













使用 paddle來進行文本生成
paddle 簡單介紹
paddle 是百度在2016年9月份開源的深度學習框架。
就我最近體驗的感受來說的它具有幾大優(yōu)點:
1. 本身內(nèi)嵌了許多和實際業(yè)務非常貼近的模型比如個性化推薦,情感分析,詞向量,語義角色標注等模型還有更多實際已經(jīng)內(nèi)嵌了但是目前還沒有出現(xiàn)在官方文檔上的模型比如物體檢測,文本生成,圖像分類,ctr預估等等,可以快速應用到項目中去
2. 就實際體驗來看,訓練的速度相比于調(diào)用keras,在同等數(shù)據(jù)集上和相同網(wǎng)絡架構上要快上不少。當然也是因為keras本身也是基于在tensorflow或者theano上面的,二次調(diào)用的速度不如paddle直接調(diào)用底層迅速。
缺點也有很多:
1. 一開始的安裝對新手極其的不友好,使用docker安裝感覺這個開源框架走不長久,所幸這個問題已經(jīng)解決。
2. 目前很多的文檔并不完善,也許百度系的工程師目前對這方面其實并不是很重視,新手教程看起來并非那么易懂。
3. 層的封裝并不到位,很多神經(jīng)網(wǎng)絡層得自己去寫,感覺非常的不方便。
***希望借由本文,可以讓你快速上手paddle。
一分鐘安裝paddle
docker 安裝
之前paddle的安裝方式是使用docker安裝,感覺非常的反人類。
安裝命令:
- docker pull paddlepaddle/paddle:latest
pip 安裝
現(xiàn)在已經(jīng)支持pip 安裝了。對(OS: centos 7, ubuntu 16.04, macos 10.12, python: python 2.7.x) 可以直接使用
- pip install paddlepaddle 安裝cpu 版本。
- pip install paddlepaddle-gpu 安裝gpu 版本。
安裝完以后,測試的代碼
- import paddle.v2 as paddle
- x = paddle.layer.data(name='x', type=paddle.data_type.dense_vector(13))
- y = paddle.layer.fc(input=x, size=1, param_attr=paddle.attr.Param(name="fc.w"))
- params = paddle.parameters.create(y)
- print params["fc.w"].shape
當輸出 [13,1],那么恭喜你,已經(jīng)成功安裝了paddle.
遇到的問題
當我在使用pip 安裝方式安裝了gpu版本的paddle以后,遇到了numpy 版本不兼容的問題。解決的辦法是:在把本地的numpy卸載以后,我首先把安裝的paddle卸載了,然后重新再安裝了一遍paddle。這樣在安裝的過程當中,可以借由paddle的安裝過程來檢測你系統(tǒng)的其他python包是否符合paddle需要的環(huán)境。其他類似的python包的問題,都可以借由這個辦法幫忙解決。
使用paddle中的循環(huán)神經(jīng)網(wǎng)絡來生成文本
背景簡介
首先paddle實際上已經(jīng)內(nèi)嵌了這個項目:
- https://github.com/PaddlePaddle/models/tree/develop/generate_sequence_by_rnn_lm
文本生成有很多的應用,比如根據(jù)上文生成下一個詞,遞歸下去可以生成整個句子,段落,篇章。目前主流生成文本的方式是使用rnn來生成文本。
主要有兩個原因:
1. 因為RNN 是將一個結構反復使用,即使輸入的文本很長,所需的network的參數(shù)都是一樣的。
2. 因為RNN 是共用一個結構的,共用參數(shù)的。可以用比較少的參數(shù)來訓練模型。這樣會比較難訓練,但是一旦訓練好以后,模型會比較難overfitting,效果也會比較好。
對于RNN使用的這個結構,由于原生的RNN的這個結構本身無法解決長程依賴的問題,目前主要使用Lstm 和GRU來進行代替。但是具體到LSTM 和GRU,因為LSTM需要使用三個門結構也就是通常所說的遺忘門,更新門,輸出門。而GRU的表現(xiàn)和LSTM類似,卻只需要兩個門結構。訓練速度更快,對內(nèi)存的占用更小,目前看起來使用GRU是更好的選擇。
項目實戰(zhàn)
- 首先
到本地model 目錄下
- git clone https://github.com/PaddlePaddle/models/tree/develop/generate_sequence_by_rnn_lm
- 代碼結構如下
- .
- ├── data
- │ └── train_data_examples.txt # 示例數(shù)據(jù),可參考示例數(shù)據(jù)的格式,提供自己的數(shù)據(jù)
- ├── config.py # 配置文件,包括data、train、infer相關配置
- ├── generate.py # 預測任務腳本,即生成文本
- ├── beam_search.py # beam search 算法實現(xiàn)
- ├── network_conf.py # 本例中涉及的各種網(wǎng)絡結構均定義在此文件中,希望進一步修改模型結構,請修改此文件
- ├── reader.py # 讀取數(shù)據(jù)接口
- ├── README.md
- ├── train.py # 訓練任務腳本
- └── utils.py # 定義通用的函數(shù),例如:構建字典、加載字典等
運行說明
- 首先執(zhí)行python train.py 開始訓練模型,待模型訓練完畢以后。
- 執(zhí)行python generate.py 開始運行文本生成代碼。(默認的文本輸入為data/train_data_example.txt,生成文本保存為data/gen_result.txt)
代碼解析
- paddle 的使用有幾個固定需要遵守的流程。
- 大致需要4步。1:初始化,2:定義網(wǎng)絡結構,3:訓練,4:預測。
- 其中定義網(wǎng)絡結構具體需要定義 1:定義具體的網(wǎng)絡結構,2:定義所需要的參數(shù),3:定義優(yōu)化的方法,4:定義event_handler 打印訓練信息。
- 總體來說,paddle 的代碼上手難度其實對新手挺大的,但思路非常的清晰,耐心閱讀應該可以明白。下面我們具體介紹:
1. 首先需要加載paddle 進行初始化:
import paddle.v2 as paddle import numpy as np paddle.init(use_gpu=False)
2. 定義網(wǎng)絡結構
- # 變量說明
- # vocab_dim: 輸入變量的維度數(shù).
- # type vocab_dim: int
- # emb_dim: embedding vector的維度數(shù)
- # type emb_dim: int
- # rnn_type: RNN cell的類型.
- # type rnn_type: int
- # hidden_size: hidden unit的個數(shù).
- # type hidden_size: int
- # stacked_rnn_num: 堆疊的rnn cell的個數(shù).
- # type stacked_rnn_num: int
- # 定義輸入層
- input = paddle.layer.data(
- name="input", type=paddle.data_type.integer_value_sequence(vocab_dim))
- if not is_infer:
- target = paddle.layer.data(
- name="target",
- type=paddle.data_type.integer_value_sequence(vocab_dim))
- # 定義embedding層
- # 該層將上層的輸出變量input 做為本層的輸入灌入embedding層,將輸入input 向量化,方便后續(xù)處理
- input_emb = paddle.layer.embedding(input=input, size=emb_dim)
- # 定義rnn層
- # 如果 rnn_type 是lstm,則堆疊lstm層
- # 如果rnn_type 是gru,則堆疊gru層
- # 如果 i = 0的話,先將 input_emb做為輸入,其余時刻則將上一時刻的rnn_cell作為輸入進行堆疊
- # stack_rnn_num 等于多少就堆疊多少個 rnn層
- if rnn_type == "lstm":
- for i in range(stacked_rnn_num):
- rnn_cell = paddle.networks.simple_lstm(
- input=rnn_cell if i else input_emb, size=hidden_size)
- elif rnn_type == "gru":
- for i in range(stacked_rnn_num):
- rnn_cell = paddle.networks.simple_gru(
- input=rnn_cell if i else input_emb, size=hidden_size)
- else:
- raise Exception("rnn_type error!")
- # 定義全聯(lián)接層
- # 將上層最終定義得到的輸出rnn_cell 做為輸入灌入該全聯(lián)接層
- output = paddle.layer.fc(
- input=[rnn_cell], size=vocab_dim, act=paddle.activation.Softmax())<br data-filtered="filtered">
- # ***一層cost中記錄了神經(jīng)網(wǎng)絡的所有拓撲結構,通過組合不同的layer,我們即可完成神經(jīng)網(wǎng)絡的搭建。
- cost = paddle.layer.classification_cost(input=output, label=target)
paddle的網(wǎng)絡結構從這里可以看出其實定義起來需要自己寫非常多的代碼,感覺非常的冗余,雖然同樣也是搭建積木自上而下一層層來寫,代碼開發(fā)的工作量其實蠻大的。
3. 訓練模型
在完成神經(jīng)網(wǎng)絡的搭建之后,我們首先需要根據(jù)神經(jīng)網(wǎng)絡結構來創(chuàng)建所需要優(yōu)化的parameters(也就是網(wǎng)絡結構的參數(shù)),并創(chuàng)建optimizer(求解網(wǎng)絡結構參數(shù)的優(yōu)化方法比如Sgd,Adam,Rmstrop)之后,我們可以創(chuàng)建trainer來對網(wǎng)絡進行訓練。在這里我們使用adam算法來作為我們優(yōu)化的算法,L2正則項來作為正則項。并根據(jù)cost 中記錄的網(wǎng)絡拓撲結構來創(chuàng)建神經(jīng)網(wǎng)絡所需要的參數(shù)。
- # create optimizer
- adam_optimizer = paddle.optimizer.Adam(
- learning_rate=1e-3,
- regularization=paddle.optimizer.L2Regularization(rate=1e-3),
- model_average=paddle.optimizer.ModelAverage(
- average_window=0.5, max_average_window=10000))
- # create parameters
- parameters = paddle.parameters.create(cost)
- # create trainer
- trainer = paddle.trainer.SGD(
- cost=cost, parameters=parameters, update_equation=adam_optimizer)
其中,trainer接收三個參數(shù),包括神經(jīng)網(wǎng)絡拓撲結構 cost、神經(jīng)網(wǎng)絡參數(shù) parameters以及迭代方程 adam_optimizer。在搭建神經(jīng)網(wǎng)絡的過程中,我們僅僅對神經(jīng)網(wǎng)絡的輸入進行了描述。而trainer需要讀取訓練數(shù)據(jù)進行訓練,PaddlePaddle中通過reader來加載數(shù)據(jù)。
- # define reader
- reader_args = {
- "file_name": conf.train_file,
- "word_dict": word_dict,
- }
- # 讀取訓練數(shù)據(jù)
- train_reader = paddle.batch(
- paddle.reader.shuffle(
- reader.rnn_reader(**reader_args), buf_size=102400),
- batch_size=conf.batch_size)
- # 讀取測試數(shù)據(jù)
- test_reader = None
- if os.path.exists(conf.test_file) and os.path.getsize(conf.test_file):
- test_reader = paddle.batch(
- paddle.reader.shuffle(
- reader.rnn_reader(**reader_args), buf_size=65536),
- batch_size=conf.batch_size)
最終我們可以調(diào)用trainer的train方法啟動訓練:
- # define the event_handler callback
- # event_handler 主要負責打印訓練的進度信息,訓練的損失值,這里可以自己定制
- def event_handler(event):
- if isinstance(event, paddle.event.EndIteration):
- if not event.batch_id % conf.log_period:
- logger.info("Pass %d, Batch %d, Cost %f, %s" % (
- event.pass_id, event.batch_id, event.cost, event.metrics))
- if (not event.batch_id %
- conf.save_period_by_batches) and event.batch_id:
- save_name = os.path.join(model_save_dir,
- "rnn_lm_pass_%05d_batch_%03d.tar.gz" %
- (event.pass_id, event.batch_id))
- with gzip.open(save_name, "w") as f:
- parameters.to_tar(f)
- if isinstance(event, paddle.event.EndPass):
- if test_reader is not None:
- result = trainer.test(reader=test_reader)
- logger.info("Test with Pass %d, %s" %
- (event.pass_id, result.metrics))
- save_name = os.path.join(model_save_dir, "rnn_lm_pass_%05d.tar.gz" %
- (event.pass_id))
- with gzip.open(save_name, "w") as f:
- parameters.to_tar(f)
- # 開始訓練
- trainer.train(
- reader=train_reader, event_handler=event_handler, num_passes=num_passes)
至此,我們的訓練代碼定義結束,開始進行訓練
- python train.py
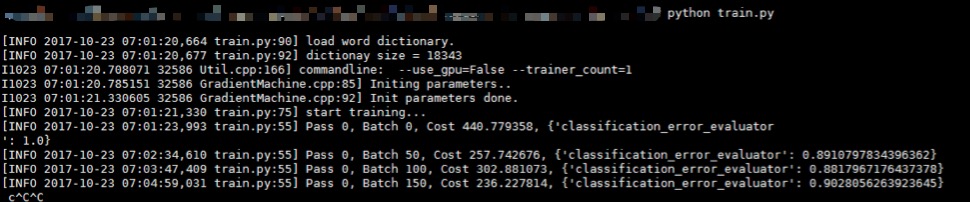
pass 相當于我們平常所使用的 epoch(即一次迭代), batch是我們每次訓練加載的輸入變量的個數(shù),cost 是衡量我們的網(wǎng)絡結構損失函數(shù)大小的具體值,越小越好,***一項 classification_error_evaluator 是表明我們目前的分類誤差的損失率,也是越小越好。
4.生成文本
當?shù)却舾蓵r間以后,訓練完畢以后。開始進行文本生成。
- python generate.py

生成文本展示
- 81 若隱若現(xiàn) 地像 幽靈 , 像 死神
- -12.2542 一樣 。 他 是 個 怪物 <e>
- -12.6889 一樣 。 他 是 個 英雄 <e>
- -13.9877 一樣 。 他 是 我 的 敵人 <e>
- -14.2741 一樣 。 他 是 我 的 <e>
- -14.6250 一樣 。 他 是 我 的 朋友 <e>
其中:
- ***行
81 若隱若現(xiàn) 地像 幽靈 , 像 死神以\t為分隔,共有兩列:- ***列是輸入前綴在訓練樣本集中的序號。
- 第二列是輸入的前綴。
- 第二 ~
beam_size + 1行是生成結果,同樣以\t分隔為兩列:- ***列是該生成序列的對數(shù)概率(log probability)。
- 第二列是生成的文本序列,正常的生成結果會以符號
<e>結尾,如果沒有以<e>結尾,意味著超過了***序列長度,生成強制終止
總結:
我們這次說明了如何安裝paddle。如何使用paddle開始一段項目。總體來說paddle 的文檔目前是非常的不規(guī)范,閱讀的體驗也不是很好,需要開發(fā)者耐心細致的閱讀源代碼來掌握paddle的使用方法。第二很多層的封裝感覺寫法非常的冗余,比如一定要用paddle作為前綴,把python寫出了java的感覺。但是瑕不掩瑜,從使用的角度來看,一旦掌握了其使用方法以后,自己定義網(wǎng)絡結構感覺非常的方便。訓練的速度也是挺快的。



























