【深度學習系列】PaddlePaddle之數(shù)據(jù)預處理
上篇文章講了卷積神經(jīng)網(wǎng)絡的基本知識,本來這篇文章準備繼續(xù)深入講CNN的相關知識和手寫CNN,但是有很多同學跟我發(fā)郵件或私信問我關于PaddlePaddle如何讀取數(shù)據(jù)、做數(shù)據(jù)預處理相關的內(nèi)容。網(wǎng)上看的很多教程都是幾個常見的例子,數(shù)據(jù)集不需要自己準備,所以不需要關心,但是實際做項目的時候做數(shù)據(jù)預處理感覺一頭霧水,所以我就寫一篇文章匯總一下,講講如何用PaddlePaddle做數(shù)據(jù)預處理。
PaddlePaddle的基本數(shù)據(jù)格式
根據(jù)官網(wǎng)的資料,總結(jié)出PaddlePaddle支持多種不同的數(shù)據(jù)格式,包括四種數(shù)據(jù)類型和三種序列格式:
四種數(shù)據(jù)類型:
- dense_vector:稠密的浮點數(shù)向量。
- sparse_binary_vector:稀疏的二值向量,即大部分值為0,但有值的地方必須為1。
- sparse_float_vector:稀疏的向量,即大部分值為0,但有值的部分可以是任何浮點數(shù)。
- integer:整型格式
api如下:
paddle.v2.data_type.dense_vector(dim, seq_type=0)
- 說明:稠密向量,輸入特征是一個稠密的浮點向量。舉個例子,手寫數(shù)字識別里的輸入圖片是28*28的像素,Paddle的神經(jīng)網(wǎng)絡的輸入應該是一個784維的稠密向量。
- 參數(shù):
- dim(int) 向量維度
- seq_type(int)輸入的序列格式
- 返回類型:InputType
paddle.v2.data_type.sparse_binary_vector(dim, seq_type=0)
- 說明:稀疏的二值向量。輸入特征是一個稀疏向量,這個向量的每個元素要么是0,要么是1
- 參數(shù):同上
- 返回類型:同上
paddle.v2.data_type.sparse_vector(dim, seq_type=0)
- 說明:稀疏向量,向量里大多數(shù)元素是0,其他的值可以是任意的浮點值
- 參數(shù):同上
- 返回類型:同上
paddle.v2.data_type.integer_value(value_range, seq_type=0)
- 說明:整型格式
- 參數(shù):
- seq_type(int):輸入的序列格式
- value_range(int):每個元素的范圍
- 返回類型:InputType
三種序列格式:
- SequenceType.NO_SEQUENCE:不是一條序列
- SequenceType.SEQUENCE:是一條時間序列
- SequenceType.SUB_SEQUENCE: 是一條時間序列,且序列的每一個元素還是一個時間序列。
api如下:
paddle.v2.data_type.dense_vector_sequence(dim, seq_type=0)
- 說明:稠密向量的序列格式
- 參數(shù):dim(int):稠密向量的維度
- 返回類型:InputType
paddle.v2.data_type.sparse_binary_vector_sequence(dim, seq_type=0)
- 說明:稀疏的二值向量序列。每個序列里的元素要么是0要么是1
- 參數(shù):dim(int):稀疏向量的維度
- 返回類型:InputType
paddle.v2.data_type.sparse_non_value_slot(dim, seq_type=0)
- 說明:稀疏的向量序列。每個序列里的元素要么是0要么是1
- 參數(shù):
- dim(int):稀疏向量的維度
- seq_type(int):輸入的序列格式
- 返回類型:InputType
paddle.v2.data_type.sparse_value_slot(dim, seq_type=0)
- 說明:稀疏的向量序列,向量里大多數(shù)元素是0,其他的值可以是任意的浮點值
- 參數(shù):
- dim(int):稀疏向量的維度
- seq_type(int):輸入的序列格式
- 返回類型:InputType
paddle.v2.data_type.integer_value_sequence(value_range, seq_type=0)
- 說明:value_range(int):每個元素的范圍
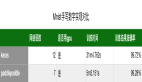
不同的數(shù)據(jù)類型和序列模式返回的格式不同,如下表:

其中f表示浮點數(shù),i表示整數(shù)
注意:對sparse_binary_vector和sparse_float_vector,PaddlePaddle存的是有值位置的索引。例如,
- 對一個5維非序列的稀疏01向量
[0, 1, 1, 0, 0],類型是sparse_binary_vector,返回的是[1, 2]。(因為只有第1位和第2位有值) - 對一個5維非序列的稀疏浮點向量
[0, 0.5, 0.7, 0, 0],類型是sparse_float_vector,返回的是[(1, 0.5), (2, 0.7)]。(因為只有第一位和第二位有值,分別是0.5和0.7)
PaddlePaddle的數(shù)據(jù)讀取方式
我們了解了上文的四種基本數(shù)據(jù)格式和三種序列模式后,在處理自己的數(shù)據(jù)時可以根據(jù)需求選擇,但是處理完數(shù)據(jù)后如何把數(shù)據(jù)放到模型里去訓練呢?我們知道,基本的方法一般有兩種:
- 一次性加載到內(nèi)存:模型訓練時直接從內(nèi)存中取數(shù)據(jù),不需要大量的IO消耗,速度快,適合少量數(shù)據(jù)。
- 加載到磁盤/HDFS/共享存儲等:這樣不用占用內(nèi)存空間,在處理大量數(shù)據(jù)時一般采取這種方式,但是缺點是每次數(shù)據(jù)加載進來也是一次IO的開銷,非常影響速度。
在PaddlePaddle中我們可以有三種模式來讀取數(shù)據(jù):分別是reader、reader creator和reader decorator,這三者有什么區(qū)別呢?
-
reader:從本地、網(wǎng)絡、分布式文件系統(tǒng)HDFS等讀取數(shù)據(jù),也可隨機生成數(shù)據(jù),并返回一個或多個數(shù)據(jù)項。
-
reader creator:一個返回reader的函數(shù)。
-
reader decorator:裝飾器,可組合一個或多個reader。
reader
我們先以reader為例,為房價數(shù)據(jù)(斯坦福吳恩達的公開課第一課舉例的數(shù)據(jù))創(chuàng)建一個reader:
- 創(chuàng)建一個reader,實質(zhì)上是一個迭代器,每次返回一條數(shù)據(jù)(此處以房價數(shù)據(jù)為例)
reader = paddle.dataset.uci_housing.train()
2. 創(chuàng)建一個shuffle_reader,把上一步的reader放進去,配置buf_size就可以讀取buf_size大小的數(shù)據(jù)自動做shuffle,讓數(shù)據(jù)打亂,隨機化
shuffle_reader = paddle.reader.shuffle(reader,buf_size= 100)
3.創(chuàng)建一個batch_reader,把上一步混洗好的shuffle_reader放進去,給定batch_size,即可創(chuàng)建。
batch_reader = paddle.batch(shuffle_reader,batch_size = 2)
這三種方式也可以組合起來放一塊:
reader = paddle.batch(
paddle.reader.shuffle(
uci_housing.train(),
buf_size = 100),
batch_size=2)
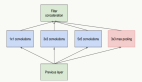
可以以一個直觀的圖來表示:
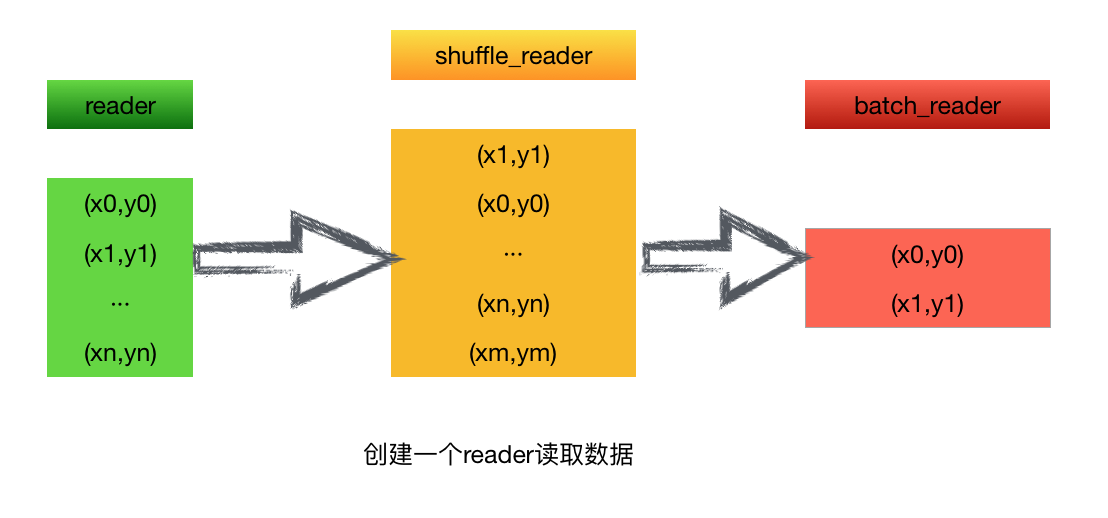
從圖中可以看到,我們可以直接從原始數(shù)據(jù)集里拿去數(shù)據(jù),用reader讀取,一條條灌倒shuffle_reader里,在本地隨機化,把數(shù)據(jù)打亂,做shuffle,然后把shuffle后的數(shù)據(jù),一個batch一個batch的形式,批量的放到訓練器里去進行每一步的迭代和訓練。 流程簡單,而且只需要使用一行代碼即可實現(xiàn)整個過程。
reader creator
如果想要生成一個簡單的隨機數(shù)據(jù),以reader creator為例:
def reader_creator():
def reader():
while True:
yield numpy.random.uniform(-1,1,size=784)
return reader
源碼見creator.py, 支持四種格式:np_array,text_file,RecordIO和cloud_reader
reader decorator
如果想要讀取同時讀取兩部分的數(shù)據(jù),那么可以定義兩個reader,合并后對其進行shuffle。如我想讀取所有用戶對比車系的數(shù)據(jù)和瀏覽車系的數(shù)據(jù),可以定義兩個reader,分別為contrast()和view(),然后通過預定義的reader decorator緩存并組合這些數(shù)據(jù),在對合并后的數(shù)據(jù)進行亂序操作。源碼見decorator.py
data = paddle.reader.shuffle(
paddle.reader.compose(
paddle.reader(contradt(contrast_path),buf_size = 100),
paddle.reader(view(view_path),buf_size = 200),
500)
這樣有一個很大的好處,就是組合特征來訓練變得更容易了!傳統(tǒng)的跑模型的方法是,確定label和feature,盡可能多的找合適的feature扔到模型里去訓練,這樣我們就需要做一張大表,訓練完后我們可以分析某些特征的重要性然后重新增加或減少一些feature來進行訓練,這樣我們有需要對原來的label-feature表進行修改,如果數(shù)據(jù)量小沒啥影響,就是麻煩點,但是數(shù)據(jù)量大的話需要每一次增加feature,和主鍵、label來join的操作都會很耗時,如果采取這種方式的話,我們可以對某些同一類的特征做成一張表,數(shù)據(jù)存放的地址存為一個變量名,每次跑模型的時候想選取幾類特征,就創(chuàng)建幾個reader,用reader decorator 組合起來,最后再shuffle灌倒模型里去訓練。這!樣!是!不!是!很!方!便!
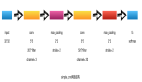
如果沒理解,我舉一個實例,假設我們要預測用戶是否會買車,label是買車 or 不買車,feature有瀏覽車系、對比車系、關注車系的功能偏好等等20個,傳統(tǒng)的思維是做成這樣一張表:
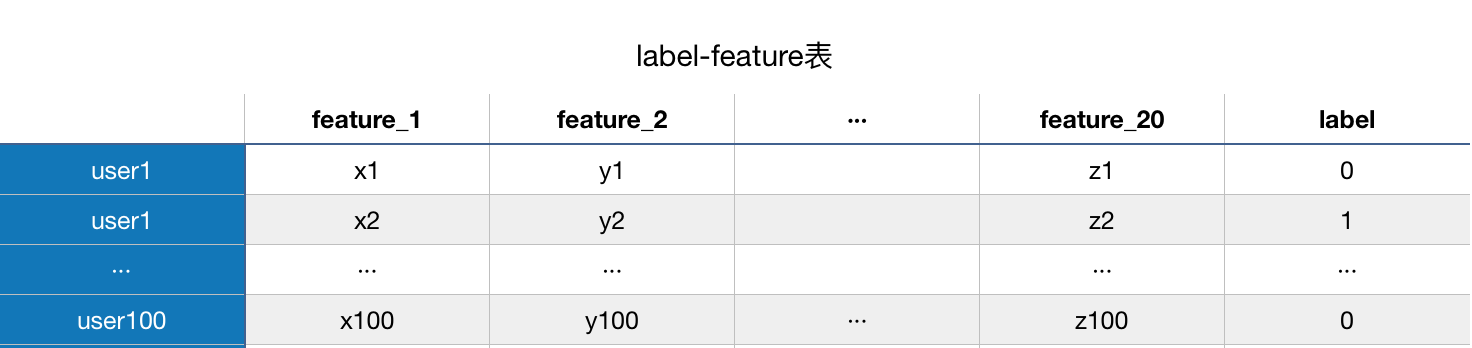
如果想要減少feature_2,看看feature_2對模型的準確率影響是否很大,那么我們需要在這張表里去掉這一列,想要增加一個feature的話,也需要在feature里增加一列,如果用reador decorator的話,我們可以這樣做數(shù)據(jù)集:
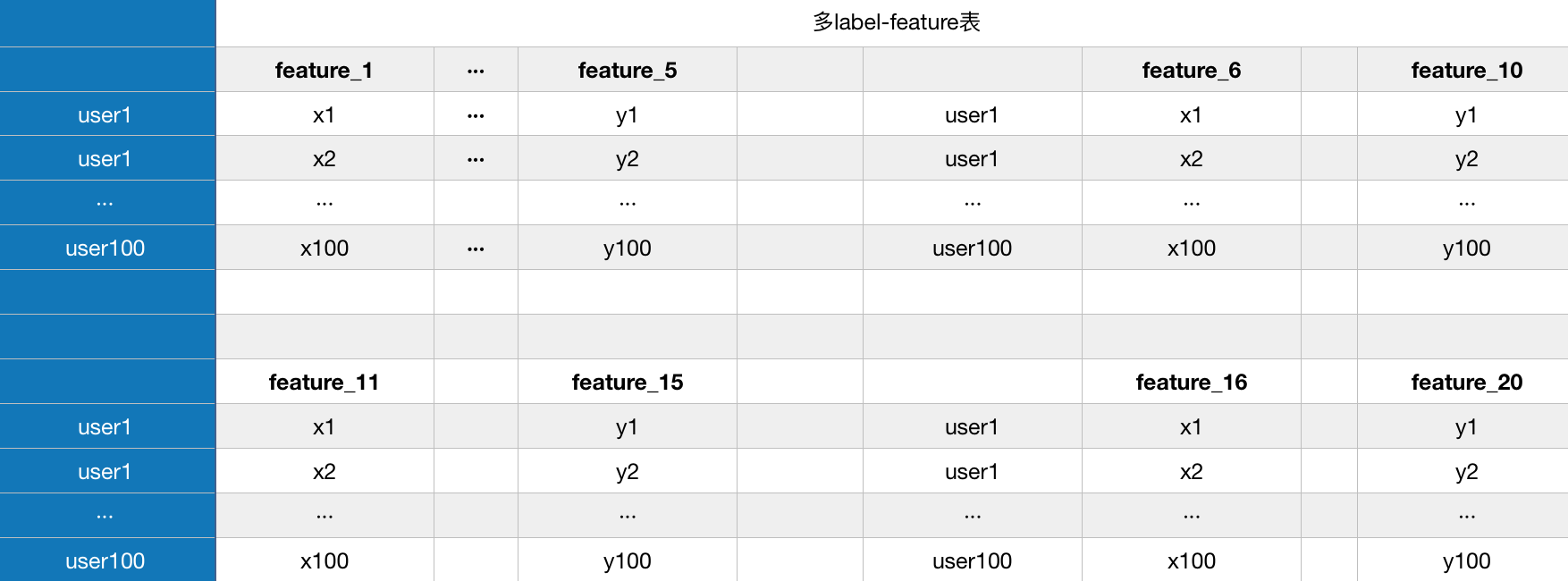
把相同類型的feature放在一起,不用頻繁的join減少時間,一共做四個表,創(chuàng)建4個reador:
data = paddle.reader.shuffle(
paddle.reader.compose(
paddle.reader(table1(table1_path),buf_size = 100),
paddle.reader(table2(table2_path),buf_size = 100),
paddle.reader(table3(table3_path),buf_size = 100),
paddle.reader(table4(table4_path),buf_size = 100),
500)
如果新發(fā)現(xiàn)了一個特征,想嘗試這個特征對模型提高準確率有沒有用,可以再單獨把這個特征數(shù)據(jù)提取出來,再增加一個reader,用reader decorator組合起來,shuffle后放入模型里跑就行了。
PaddlePaddle的數(shù)據(jù)預處理實例
還是以手寫數(shù)字為例,對數(shù)據(jù)進行處理后并劃分train和test,只需要4步即可:
1. 指定數(shù)據(jù)地址
1 import paddle.v2.dataset.common 2 import subprocess 3 import numpy 4 import platform 5 __all__ = ['train', 'test', 'convert'] 6 7 URL_PREFIX = 'http://yann.lecun.com/exdb/mnist/' 8 TEST_IMAGE_URL = URL_PREFIX + 't10k-images-idx3-ubyte.gz' 9 TEST_IMAGE_MD5 = '9fb629c4189551a2d022fa330f9573f3' 10 TEST_LABEL_URL = URL_PREFIX + 't10k-labels-idx1-ubyte.gz' 11 TEST_LABEL_MD5 = 'ec29112dd5afa0611ce80d1b7f02629c' 12 TRAIN_IMAGE_URL = URL_PREFIX + 'train-images-idx3-ubyte.gz' 13 TRAIN_IMAGE_MD5 = 'f68b3c2dcbeaaa9fbdd348bbdeb94873' 14 TRAIN_LABEL_URL = URL_PREFIX + 'train-labels-idx1-ubyte.gz' 15 TRAIN_LABEL_MD5 = 'd53e105ee54ea40749a09fcbcd1e9432'
2. 創(chuàng)建reader creator
1 def reader_creator(image_filename, label_filename, buffer_size):
2 # 創(chuàng)建一個reader
3 def reader():
4 if platform.system() == 'Darwin':
5 zcat_cmd = 'gzcat'
6 elif platform.system() == 'Linux':
7 zcat_cmd = 'zcat'
8 else:
9 raise NotImplementedError()
10
11 m = subprocess.Popen([zcat_cmd, image_filename], stdout=subprocess.PIPE)
12 m.stdout.read(16)
13
14 l = subprocess.Popen([zcat_cmd, label_filename], stdout=subprocess.PIPE)
15 l.stdout.read(8)
16
17 try: # reader could be break.
18 while True:
19 labels = numpy.fromfile(
20 l.stdout, 'ubyte', count=buffer_size).astype("int")
21
22 if labels.size != buffer_size:
23 break # numpy.fromfile returns empty slice after EOF.
24
25 images = numpy.fromfile(
26 m.stdout, 'ubyte', count=buffer_size * 28 * 28).reshape(
27 (buffer_size, 28 * 28)).astype('float32')
28
29 images = images / 255.0 * 2.0 - 1.0
30
31 for i in xrange(buffer_size):
32 yield images[i, :], int(labels[i])
33 finally:
34 m.terminate()
35 l.terminate()
36
37 return reader
3. 創(chuàng)建訓練集和測試集
1 def train(): 2 """ 3 創(chuàng)建mnsit的訓練集 reader creator 4 返回一個reador creator,每個reader里的樣本都是圖片的像素值,在區(qū)間[0,1]內(nèi),label為0~9 5 返回:training reader creator 6 """ 7 return reader_creator( 8 paddle.v2.dataset.common.download(TRAIN_IMAGE_URL, 'mnist', 9 TRAIN_IMAGE_MD5), 10 paddle.v2.dataset.common.download(TRAIN_LABEL_URL, 'mnist', 11 TRAIN_LABEL_MD5), 100) 12 13 14 def test(): 15 """ 16 創(chuàng)建mnsit的測試集 reader creator 17 返回一個reador creator,每個reader里的樣本都是圖片的像素值,在區(qū)間[0,1]內(nèi),label為0~9 18 返回:testreader creator 19 """ 20 return reader_creator( 21 paddle.v2.dataset.common.download(TEST_IMAGE_URL, 'mnist', 22 TEST_IMAGE_MD5), 23 paddle.v2.dataset.common.download(TEST_LABEL_URL, 'mnist', 24 TEST_LABEL_MD5), 100)
4. 下載數(shù)據(jù)并轉(zhuǎn)換成相應格式
1 def fetch(): 2 paddle.v2.dataset.common.download(TRAIN_IMAGE_URL, 'mnist', TRAIN_IMAGE_MD5) 3 paddle.v2.dataset.common.download(TRAIN_LABEL_URL, 'mnist', TRAIN_LABEL_MD5) 4 paddle.v2.dataset.common.download(TEST_IMAGE_URL, 'mnist', TEST_IMAGE_MD5) 5 paddle.v2.dataset.common.download(TEST_LABEL_URL, 'mnist', TRAIN_LABEL_MD5) 6 7 8 def convert(path): 9 """ 10 將數(shù)據(jù)格式轉(zhuǎn)換為 recordio format 11 """ 12 paddle.v2.dataset.common.convert(path, train(), 1000, "minist_train") 13 paddle.v2.dataset.common.convert(path, test(), 1000, "minist_test")
如果想換成自己的訓練數(shù)據(jù),只需要按照步驟改成自己的數(shù)據(jù)地址,創(chuàng)建相應的reader creator(或者reader decorator)即可。
這是圖像的例子,如果我們想訓練一個文本模型,做一個情感分析,這個時候如何處理數(shù)據(jù)呢?步驟也很簡單。
假設我們有一堆數(shù)據(jù),每一行為一條樣本,以 \t 分隔,第一列是類別標簽,第二列是輸入文本的內(nèi)容,文本內(nèi)容中的詞語以空格分隔。以下是兩條示例數(shù)據(jù):
positive 今天終于試了自己理想的車 外觀太騷氣了 而且中控也很棒 negative 這臺車好貴 而且還費油 性價比太低了
現(xiàn)在開始做數(shù)據(jù)預處理
1. 創(chuàng)建reader
1 def train_reader(data_dir, word_dict, label_dict):
2 def reader():
3 UNK_ID = word_dict["<UNK>"]
4 word_col = 0
5 lbl_col = 1
6
7 for file_name in os.listdir(data_dir):
8 with open(os.path.join(data_dir, file_name), "r") as f:
9 for line in f:
10 line_split = line.strip().split("\t")
11 word_ids = [
12 word_dict.get(w, UNK_ID)
13 for w in line_split[word_col].split()
14 ]
15 yield word_ids, label_dict[line_split[lbl_col]]
16
17 return reader
返回類型為: paddle.data_type.integer_value_sequence(詞語在字典的序號)和 paddle.data_type.integer_value(類別標簽)
2. 組合讀取方式
1 train_reader = paddle.batch( 2 paddle.reader.shuffle( 3 reader.train_reader(train_data_dir, word_dict, lbl_dict), 4 buf_size=1000), 5 batch_size=batch_size)
完整的代碼如下(加上了劃分train和test部分):
1 import os
2
3
4 def train_reader(data_dir, word_dict, label_dict):
5 """
6 創(chuàng)建訓練數(shù)據(jù)reader
7 :param data_dir: 數(shù)據(jù)地址.
8 :type data_dir: str
9 :param word_dict: 詞典地址,
10 詞典里必須有 "UNK" .
11 :type word_dict:python dict
12 :param label_dict: label 字典的地址
13 :type label_dict: Python dict
14 """
15
16 def reader():
17 UNK_ID = word_dict["<UNK>"]
18 word_col = 1
19 lbl_col = 0
20
21 for file_name in os.listdir(data_dir):
22 with open(os.path.join(data_dir, file_name), "r") as f:
23 for line in f:
24 line_split = line.strip().split("\t")
25 word_ids = [
26 word_dict.get(w, UNK_ID)
27 for w in line_split[word_col].split()
28 ]
29 yield word_ids, label_dict[line_split[lbl_col]]
30
31 return reader
32
33
34 def test_reader(data_dir, word_dict):
35 """
36 創(chuàng)建測試數(shù)據(jù)reader
37 :param data_dir: 數(shù)據(jù)地址.
38 :type data_dir: str
39 :param word_dict: 詞典地址,
40 詞典里必須有 "UNK" .
41 :type word_dict:python dict
42 """
43
44 def reader():
45 UNK_ID = word_dict["<UNK>"]
46 word_col = 1
47
48 for file_name in os.listdir(data_dir):
49 with open(os.path.join(data_dir, file_name), "r") as f:
50 for line in f:
51 line_split = line.strip().split("\t")
52 if len(line_split) < word_col: continue
53 word_ids = [
54 word_dict.get(w, UNK_ID)
55 for w in line_split[word_col].split()
56 ]
57 yield word_ids, line_split[word_col]
58
59 return reader
總結(jié)
這篇文章主要講了在paddlepaddle里如何加載自己的數(shù)據(jù)集,轉(zhuǎn)換成相應的格式,并劃分train和test。我們在使用一個框架的時候通常會先去跑幾個簡單的demo,但是如果不用常見的demo的數(shù)據(jù),自己做一個實際的項目,完整的跑通一個模型,這才代表我們掌握了這個框架的基本應用知識。跑一個模型第一步就是數(shù)據(jù)預處理,在paddlepaddle里,提供的方式非常簡單,但是有很多優(yōu)點:
- shuffle數(shù)據(jù)非常方便
- 可以將數(shù)據(jù)組合成batch訓練
- 可以利用reader decorator來組合多個reader,提高組合特征運行模型的效率
- 可以多線程讀取數(shù)據(jù)
而我之前使用過mxnet來訓練車牌識別的模型,50w的圖片數(shù)據(jù)想要一次訓練是非常慢的,這樣的話就有兩個解決方法:一是批量訓練,這一點大多數(shù)的框架都會有, 二是轉(zhuǎn)換成mxnet特有的rec格式,提高讀取效率,可以通過im2rec.py將圖片轉(zhuǎn)換,比較麻煩,如果是tesnorflow,也有相對應的特定格式tfrecord,這幾種方式各有優(yōu)劣,從易用性上,paddlepaddle是比較簡單的。
這篇文章沒有與上篇銜接起來,因為看到有好幾封郵件都有問怎么自己加載數(shù)據(jù)訓練,所以就決定插入一節(jié)先把這個寫了。下篇文章我們接著講CNN的進階知識。下周見^_^!
參考文章:
1.官網(wǎng)說明:
http://doc.paddlepaddle.org/develop/doc_cn/getstarted/concepts/use_concepts_cn.html