集算示例:10行代碼解決漏斗轉換計算
銷售過程是一個多環節的過程,哪個步驟有了過大瑕疵,都會導致業績急劇下滑。而診斷出哪個步驟有瑕疵,除了無形的經驗,還有量化的診斷方式,就是今天要討論的主角:轉化漏斗模型。
示例數據
為了詳細討論這個漏斗的實現過程,我們舉一個具體的網上商城的例子,被分析的數據也不復雜,只有一個事件表:
用戶ID:用戶編碼
事件ID:事件編碼
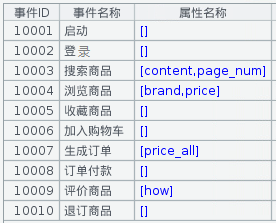
事件屬性:不同事件有不同屬性; json格式,{“content”:”computer”,”page_num”:1}
時間:事件發生的時間
事件類型和事件屬性如下所示
需求定義
目標結果是獲得某個操作流程在每個操作的客戶流失率,如下圖,登錄的用戶有20000人;其中有12000人進行了:登錄->搜索商品;其中有8000人進行了:登錄->搜索商品->查看商品。如下圖所示:
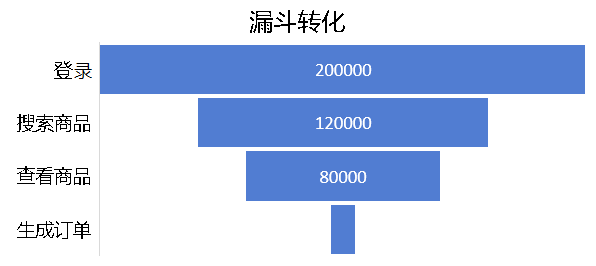
每個事件后都可能流失一些用戶,整個圖示就象一個漏斗形狀,所以被稱為漏斗轉換分析。
我們來研究這個運算的一些需求點:
針對同一個用戶,我們觀察下面這兩組數據,因為事件順序關系,我們認為1000001用戶只發生了登錄行為,而1000002的三個事件符合目標順序,到查看商品事件才流失
| 用戶ID | 事件ID | 事件名稱 | 時間 |
| 1000001 | 10002 | 登錄 | 2017/2/3 0:01 |
| 1000001 | 10004 | 瀏覽產品 | 2017/2/3 0:03 |
| 1000001 | 10003 | 搜索產品 | 2017/2/3 0:08 |
| 1000001 | 10007 | 生成訂單 | 2017/2/3 0:12 |
| 用戶ID | 事件ID | 事件名稱 | 時間 |
| 1000002 | 10002 | 登錄 | 2017/2/3 0:01 |
| 1000002 | 10003 | 搜索產品 | 2017/2/3 0:03 |
| 1000002 | 10004 | 瀏覽產品 | 2017/2/3 0:08 |
上面這些事件,有一些事件有必然的前后關系,比如退訂商品肯定發生在訂單付款之后,訂單付款肯定發生在生成訂單之后;而收藏商品和加入購物車就不一定誰先誰后了,退訂商品前也不一定發生評價商品的事件。這些不穩定性背后隱藏著用戶行為,通過對一組有序事件的漏斗分析,就找到了這組行為用戶在各個階段的流失率。這是***個需求點:事件要順序發生,且能靈活定義。
第二個需求點是能對事件屬性自由定義條件,如brand=’APPLE’,price>10。
第三個需求點是定義時間段,這段時間之外的數據不在考察范圍內,如2017-02-01~2017-02~28。
第四個需求點仍然是和時間有關,窗口時間,只有在窗口時間以內順序發生的事件才符合要求,比如5分鐘、3個自然天;上面圖中的1000002用戶在5分鐘的窗口時間條件下,那只有前兩個事件符合要求,因為瀏覽產品事件遲于登錄7分鐘而超出窗口時間了。
第五個需求點是每個用戶只記錄一次符合要求的最長事件序列。
額外多提一句,現實業務中發生的漏斗分析不一定和上面這些需求細節完全一致,完全有可能更復雜,更個性化,我們這里是為了容易說明問題而假定了這些需求細節。
算法詳述
因為事件要求順序發生,所以我們***步應該把數據先按照時間排序了,這樣同一個窗口期的數據就匯聚到比較集中的一塊了,而且窗口期內數據的位置也能表示先后次序了。數據量大大超出內存,用可以借用集算器的sortx對原始數據游標進行外存排序。
| A | B | |
| 1 | =file(fPath+”event.data”).cursor@t(用戶ID,事件ID,事件屬性,時間) | /以游標方式加載文件數據 |
| 2 | =A1.sortx(時間) | /用時間字段外存排序 |
| 3 | =file(fPath+”eventOrdered.data”).export@b(A2) | /排序結果存入目標文件 |
最終的結果只需要每個用戶最長符合條件的事件序列的長度:代表該用戶發生流失時的***一個事件。因為查找的過程中,不確定哪個事件序列最長,所以聚合信息里會保持住多個事件序列的信息。
events:定義目標事件順序數組:[A,B,C,D,E],事件序號分別為1,2,3,4,5
UserList:定義空序表,每個用戶的信息聚合成一條信息存入這個序表,單個用戶聚合后的信息用JSON格式說明如下
- {
- 用戶ID:1000001
- maxLen當前已找到的***事件序列長度:3
- seqs多個符合要求的事件序列數組:[
- {//***個事件序列
- 該事件序列的開始時間:2017-02-03 21:18:18
- ,該事件序列***事件序號:2
- },
- {//第二個事件序列
- 該事件序列的開始時間:2017-02-04 08:08:08
- ,該事件序列***事件序號:3
- },
- ……
- ]
- }
在定義了上面變量的基礎上,寫段偽代碼來描述算法過程:
- for (按時間排好序的原始數據,循環逐條處理){
- //當前記錄里四個個變量:當前用戶、當前事件、當前時間,當前事件屬性
- if (當前時間不在查詢時間段內 || 當前事件屬性不符合要求) continue;
- if (在UserList里找到當前用戶){
- if (maxLen == events長度) {
- continue; //已經找到當前用戶完整的目標事件序列,不用處理了,直接跳過
- } else {
- if (當前事件 == events***個事件) {
- 新建一個事件序列追加入events。
- } else {
- for(events){
- //變量:事件序列=events [i]
- if (當前事件序號 == 事件序列的***序號+1 AND 當前時間在事件序列的窗口期內 ) {
- 事件序列的***序號增加1
- if(事件序列的***序號>maxLen){
- maxLen增加1
- }
- }
- }
- }
- }
- } else {//沒找到
- 新建當前用戶的聚合信息,然后追加到UserList里
- }
- }
解決方案
- sql或存儲過程。雖然這個計算針對單表,但過程復雜,還對數據有序性有要求,這特點就正好是sql的軟肋。 能用sql寫出來的人,估計是鳳毛麟角,理論上能不能寫出來也存疑。退一步講,即便是寫出來了,性能的可控又是一大難題。反正我是沒有去細研究了,假如有研究出來的同學,可以反饋給我學習下。
- UDF?那相當于直接用高級語言硬編碼了,代碼量可想而知(比如用Java不會少于200行),不光寫出來難度很大,以后再修改維護都是頭疼的事,這種UDF又沒什么通用性,需求變了就得重寫。
- MapReduce以及Spark之類的東西?MapReduce對付這種有序的運算還真不好想。只是這個算法用Scala確實也寫得出來,也不算太長,不過,其中的問題卻是……,算了,這次先不提,以后專門細說,總之Scala是不合適。
- 想要一種能精確描述這個計算過程,并且描述方法符合人類自然思維習慣,并且能清楚知道每個步驟結果,并且能對步驟里的性能優化也能精確控制,并且代碼量不大,并且代碼容易復用……! 這么多貪心的“并且”,那就只能推薦這個專門處理數據的集算器腳本語言了。直接看代碼
| A | B | C | D | E | |
| 1 | >begin=date( string(begin), ”yyyyMMdd”) | >end=date(string(end), ”yyyyMMdd”) | >dateWindow =eval( dateWindow) | ||
| 2 | =create(用戶ID,maxLen, seqs).keys(用戶ID) | =now() | |||
| 3 | =file(fPath+” event30.txt”) .cursor@t() | =A3.select(時間>=begin &&時間<end && events.pos(事件ID)>0 && ${filter}) | |||
| 4 | for C3 | >user=A2.find@b( A4.用戶ID) | |||
| 5 | if user ==null | >if (A4.事件ID ==events(1),A2.insert(,A4.用戶ID:用戶ID,1:maxLen,[[A4.時間,1]]:seqs)) | |||
| 6 | next | ||||
| 7 | if user.maxLen ==events.len() | next | |||
| 8 | for user.seqs | >nextXh=B8(2)+1, time1=long(A4.時間), time2=long(B8(1))+dateWindow, outWindow=time1>time2, nextEvt=A4.事件ID==events(nextXh) |
if(outWindow ||!nextEvt) | next | |
| 9 | >B8(2)=nextXh, if(nextXh>user.maxLen, user.maxLen=nextXh), if(nextXh==events.len(), user.seqs=null) |
next A4 | |||
| 10 | if A4.事件ID ==events(1) | >user.seqs.insert (0,[[A4.時間,1]]), if(user.maxLen==0, user.maxLen=1) |
|||
| 11 | =[A2.len()] | for events.len()-1 | >A11.insert(0,A11(B11)- (A2.select(maxLen==B11).len())) | ||
| 12 | =interval@ms(C2, now()) |
針對單用戶的聚合代碼是第4~10行,規模和上面的偽代碼相當,基本上就是按自然思路去寫出算法。如果用Java類語言起碼是10倍長度了,代碼長了就要翻好幾頁,看到后面就會忘了前面,而集算器的代碼很短,一屏就能呈現出來,整個算法過程一目了然。
如果以前沒接觸過集算器的話,可能會看不懂這些代碼,不過沒關系了,掌握任何一門語言的語法都需要一個學習過程,我稍微解釋一些關鍵點:
變量說明:開始事件begin,結束時間end,窗口期毫秒數dateWindow,目標事件序列events,事件屬性過濾條件filter。
A2:定義一個空序表,也就是偽代碼中的UserList。以用戶ID為主鍵。
A3:定義被分析數據文件的游標,這樣多大的文件都能分批加載入內存進行計算了。
C3:對數據游標進行條件過濾,效果類比SQL語句里的where子句。
A4:從C3游標里循環取數據,每次取一行記錄做處理。
B4:用二分法從UserList里找當前記錄的用戶。
第5、6行:UserList里不存在當前用戶的處理分支,按照主鍵用戶ID順序自動找正確的位置插入。
第7行:當前用戶已經找到完整目標事件序列,直接跳過。
第8~9行:已找到的多個事件序列進行循環處理,試圖把當前用戶信息融入某個符合條件的事件序列。融入成功,跳出到A4執行下一條;融入失敗,執行第10行。
第11行:用UserList計算出每個目標事件存留的用戶數,也就是漏斗需要的各層數據了。
A12:以秒為單位計算出C2執行到A12的耗時。
實現上面這個功能,無論用哪門語言,程序邏輯應該沒多大變化,關鍵就是看方便程度。這段流程還算繁雜的程序,寫完之后執行,只改了兩三處小毛病就跑通了,運行到哪個格子發生什么錯誤;哪個格子運算后的結果是啥都會一目了然。
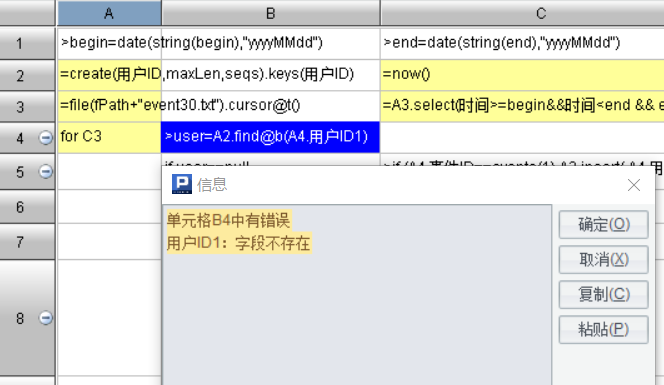
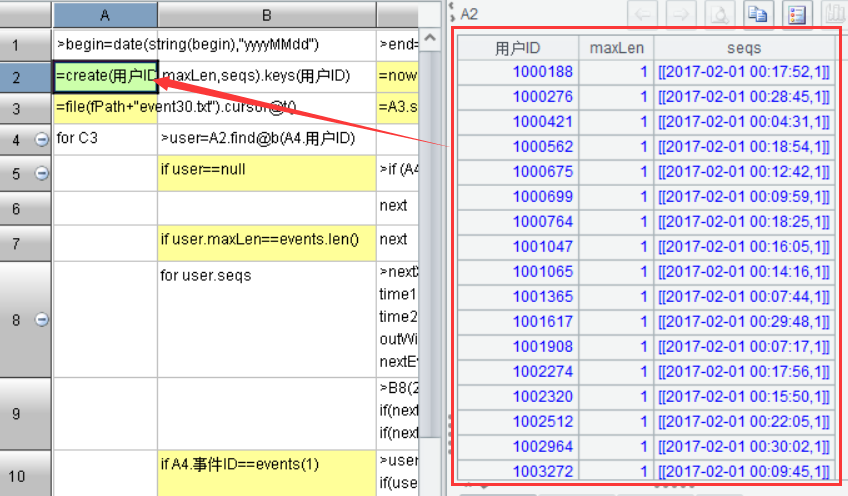
為了驗證這段程序是否正確,只剩下1000001用戶如下的9條數據:
| 用戶ID | 事件ID | 時間 | 事件屬性 |
| 1000001 | 10001 | 2017/2/3 8:11 | {} |
| 1000001 | 10002 | 2017/2/3 8:12 | {} |
| 1000001 | 10003 | 2017/2/3 8:13 | {“content”: “watch”, “page_num”: 3} |
| 1000001 | 10004 | 2017/2/3 8:14 | {“brand”: “Apple”, “price”: 2500} |
| 1000001 | 10005 | 2017/2/3 8:15 | {} |
| 1000001 | 10006 | 2017/2/3 8:16 | {} |
| 1000001 | 10007 | 2017/2/3 8:17 | {“price_all”: 3500} |
| 1000001 | 10008 | 2017/2/3 8:18 | {} |
| 1000001 | 10009 | 2017/2/3 8:19 | {“how”: -1} |
不同條件的執行結果:
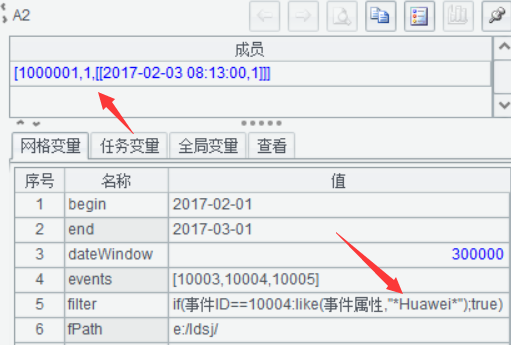
窗口期1分鐘,事件序列[10003,10004,10005],算出來***事件序號是2
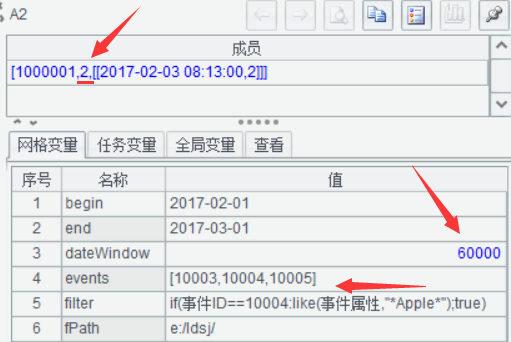
增長窗口期到5分鐘,結果是3,找到了完整的目標事件序列。
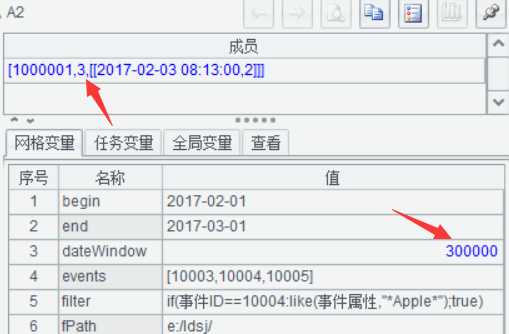
目標事件序列反序[10005,10004,10003]測試,結果是1,因為不存在這種順序。
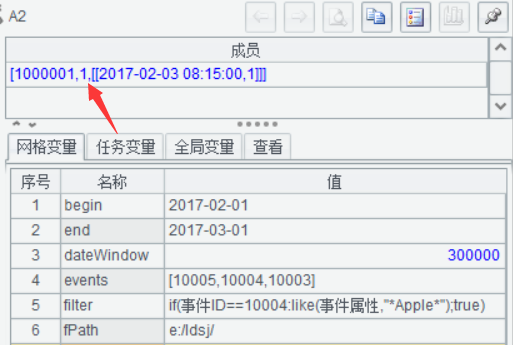
修改事件屬性Huawei,結果同樣為1,因為沒有符合條件的10004事件
結語及預告
6萬條符合條件的記錄,聚合出3萬個用戶的事件數據,耗時1.8秒。目標數據6億條時,性能即便是線性的也需要5個小時,還很可能不是線性的,這就不能容忍了。
理論上能完成的任務在性能不達標的情況下,等同于不能完成。實際上好些生產中的業務就因為耗不起時間和計算資源,不得不作罷。可以預告下我們已經驗證了更多優化辦法,不僅限于修改這段程序的邏輯,還有發生在數據預處理階段的。正是在逐步優化、反復試錯的過程中才真切體會到一個順手工具的重要性。敬請關注!