量子糾纏是啥? 透析量子計算的發展前景和現實
編譯:Zoe Zuo、張南星、元元、Aileen
量子糾纏這兩天忽然火了,還是因為一件與科技互聯網都完全無關的桃色事件。

沒有看懂的同學可自行搜索。
被愛因斯坦稱為“幽靈般的超距作用”的量子糾纏,有沒有可能發生在兩個人類個體身上?量子計算到底有什么神奇之處?
雖然人類歷史上的技術革新幾經波瀾壯闊,依然有一些計算問題在數字革***遺存下來,似乎無法被攻克。受到這些問題的掣肘,科技上的關鍵性突破遲遲不能實現,甚至全球經濟也為此拖累。
在過去的幾十年里,傳統計算機的計算能力和處理速度幾乎每兩年就翻番,但似乎在解決這些一直存在的計算問題上毫無進展。
想知道為什么嗎?你去詢問任何一個計算機科學家,他們大概都會給出這樣的答案:目前的傳統數字計算機都是建立在一個局限性頗多的傳統計算模型上的。放眼長遠,要高效地解決世界上那些最根深蒂固的計算問題,我們必須訴諸一個全新的、更為強大的家伙:量子計算機。
從根本上說,傳統計算機和量子計算機之間的差別并非是一輛舊車和一輛新車的差別,而是一匹馬和一只鷹的差別:前者雖然能跑,但是后者會飛。兩種計算機就是如此迥然不同。在這里,我們要仔細看看關鍵性差異具體體現在何處,深入理解究竟是什么讓量子計算機如此出類拔萃。本文不會告訴你量子計算機最根本的工作原理,因為沒有人真的知道答案。
一、傳統計算機的硬限制
1. 摩爾定律
近幾十年來,傳統計算機的運行速度與計算能力每兩年就翻倍(另一說僅18個月),這就是著名的摩爾定律(Moore's law)。盡管這種驚人的更新速度已經開始放緩,但我們多少可以相信,今天體型龐大的超級計算機會進化成明天物美價廉的筆記本電腦。依照這種發展速度,我們也有理由假定,在可預見的未來,沒有什么計算任務是傳統計算機完成不了的。然而,除非我們所說的未來是指萬億年之后(或者更久),否則我們的假定對于某些棘手的計算任務來說完全不可靠。
2. 傳統計算機的致命弱點
事實上,諸如算出大整數的質因數這樣的計算任務,即使是未來速度最快的傳統計算機也無法完成。背后的原因在于,計算一個數的質因數的復雜度呈指數式增長。什么是指數式增長(exponential growth)?我們得探究一下這個概念,因為這對于我們理解為什么量子計算機潛力巨大而傳統計算機后勁不足至關重要。
3. 指數增長
有些事物是按照固定速度增長的,有些事物則隨著總數量的增加而增長得越來越快。當增長的速度隨著總量逐漸增加而變得更快(而非恒定)時,這一增長就是指數式的。
指數式增長是極其強大的,它最重要的特征之一就是,起初增長緩慢,而后以驚人的方式迅速增長到巨大的總量。
不舉例子的話,這個定義可能有點難以捉摸,所以讓我們先看個小故事吧。
傳說有個國王答應獎勵一個聰明人,這個人便向國王請求獎勵他大米,規則是在棋盤的***個格子上放一粒米,第二個格子上放兩粒米,第三個格子上放四粒米,然后以此類推,每一個格子上的米粒數須是前一個格子上的二倍。國王欣然應允,但很快就意識到,要填滿整個棋盤,所需的大米數量遠遠多于全國大米存量,而且會花掉他所有的財產。

米粒的指數式增長
任何一個方格上的米粒數量都符合以下規則,或者說公式:
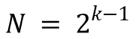
在這個公式里,k指方格的序號,N指該方格上米粒的數量。
- 如果k=1(***個方格),那么N = 2⁰,等于1。
- 如果k=5(第五個方格),那么N = 24,等于16。
這就是指數型增長,因為這里的指數或者說冪是隨著方格的推移而增加的。
為了更進一步解釋這個概念,我作了圖來表示一個指數型函數是如何隨著輸入量的增加而增長的。
,Y坐標軸:百萬")
1的33次倍增
X坐標軸:秒數(=倍增次數),Y坐標軸:百萬
由圖可知,該函數開始時增長相對緩慢,但沒多久就急劇增長到傳統計算機在沒有足夠輸入規模的情況下無法計算出來的數字。
4. 指數增長函數造成的結果
好了,故事就講到這里,我們將目光轉向現實世界中的指數問題,比如我們之前提到的那個問題:質因數分解(prime factorization)。
以數字51為例,看看你多久能找到兩個不同的質數,使得這兩數乘積為51。如果你熟悉這類問題的話,大概只需要幾秒鐘就能想出答案,3和17這兩個質數相乘可得51。
事實證明,這樣看似簡單的過程卻是數字經濟的核心,是最安全的加密算法的基礎。我們之所以在加密中采用這一技術,是因為質因數分解中涉及的數字會越來越大,導致傳統計算機越來越難以分解它們。當數字位數達到一定規模,即使用速度最快的傳統計算機進行分解,也要花費數月、數年、數個世紀、數千年,乃至永遠。
考慮到這點,傳統計算機就算在可預見的未來能夠持續實現運算能力每兩年翻番(當然這不大可能),也永遠無法徹底解決質因數分解的問題。現代科學和數學的一些核心問題同樣棘手,包括分子模擬和數學上的***化問題。任何試圖深入這些問題的超級計算機定會以崩潰告終。
下面是來自IBM Research的一幅精彩插圖,該圖展示了世界上***大的超級計算機所能模擬出的最復雜的分子F團簇(F cluster)。你能發現(在圖片左下方),該分子其實根本不復雜,如果我們想借助模擬更為復雜的分子的方法來尋找更好的藥物療法、研究生物,我們就得另辟蹊徑。

分子模擬問題
圖注:
- Chemistry:化學
- Nitrogenase enzyme…:參與氮氣(N2)轉化為銨根(NH4)過程的固氮酶
- Simulating this cluster…:模擬該簇已經是傳統計算機運算能力的上限
- These regions are…:這些區域參與了不同的反應階段
- Iron sulfide clusters…:不同規模的鐵硫簇(FexSy)
- Fe Protein:鐵蛋白
- MoFe Protein:鉬鐵蛋白
- F cluster:F團簇
- P cluster:P團簇
- S cluster:S團簇
二、走進量子計算機
傳統計算機在嚴格意義上是數碼系統,純粹依賴于傳統計算原理與性質。量子計算機則是嚴格的量子系統,相應地依賴于量子的原理與性質,其中最重要的兩點就是量子疊加(superposition)與量子糾纏(entanglement),它們賦予量子計算機非凡的能力,以解決那些看似無法克服的難題。
1. 量子疊加
要理解疊加的概念,我們先了解最簡單的系統:雙態系統(two-state system)。開/關轉換(On/Off switch)就是一種普通、傳統的雙態系統,它總處于開或者關的狀態。
一個雙態量子系統(two-state quantum system)就完全是另一回事了。當然,無論你何時觀測量子系統的狀態,都會發現它確實處于開或者關的狀態,但是在你沒有觀測時,一個量子系統是有可能處于開關同時存在的疊加狀態的。無論有多么反直覺,甚至超自然,這種狀態確實有可能出現。

量子疊加
一般而言,物理學家認為討論量子系統在受觀測之前的狀態是沒有意義的,比如自旋(spin)狀態。有些人甚至認為,觀測量子系統的行為會導致量子從不確定的模糊狀態坍縮到你測量到的某種值(開或關,向上或向下)。雖然可能無法想象,但不能否認這種神秘的現象不僅真實存在,而且為提高解決問題的能力開辟出一個新維度,也為量子計算機奠定了基礎。記住疊加的概念,我們稍后會介紹疊加是如何運用于量子計算的。
疊加存在的可能性不在本文的討論范圍內,但請相信它確實已經被證實了。如果你想要知道是疊加是如何產生的,你得先了解波粒二象性( Wave/Particle Duality)的概念。
2. 量子糾纏
那么我們繼續談談建造量子計算機所用到的另一個量子原理:量子糾纏。
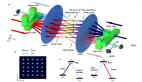
眾所周知,一旦兩個量子系統開始相互作用,它們就會不可救藥的成為糾纏的伙伴。自此,無論兩個系統相距多遠,一個系統的狀態可以準確反映另一個系統的狀態。真的,兩個系統之間即使相距幾光年,它們仍舊能夠及時準確的反映彼此的信息。
這個現象讓愛因斯坦都覺得不可思議。(愛因斯坦對此有個著名的描述,“幽靈般的超距作用”)。我們借由一個實例來展示這個現象。

量子糾纏 (糾纏的量子比特的狀態無法獨立來看)
假設有兩個電子A、B,一旦讓它們以正確的方式相互作用,它們的旋轉就會自動產生糾纏效應。自此,如果A向上旋轉,那么B就會向下旋轉,就像兩個小孩在蹺蹺板兩端一樣。但是A和B即使在地球兩端,亦或是在銀河兩端,也是這樣。無論中間相隔上萬英里、幾光年,A、B的自旋相反已經被證實。但是需注意:這些系統的狀態沒有準確的取值,例如旋轉的方向。它們在被測量之前以一種模糊疊加的方式存在。
所以在兩個系統相隔幾光年遠的情況下,我們測量A的行為是否真的能導致B瞬間坍縮到相反的狀態?如果確實如此,那么我們將面臨另外一個問題:愛因斯坦告訴我們,在兩個系統之間傳遞比如光信號這樣的影響因素不可能超越光速。所以這個現象的根本原因是什么?老實說,我們真不知道。現在唯一已知的就是量子糾纏這個現象是真實存在的,而人類可以利用它創造奇跡。
3. 量子比特
量子計算中量子比特承擔的任務就好比傳統計算機中比特承擔的任務:它是信息的基本單元。但是和量子比特幣相比,比特就是徹頭徹尾的無趣了。雖然在計算過程中,比特和量子比特都有兩個狀態(0或1),但是量子比特在計算結束之前能夠同時處于0或者1的狀態。這聽起來有點像量子疊加對嗎?這確實就是量子疊加。量子比特是量子系統中最突出的一個存在。

經典比特,量子比特
就像傳統計算機建立在一個個比特、開或關的晶體管之上,量子計算機建立在一個個量子比特、上/下旋轉的電子之上(如果能夠觀測到的話)。同樣的,串聯起來的開、關晶體管形成了邏輯閘,以供數字計算機進行傳統方法的運算;而處于上/下旋轉狀態的電子串聯起來,則形成了量子閘以供量子計算機進行量子運算。然而,要把單個電子串聯起來(還有保持它們的旋轉狀態),做起來遠比說起來難。

量子算法
圖注:
- 激發電子分化(通過創建2^n個狀態的平等疊加態來激活機器)
- 問題編碼(利用邏輯閘給問題編碼,把信息寫入2^n個狀態的相和振幅中)
- 開啟運算(通過物理干涉原理,機器放大正確答案的振幅,縮小錯誤答案的振幅,從而得到最終答案。有一些問題需要重復步驟2和3)
三、我們現在走到哪一步了?
在英特爾大量產出承載十多億晶體管高度集成的傳統芯片時,世界上最***的實驗計算機科學家還在努力把一小撮量子比特放到量子計算機的“芯片”上。為了體會出人類在量子計算這條路上還有多遠的路要走,我們看一個例子:IBM最近發布了世界上***的量子計算機,上面驚人地有……50個量子比特。
盡管如此,量子計算機已經啟程,如果量子計算機的發展也遵循諸如摩爾定律之類的定理,那么我們很快就能發明出有好幾百個、甚至是上千個量子比特的“芯片”。十億個?讓我深吸口氣冷靜一下。
但是請注意,量子計算機其實無需這么多量子比特就能夠讓傳統計算機在某些關鍵領域上望塵莫及,例如質數分類,分子建模以及許多傳統計算機無法解決的優化問題。
1. 展望2018
無論如何,就現狀而言,幾乎每一臺量子計算機都是花費上百萬美元,幾乎瘋狂的科學家們通力合作的大項目。一般只有像IBM這樣大型IT公司的研發部門,或者像麻省理工這樣大型研究型大學的實驗物理學專業,才有足夠的能力研究量子計算機。
它們需要在接近于絕對零度的超低溫下工作(這個溫度甚至低于外太空的溫度),并且在過程中需要使用精確頻率的微波來與計算機中的每個量子比特建立聯系。不必說,這種方法難以規模化。但是想想最初傳統計算機所用的真空管也不能規模化,我們不要對初代量子計算機太過苛刻。
2. 路漫漫其修遠兮
之所以量子計算機無法形成主流,***的一個原因就在于***科學家、發明家們還在努力解決錯誤率高、量子比特少的問題。我們解決這兩個問題之后,就可以迅速提高計算機的“量子容量”。這是IBM提出的術語,用來描述每臺量子計算機能進行的有效計算量。
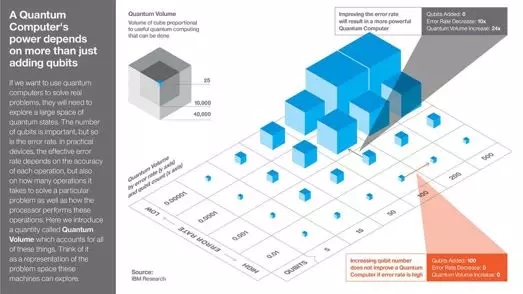
量子計算機的運算能力不只取決于增加量子比特數。量子容量,方塊體積的大小與有效量子計算量成正比。
圖注:
(1) 圖中x坐標軸:量子比特(遞增)
(2) 圖中y坐標軸:誤差率(遞減)
(3) 圖中灰色箭頭:減少誤差率可以提高量子計算機運算能力
- 量子比特增加: 0
- 誤差率減少:10x
- 量子容量增加: 24x
(4) 圖中紅色箭頭:在誤差率高的情況下,提供量子比特數不能提高量子計算機運算能力
- 量子比特增加: 100
- 誤差率減少:0
- 量子容量增加: 0
如果你想要用量子計算機來解決實際問題,它們需要在很大的量子狀態空間中進行搜索。量子比特的數量很重要,誤差率也同樣重要。在實際設備中,誤差率取決于每次操作正確與否,也取決于解決問題所需操作數量,以及處理器如何執行操作。這里我們提出“量子容量”這個數量術語,來整合上文提出的所有因素。可以將這個數量值視為代表機器可以有效搜索的問題域的大小。
簡而言之,想要量子計算真正起飛、量子驅動的Macbook能夠進入大眾生活,我們需要更多的量子比特和更少的錯誤率。這需要一定的時間,但至少我們知道我們的目標,以及我們面臨的障礙。
四、迷思還是解析
雖然量子計算機能夠輕松完成傳統計算機力不能及的事,但其實我們并不知道原理。如果這讓你失望,想想我們確實發明了初代量子計算機,并且牢記這個詞——“量子”。近一個世紀,人類已經利用量子力解決了許多問題,但我們確實不知道它們是如何做到的。
作為量子家族的一份子,量子計算同樣撲朔迷離。《量子計算和量子信息》的作者Michael Nielsen 認為,任何試圖解釋量子計算的嘗試都不可能成功。畢竟,如Nielsen所言,如果能夠有一個直觀的解釋來描述量子計算機是如何工作的(即你能想象出來的),那么傳統計算機也能模仿這個范式。但是如果傳統計算機也能模仿的話,那么這個模型就無法真正準確地描述量子計算機,因為我們對量子計算機的義就是,量子計算機能做到傳統計算機無法做到的事情。
根據Nielsen的解釋,量子并行是目前***的量子計算假說。由于以后你將會聽到很多量子并行的故事,所以暫且就先簡單了解一下。量子并行最基本的一個論點就是,不同與傳統計算機,量子計算機能夠同時讀取所有計算出來的結果(在一個操作指令下),而數字計算機只能一個挨一個的讀取。Nielsen 認為這部分解釋大致合理。
然而,Nielsen極其反對后半段解釋,即量子并行假說認為量子計算機能夠在這所有的結果中選出***的一個。他堅持認為量子計算機在屏幕之下所做到的事情,和其他量子系統一樣,是我們所不可能弄懂的。我們可以看到輸入和輸出,但是中間發生了什么永遠將是謎團。
原文鏈接:
https://towardsdatascience.com/the-need-promise-and-reality-of-quantum-computing-4264ce15c6c0
【本文是51CTO專欄機構大數據文摘的原創譯文,微信公眾號“大數據文摘( id: BigDataDigest)”】