺數據我們介紹完了,再說一下終端監控數據。這個我們關注的是手機端的微信 APP 一些具體的性能、異常,調用微信后臺的耗時、異常,還有網絡異常方面的問題。
手機終端產生的日志數據非常巨大,如果全量上報則對終端、后臺都有不小的壓力,所以我們并沒有全量上報。
我們對不同數據、終端版本有不同的采樣配置,后臺會定期對終端下發采樣策略。
終端對數據采樣上報時也不會實時發送,而是用臨時存儲記錄下來,隔一段時間再打包發送,力求對終端的影響最小化。
對外監控服務

下面簡單介紹一下我們***的對外監控服務,這個方案參考了一些云監控的方案,用戶可以自行配置維度信息和配置監控規則。
現在在我們的商戶管理界面還有小程序開發者工具的頁面已經開發了這個功能,但現在自定義上報還沒有開放,只提供了后臺采集的一些固定數據項。
微信數據監控的發展過程
上面介紹了數據的上報方式,接下來介紹一下我們如何對數據進行監控。
異常檢測
對于一般異常檢測來說,可能都會用到三個辦法:
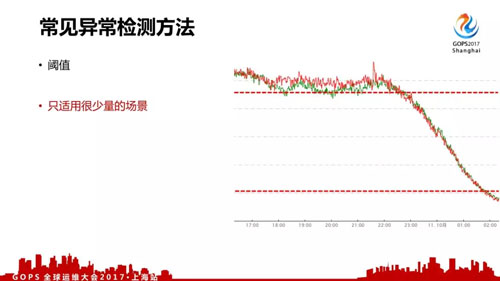
- 閾值,甚至在早上和晚上都是有很大差異的,這個閾值本身沒法去劃分的,所以這個對于我們來說只適用于少量的場景。
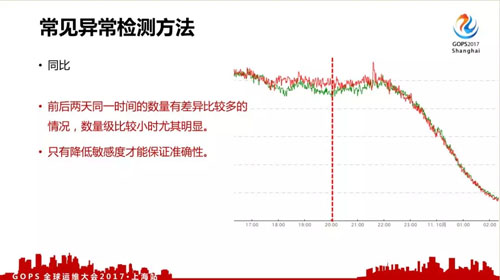
- 同比,存在的問題是我們的數據都不是每天同一時間的數據是一樣的,周一到周六會存在比較大的差異,只能降低敏感度才能保證準確性。
- 環比,我們的數據中,相鄰的數據也并非平穩變化,數量級比較小時尤其明顯,同樣只有降低敏感度才能保證準確性。
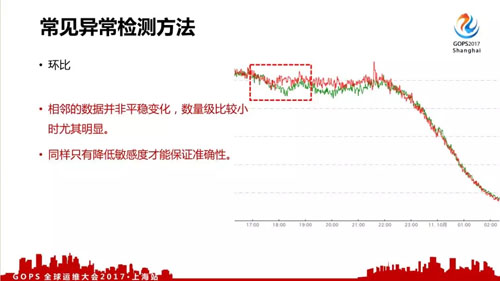
所以這三種常見的數據處理方法都不是很適用我們的場景,在過去我們對算法進行了改進。
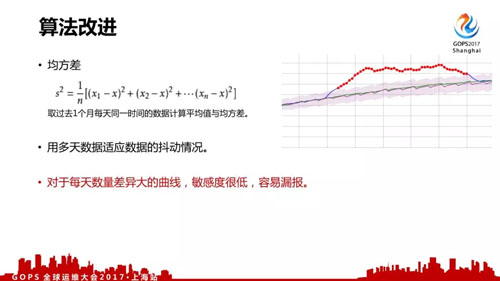
我們使用的***個改進算法是均方差,就是拿過去一個月每天同一時間的數據計算平均值與均方差,用多天數據適應數據的抖動情況。
這個算法適用范圍比較廣,但是對于波動比較大的曲線,敏感度會比較低,容易漏報。
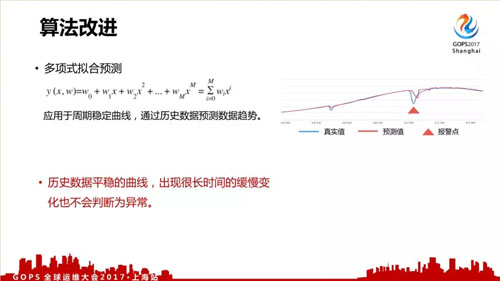
我們改進的第二個算法是多項式擬合預測,適用于平穩的曲線,就有點像改進的環比。
但如果出現異常時數據是平穩增長或減少,沒有出現突變,這時也會判斷為正常,出現漏報。
所以以上兩種算法雖然比以前的算法有了不少改進,但同樣存在一些缺陷。目前我們有在嘗試其他算法,或多種算法結合一起使用。
監控配置
除了算法本身,我們在監控項配置也存在問題的,因為我們的服務非常多。
所以可能超過了 30 萬的監控項要人手配置,每次配置觀察曲線選擇不同算法,不同的敏感度,而且過一段時間之后數據發生變化,需要重新調整。所以這種操作不可持續。
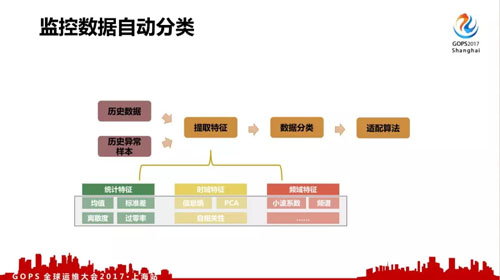
目前我們在嘗試對監控項進行自動配置,比如使用歷史數據,歷史異常樣本,抽取特征,進行數據分類,再自動套用***的監控參數。
這個我們正在嘗試取得了一些成果,但還不是很完善,還在改進中。
海量監控分析下的數據存儲設計思路
上面分享了數據如何進行采集、監控,***再介紹一下數據是怎么存儲的。
對于我們來說數據存儲同樣重要,像剛才提到每分鐘監控要拿一個月數據出來。
還有比如我們的故障分析,一個模塊有異常需要讀取所有機器調用信息、CPU、內存、網絡、各種進程信息等,如果機器數特別多,一次讀取的數據量會超過 50w*2 天。
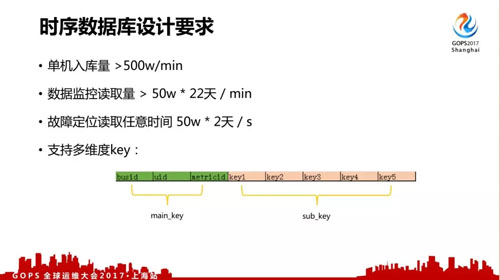
所以我們對監控數據存儲的讀寫性能要求非常高。首先寫入性能基本要求是總入庫量可能一分鐘有 2 億條以上,單機至少要求 500w/min 能入到這個數據量。數據讀取性能需要能支撐每分鐘讀取 50w×22 天的監控讀取。
數據結構上,我們各種數據是多個維度的,比如調用關系的維度非常多,還要支持按 client 端、svr 端、模塊級、主機級等不同維度的部分匹配的查詢,不能只支持簡單的 key —— value 查詢。
注意我們的多維度 key 分成了 main key 和 sub key 兩部分,后面會有介紹為什么這樣做。
以前我們監控數據存儲改造時參考了其他一些開源方案,但在當時沒有找到完全符合性能、數據結構要求的現成方案,所以我們自行研發了自己的時間序列服務器。
首先對數據寫入來說,如果一分鐘一條記錄,則數據量過大,所以我們會先緩存一定時間的數據,隔一段時間批量合并成一天一條記錄。
這也是目前比較常用的提升寫入性能的做法。我們數據緩存的時間是一個小時。
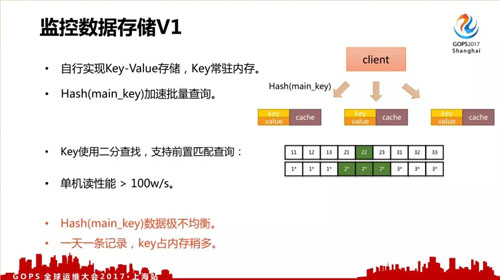
而我們自行開發的 key-value 存儲,關鍵點是 key 的實現。首先 key 會常駐內存。
另外因為數據量很大,一臺機不可能撐得住,所以我們用的是多機集群,使用 hash(main_key)對數據進行寫入和查詢。
而部分匹配查詢是使用改造的二分查找法實現前置匹配查詢。 這樣實現的查詢性能非常高,可以超過 100w/s,而且加個查詢結果緩存性能更高。
不過它也存在一些問題,比如 hash(main_key) 數據不均衡,而且 1 天一條記錄,key 占內存太多。
由于上面的問題,我們做了第二個改進。
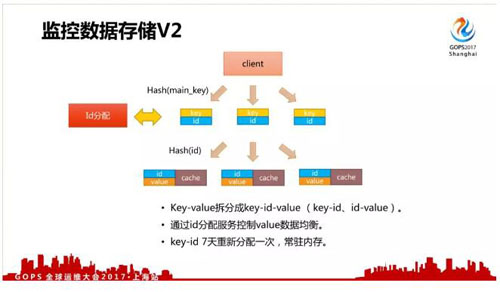
第二個改進的方法是把 Key-Value 拆分成 key-id-value ,通過 id 分配服務控制 value 數據均衡,key-id 7 天重新分配一次,減少內存占用。
對于存儲來說還有一個***的問題就是容災,既然是對服務器進行監控,自身的容災能力要求也非常高。
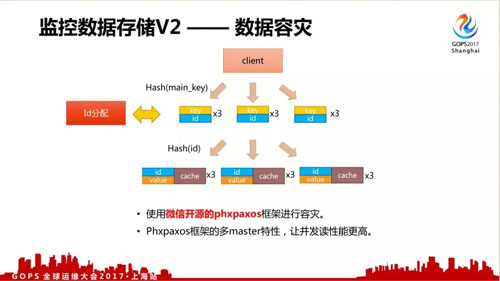
一般來說做到高容災、數據強一致性比較難,但微信后臺已經開源了自行研發的 phxpaxos 協議框架,使用這個框架可以很容易實現數據容災。
另外 phxpaxos 框架的多 master 特性可以提升并發讀取性能。
陳曉鵬,2008 年進入騰訊,2012 年調入微信運維開發組負責運維監控系統的改造,是微信當前運維監控系統的主要設計開發人員。