一種基于詞尾預測的提高英俄翻譯質量的方法
原創【51CTO.com原創稿件】神經網絡翻譯模型受限于其可以使用的詞表大小,經常會遇到詞表無法覆蓋源端和目標端單詞的情況,特別是當處理形態豐富的語言(例如俄語、西班牙語等)的時候,詞表對全部語料的覆蓋度往往不夠,這就導致很多“未登錄詞”的產生,嚴重影響翻譯質量。
已有的工作主要關注在如何調整翻譯粒度以及擴展詞表大小兩個維度上,這些工作可以減少“未登錄詞”的產生,但是語言本身的形態問題并沒有被真正研究和專門解決過。
我們的工作提出了一種創新的方法,不僅能夠通過控制翻譯粒度來減少數據稀疏,進而減少“未登錄詞”,還可以通過一個有效的詞尾預測機制,大大降低目標端俄語譯文的形態錯誤,提高英俄翻譯質量。通過和多個比較有影響力的已有工作(基于subword和character的方法)對比,在5000萬量級的超大規模的數據集上,我們的方法可以成功的在基于RNN和Transformer兩種主流的神經網絡翻譯模型上得到穩定的提升。
研究背景
近年來,神經網絡機器翻譯(Neural Machine Translation, NMT)在很多語種和場景上表現出了明顯優于統計機器翻譯(Statistic Machine Translation, SMT)的效果。神經網絡機器翻譯將源語言句子編碼(encode)到一個隱狀態(hidden state),再從這個隱狀態開始解碼(decode),逐個生成目標語言的譯文詞。NMT系統會在目標端設置一個固定大小的詞表,解碼階段的每一步中,會從這個固定大小的詞表中預測產生一個詞,作為當前步驟的譯文詞。受限于計算機的硬件資源限制,這個詞表往往不會設的很大(一般是3萬-5萬)。并且,隨著詞表的增大,預測的難度也會相應的增加。基于詞(word)的NMT系統經常會遭遇“未登錄詞”(Out of vocabulary, OOV)的問題,特別是目標端是一個形態豐富(Morphologically Rich)的語言時,這個問題會更加嚴重。以“英-俄”翻譯為例,俄語是一種形態非常豐富的語言,一個3-5萬的詞表往往不能覆蓋俄語端的所有詞,會有很多OOV產生。OOV的出現對翻譯質量的影響是比較大的。
針對這個問題,有很多方法嘗試解決。其中一些方法會從翻譯粒度的角度出發(translation granularity),另外還有一些方法嘗試有效的擴展目標端詞表大小。這些方法雖然能有效的將少OOV,但是這些方法并沒有對目標端語言的形態(morphology)進行專門的建模。
對于俄語這種形態豐富的語言,詞干(stem)的個數會比詞的個數少很多,因此很自然的,我們會想到要對詞干和詞尾(suffix)分別進行建模。我們設計實現了一種方法,在解碼時每一個解碼步驟(decoding step)中,分別預測詞干和詞尾。訓練階段,目標語言端會使用兩個序列,分別是詞干序列和詞尾序列。詞干序列和詞尾序列的生成過程如下圖所示:
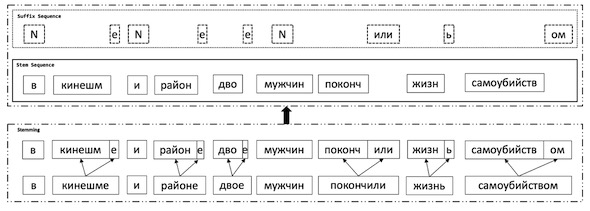
(詞干序列和詞尾序列的生成,“N”表示詞干和詞本身相同,即這個詞沒有詞尾)
通過這種方式,數據稀疏問題會得到緩解,因為詞干的種類會顯著小于詞的種類,而詞尾的種類只有幾百種。
相關工作
基于子詞(subword)的和基于字符(character)的這兩種方法,從調整翻譯粒度的角度出發來幫助緩解目標端形態豐富語言的翻譯問題。一種基于子詞的方法利用BPE(Byte Pari Encoding)算法來生成一個詞匯表。語料中經常出現的詞會被保留在詞匯表中,其他的不太常見的詞則會被拆分成一些子詞。由于少數量的子詞就可以拼成全部不常見的詞,因此NMT的詞表中只保留常見詞和這些子詞就可以了。還有一種基于字符的NMT系統,源端句子和目標端句子都會表示為字符的序列,這種系統對源端形態豐富的語言可以處理的比較好,并且通過在源端引入卷積神經網絡(convolutional neural network, CNN),遠距離的依賴也可以被建模。上述兩種方式雖然可以緩解數據稀疏,但是并沒有專門對語言的形態進行建模,子詞和字符并不是一個完整的語言學單元(unit)。
還有一些研究工作是從如何有效的擴大目標端詞匯表出發的,例如在目標端設置一個很大的詞匯表,但是每次訓練的過程中,只在一個子表上進行預測,這個子表中包含了所有可能出現的譯文詞。這種方法雖然可以解決未登錄詞的問題,但是數據稀疏問題仍然存在,因為低頻的詞是未被充分訓練的。
神經網絡機器翻譯
本文在兩種主要的神經網絡翻譯系統上驗證了“基于詞尾預測”的方法的有效性,分別是基于遞歸神經網絡的機器翻譯(Recurrent Neural Network Based, RNN-based)和谷歌在17年提出的***的神經網絡翻譯模型(Transformer),詳細介紹可以查看相應論文。RNN-based神經網絡機器翻譯如下圖:
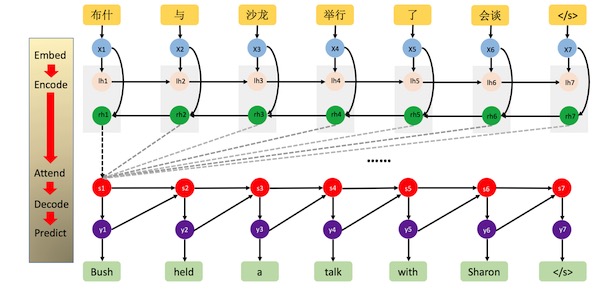
(“Neural Machine Translation by Jointly Learning to Align and Translate”, Bahdanau et al., 2015)
Transformer的結構如下圖:
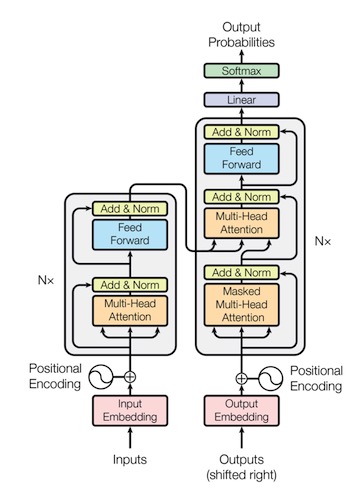
(“Attention Is All You Need”, Ashish Vaswani et al., 2017)
俄語的詞干和詞尾
俄語是一種形態豐富的語言,單復數(number)、格(case)、陰陽性(gender)都會影響詞的形態。以名詞“ball”為例,“ball”是一個中性詞,因此不會隨陰陽性的變化而變化,但當單復數、格變化時,會產生如下多種形態:
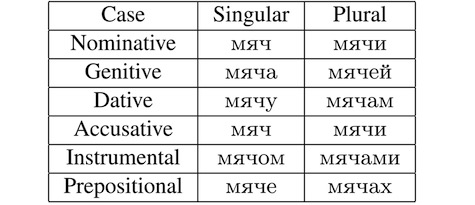
一個俄語詞可以分為兩部分,即詞干和詞尾,詞尾的變化是俄語形態變化的體現,詞尾可以體現俄語的單復數、格、陰陽性等信息。利用一個基于規則的俄語詞干獲取工具,可以得到一個俄語句子中每一個詞的詞干和詞尾。
詞尾預測網絡
在NMT的解碼階段,每一個解碼步驟分別預測詞干和詞尾。詞干的生成和NMT原有的網絡結構一致。額外的,利用當前step生成的詞干、當前decoder端的hidden state和源端的source context信息,通過一個前饋神經網絡(Feedforward neural network)生成當前step的詞尾。網絡結構如下圖:
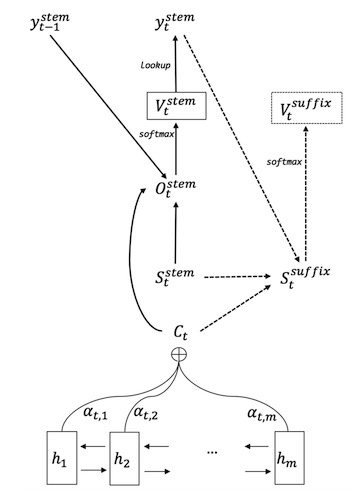
***,將生成的詞干和詞尾拼接在一起,就是當前step的譯文單詞。
實驗
我們在RNN和Transformer上都進行了實驗,在WMT-2017英俄新聞翻譯任務的部分訓練語料(約530萬)上,效果如下圖:

其中,Subword是使用基于子詞方法作為baseline,Fully Character-based是使用基于字符的NMT系統作為baseline。“Suffix Prediction”是我們的系統。
另外,我們還在電子商務領域的數據上,使用超大規模的語料(5000萬),證明了該方法的有效性,實驗結果如圖:

測試集包括商品的標題(Title)、詳情(Description)和用戶評論(Comment)內容,示例如下:
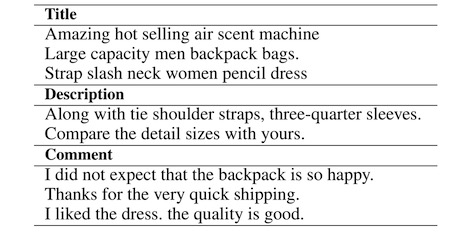
一些翻譯結果的例子:

***個例子中,標號為1和2的俄語詞的形態代表著這個詞是一個反身動詞(reflexive verb),反身動詞的直接賓語和主語是同一個事物,換句話說,反身動詞的施事者和受事者是同一個事物。從源端句子中可以看出,“return”的施事者是購買商品的人,受事者是某個要退還的商品,因此1和2的譯文詞是錯誤的。3的譯文詞是正確的,它的詞尾代表著它是一個不定式動詞(infinitive verb),這個不定式動詞是可以有賓語的。在第二個例子中,標號1和2代表復數形式,4代表單數。第三個例子中,3代表過去時,1和2代表現在時。上面的例子中,相比于基于子詞和基于字符的模型,我們的模型可以產生更正確的俄語形態。
總結
我們提出了一種簡單、有效的方法來提高目標端是形態豐富語言(例如“英-俄”)的NMT系統的翻譯質量。在解碼階段的每一個步驟中,首先生成詞干,然后生成詞尾。我們在兩種NMT模型(RNN-based NMT和Transformer)上,和基于子詞(subword)和字符(character)的方法進行了對比,證明了方法的有效性。我們使用了大規模(530萬)和超大規模(5000萬)的語料,在新聞和電子商務兩個領域上進一步這種方法可以帶來穩定的提升。在我們的工作中,詞尾在NMT中***被專門的建模。
團隊:iDst-NLP-翻譯平臺
作者:宋楷/Kai Song(阿里巴巴), 張岳/Yue Zhang(新加坡科技設計大學), 張民/Min Zhang (蘇州大學), 駱衛華/Weihua Luo(阿里巴巴)
會議:AAAI-18
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】