在數據庫中存儲一棵樹,實現無限級分類
在一些系統中,對內容進行分類是必需的功能。比如電商就需要對商品做分類處理,以便于客戶搜索;論壇也會分為很多板塊;門戶網站、也得對網站的內容做各種分類。
分類對于一個內容展示系統來說是不可缺少的,本博客也需要這么一個功能。眾所周知,分類往往具有從屬關系,比如鉛筆盒鋼筆屬于筆,筆又是文具的一種,當然鋼筆還可以按品牌來細分,每個品牌下面還有各種系列...
這個例子中從屬關系具有5層,從上到下依次是:文具-筆-鋼筆-XX牌-A系列,但實際中分類的層數卻是無法估計的,比如生物中的界門綱目科屬種有7級。顯然對分類的級數做限制是不合理的,一個良好的分類系統,其應當能實現***級分類。

在寫自己的博客網站時,剛好需要這么一個功能,聽起來很簡單,但是在實現時卻發現,用關系數據庫存儲***級分類并非易事。
1.需求分析
首先分析一下分類之間的關系是怎樣的,很明顯,一個分類下面有好多個下級分類,比如筆下面有鉛筆和鋼筆;那么反過來,一個下級分類能夠屬于幾個上級分類呢?這其實并不確定,取決于如何對類型的劃分。比如有辦公用品和家具,那么辦公桌可以同時屬于這兩者,不過這會帶來一些問題,比如:我要顯示從***分類到它之間的所有分類,那么這種情況下就很難決定辦公用品和家具顯示哪一個,并且如果是多對一,實現上將更加復雜,所以這里還是限定每個分類僅有一個上級分類。
現在,分類的關系可以表述為一父多子的繼承關系,正好對應數據結構中的樹,那么問題就轉化成了如何在數據庫中存儲一棵樹,并且對分類所需要的操作有較好的支持。
對于本博客來說,分類至少需要以下操作:
- 對單個分類的增刪改查等基本操作
- 查詢一個分類的直屬下級和所有下級,在現實某一分類下所有文章時需要使用
- 查詢出由***分類到文章所在分類之間的所有分類,并且是有序的,用于顯示在博客首頁文章的簡介的左下角
- 查詢分類是哪一級的,比如***分類是1,***分類的直屬下級是2,再往下依次遞增
- 移動一個分類,換句話說就是把一個子樹(或者僅單個節點)移動到另外的節點下面,這個在分類結構不合理,需要修改時使用
- 查詢某一級的所有分類
在性能的衡量上,這些操作并不是平等的。查詢操作使用的更加頻繁,畢竟分類不會沒事就改著玩,性能考慮要以查詢操作優先,特別是2和3分別用于搜索文章和在文章簡介中顯示其分類,所以是重中之重。
另外,每個分類除了繼承關系外,還有名字,簡介等屬性,也需要存儲在數據庫中。每個分類都有一個id,由數據庫自動生成(自增主鍵)。
***級多分類多存在于企業應用中,比如電商、博客平臺等,這些應用里一般都有緩存機制,對于分類這種不頻繁修改的數據,即使在底層數據庫中存在緩慢的操作,只要上層緩存能夠***,一樣有很快的響應速度。但是對于抽象的需求:在關系數據庫中存儲一棵樹,并不僅僅存在于有緩存的應用中,所以設計一個高效的存儲方案,仍然有其意義。
下面就以這個賣文具的電商的場景為例,針對這6條需求,設計一個數據庫存儲方案(對過程沒興趣可以直接轉到第4節)。
2.一些常見設計方案的不足
2.1 直接記錄父分類的引用
在許多編程語言中,繼承關系都是一個類僅繼承于一個父類,添加這種繼承關系僅需要聲明一下父類即可,比如JAVA中extends xxx。根據這種思想,我們僅需要在每個分類上添加上直屬上級的id,即可存儲它們之間的繼承關系。
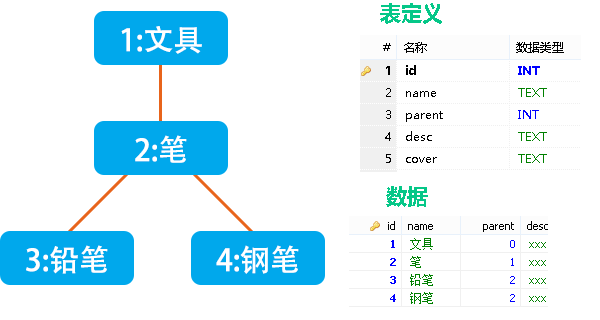
表中parent即為直屬上級分類的id,***分類設為0。這種方案簡單易懂,僅存在一張表,并且沒有冗余字段,存儲空間占用極小,在數據庫層面是一種很好的設計。
那么再看看對操作的支持情況怎么樣,***條單個增改查都是一句話完事就不多說了,刪除的話記得把下級分類的id全部改成被刪除分類的上級分類即可,也就多一個UPDATE。
第二條可就麻煩了,比如我要查文具的下級分類,預期結果是筆、鉛筆、鋼筆三個,但是并沒有辦法通過文具一次性就查到鉛筆盒鋼筆,因為這兩者的關系間接存儲在筆這個分類里,需要先查出直屬下級(筆),才能夠往下查詢,這意味著需要遞歸,性能上一下子就差了很多。
第三條同樣需要遞歸,因為通過一個分類,數據庫中只存儲了其直屬父類,需要通過遞歸到***分類才能獲取到它們之間的所有分類信息。
綜上所述,最關鍵的兩個需求都需要使用性能最差的遞歸方式,這種設計肯定是不行的。但還是繼續看看剩下的幾條吧。
第4個需求:查詢分類是哪一級的?這個還是得需要遞歸或循環,查出所有上級分類的數量即為分類的層級。
移動分類倒是非常簡單,直接更新父id即可,這也是這種方案的唯一優勢了吧...如果你的分類修改比查詢還多不妨就這么做吧。
***一個查詢某一級的所有分類,對于這個設計簡直是災難,它需要先找出所有一級分類,然后循環一遍,找出所有一級分類的子類就是二級分類...如此循環直到所需的級數為之。所以這種設計里,這個功能基本是廢了。
這個方式也是一開始就能想到的,在數據量不大(層級不深)的情況下,因為其簡單直觀的特點,不失為一個好的選擇,不過對于本項目來說還不夠(本項目立志成為***博客平臺!!!)。
2.2 路徑列表
從2.1節中可以看出,__之所以速度慢,就是因為在分類中僅僅存儲了直屬上級的關系,而需求卻要查詢出非直屬上級。__針對這一點,我們的表中不僅僅記錄父節點id,而是將它到***分類之間所有分類的id都保存下來。這個字段所保存的信息就像文件樹里的路徑一樣,所以就叫做path吧。
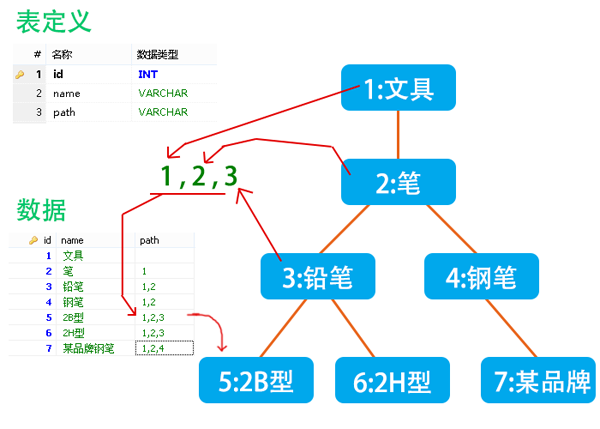
如圖所示,每個分類保存了它所有上級分類的列表,用逗號隔開,從左往右依次是從***分類到父分類的id。
查詢下級時使用Like運算符來查找,比如查出所有筆的下級:
- SELECT id,name FROM pathlist WHERE path LIKE '1,%'
一句話搞定,LIKE的右邊是筆的path字段的值加上模糊匹配,并且左聯接能夠使用索引,的效率也過得去。
查詢筆的直屬下級也同樣可以用LIKE搞定:
- SELECT id,name FROM pathlist WHERE path LIKE '%2'
而找出所有上級分類這個需求,直接查出path字段,然后在應用層里分割一下即可獲得獲得所有上級,并且順序也能保證。
查詢某一級的分類也簡單,因為層級越深,path就越長,使用LENGTH()函數作為條件即可篩選出合適的結果。反過來,根據其長度也能夠計算出分類的級別。
移動操作需要遞歸,因為每一個分類的path都是它父類的path加上父類的id,將分類及其所有子分類的path設為其父類的path并在***追加父類的id即可。
在許多系統中都使用了這種方案,其各方面都具有可以接受的性能,理解起來也比較容易。但是其有兩點不足:1.就是不遵守數據庫范式,將列表數據直接作為字符串來存儲,這將導致一些操作需要在上層解析path字段的值;2.就是字段長度是有限的,不能真正達到***級深度,并且大字段對索引不利。如果你不在乎什么范式,分類層級也遠達不到字段長度的限制,那么這種方案是可行的。
2.3 前序遍歷樹
這是一種在數據庫里存儲一棵樹的解決方案。它的思想不是直接存儲父節點的id,而是以前序遍歷中的順序來判斷分類直接的關系。
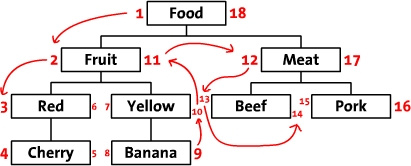
假設從根節點開始以前序遍歷的方式依次訪問這棵樹中的節點,最開始的節點(“Food”)***個被訪問,將它左邊設為1,然后按照順序到了第二個階段“Fruit”,給它的左邊寫上2,每訪問一個節點數字就遞增,訪問到葉節點后返回,在返回的過程中將訪問過的節點右邊寫也寫上數字。這樣,在遍歷中給每個節點的左邊和右邊都寫上了數字。***,我們回到了根節點“Food”在右邊寫上18。下面是標上了數字的樹,同時把遍歷的順序用箭頭標出來了。
我們稱這些數字為左值和右值(如,“Meat”的左值是12,右值是17),這些數字包含了節點之間的關系。因為“Red”有3和6兩個值,所以,它是有擁有1-18值的“Food”節點的后續。同樣的,可以推斷所有左值大于2并且右值小于11的節點,都是有2-11的“Fruit” 節點的后續。這樣,樹的結構就通過左值和右值儲存下來了。
這里就不貼表結構了,這種方式不如前面兩種直觀。效率上,查詢全部下級的需求被很好的解決,而直屬下級也可以通過添加父節點id的parent字段來解決。
因為左值更大右值更小的節點是下級節點,反之左值更小、右值更大的就是上級,故需求3:查詢兩個分類直接的所有分類可以通過左右值作為條件來解決,同樣是一次查詢即可。
添加新分類和刪除分類需要修改在前序遍歷中所有在指定節點之后的節點,甚至包括非父子節點。而移動分類也是如此,這個特性就非常不友好,在數據量大的情況下,改動一下可是很要命的。
查詢某一級的所有分類,和查詢分類是哪一級的,這兩個需求無法解決,只能通過parent字段想***種方式一樣慢慢遍歷。
綜上所述,對于本項目而言,它還不如第二種,所以這個很復雜的方案也得否決掉。
3.新方案的思考
上面幾種方案最接近理想的就是第二種,如果能解決字段長度問題和不符合范式,以及需要上層參與處理的問題就好了。不過不要急,先看看第二種方案的的優缺點的本質是什么。
在分析第二種方案的開頭就提到,要確保效率,必須要在分類的信息中包含所有上級分類的信息,而不能僅僅只含有直屬上級,所以才有了用一個varchar保存列表的字段。但反過來想想,數據庫的表本身不就是用來保存列表這樣結構化數據集合的工具嗎,為何不能做一張關聯表來代替path字段呢?
在路徑列表的設計中,關鍵字段path的本質是存儲了兩種信息:一是所有上級分類的id,二是從***分類到每個父分類的距離。 所以另增一張表,含有三個字段:一個是本分類的所有上級的id,一個是本分類的id,再加上該分類到每個上級分類的距離。這樣這張表就能夠起到與path字段相同的作用,而且還不違反數據庫范式,最關鍵的是它不存在字段長度的限制!
經過一番折騰,終于找到了這個比較***的方案。事實上在之后的查閱資料中,發現這個方案早就在一些系統中使用了,名叫ClosureTable。
4.基于ClosureTable的***級分類存儲
ClosureTable直譯過來叫閉包表?不過不重要,ClosureTable以一張表存儲節點之間的關系、其中包含了任何兩個有關系(上下級)節點的關聯信息
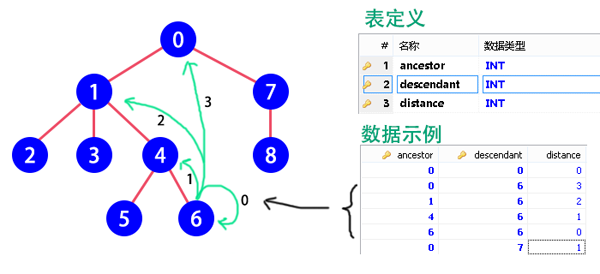
定義關系表CategoryTree,其包含3個字段:
- ancestor 祖先:上級節點的id
- descendant 子代:下級節點的id
- distance 距離:子代到祖先中間隔了幾級
這三個字段的組合是唯一的,因為在樹中,一條路徑可以標識一個節點,所以可以直接把它們的組合作為主鍵。以圖為例,節點6到它上一級的節點(節點4)距離為1在數據庫中存儲為ancestor=4,descendant=6,distance=1,到上兩級的節點(節點1)距離為2,于是有ancestor=1,descendant=6,distance=2,到根節點的距離為3也是如此,***還要包含一個到自己的連接,當然距離就是0了。
這樣一來,不盡表中包含了所有的路徑信息,還在帶上了路徑中每個節點的位置(距離),對于樹結構常用的查詢都能夠很方便的處理。下面看看如何用用它來實現我們的需求。
4.1 子節點查詢
查詢id為5的節點的直屬子節點:
- SELECT descendant FROM CategoryTree WHERE ancestor=5 AND distance=1
查詢所有子節點:
- SELECT descendant FROM CategoryTree WHERE ancestor=5 AND distance>0
查詢某個上級節點的子節點,換句話說就是查詢具有指定上級節點的節點,也就是ancestor字段等于上級節點id即可,第二個距離distance決定了查詢的對象是由上級往下那一層的,等于1就是往下一層(直屬子節點),大于0就是所有子節點。這兩個查詢都是一句完成。
4.2 路徑查詢
查詢由根節點到id為10的節點之間的所有節點,按照層級由小到大排序
- SELECT ancestor FROM CategoryTree WHERE descendant=10 ORDER BY distance DESC
查詢id為10的節點(含)到id為3的節點(不含)之間的所有節點,按照層級由小到大排序
- SELECT ancestor FROM CategoryTree WHERE descendant=10 AND
- distance<(SELECT distance FROM CategoryTree WHERE descendant=10 AND ancestor=3)
- ORDER BY distance DESC
查詢路徑,只需要知道descendant即可,因為descendant字段所在的行就是記錄這個節點與其上級節點的關系。如果要過濾掉一些則可以限制distance的值。
4.3 查詢節點所在的層級(深度)
查詢id為5的節點是第幾級的
- SELECT distance FROM CategoryTree WHERE descendant=5 AND ancestor=0
查詢id為5的節點是id為10的節點往下第幾級
- SELECT distance FROM CategoryTree WHERE descendant=5 AND ancestor=10
查詢層級(深度)非常簡單,因為distance字段就是。直接以上下級的節點id為條件,查詢距離即可。
4.4 查詢某一層的所有節點
查詢所有第三層的節點
- SELECT descendant FROM CategoryTree WHERE ancestor=0 AND distance=3
這個就不詳細說了,非常簡單。
4.5 插入
插入和移動就不是那么方便了,當一個節點插入到某個父節點下方時,它將具有與父節點相似的路徑,然后再加上一個自身連接即可。
所以插入操作需要兩條語句,***條復制父節點的所有記錄,并把這些記錄的distance加一,因為子節點到每個上級節點的距離都比它的父節點多一。當然descendant也要改成自己的。
例如把id為10的節點插入到id為5的節點下方(這里用了Mysql的方言)
- INSERT INTO CategoryTree(ancestor,descendant,distance) (SELECT ancestor,10,distance+1 FROM CategoryTree WHERE descendant=5)
然后就是加入自身連接的記錄。
- INSERT INTO CategoryTree(ancestor,descendant,distance) VALUES(10,10,0)
4.6 移動
節點的移動沒有很好的解決方法,因為新位置所在的深度、路徑都可能不一樣,這就導致移動操作不是僅靠UPDATE語句能完成的,這里選擇刪除+插入實現移動。
另外,在有子樹的情況下,上級節點的移動還將導致下級節點的路徑改變,所以移動上級節點之后還需要修復下級節點的記錄,這就需要遞歸所有下級節點。
刪除id=5節點的所有記錄
- DELETE FROM CategoryTree WHERE descendant=5
然后配合上面一節的插入操作實現移動。具體的實現直接上代碼吧。
ClosureTableCategoryStore.java是主要的邏輯,這里只展示部分代碼
- /**
- * 將一個分類移動到目標分類下面(成為其子分類)。被移動分類的子類將自動上浮(成為指定分類
- * 父類的子分類),即使目標是指定分類原本的父類。
- * <p>
- * 例如下圖(省略***分類):
- * 1 1
- * | / | \
- * 2 3 4 5
- * / | \ move(2,7) / \
- * 3 4 5 ---------------> 6 7
- * / \ / / | \
- * 6 7 8 9 10 2
- * / / \
- * 8 9 10
- *
- * @param id 被移動分類的id
- * @param target 目標分類的id
- * @throws IllegalArgumentException 如果id或target所表示的分類不存在、或id==target
- */
- public void move(int id, int target) {
- if(id == target) {
- throw new IllegalArgumentException("不能移動到自己下面");
- }
- moveSubTree(id, categoryMapper.selectAncestor(id, 1));
- moveNode(id, target);
- }
- /**
- * 將一個分類移動到目標分類下面(成為其子分類),被移動分類的子分類也會隨著移動。
- * 如果目標分類是被移動分類的子類,則先將目標分類(連帶子類)移動到被移動分類原來的
- * 的位置,再移動需要被移動的分類。
- * <p>
- * 例如下圖(省略***分類):
- * 1 1
- * | |
- * 2 7
- * / | \ moveTree(2,7) / | \
- * 3 4 5 ---------------> 9 10 2
- * / \ / | \
- * 6 7 3 4 5
- * / / \ |
- * 8 9 10 6
- * |
- * 8
- *
- * @param id 被移動分類的id
- * @param target 目標分類的id
- * @throws IllegalArgumentException 如果id或target所表示的分類不存在、或id==target
- */
- public void moveTree(int id, int target) {
- /* 移動分移到自己子樹下和無關節點下兩種情況 */
- Integer distance = categoryMapper.selectDistance(id, target);
- if (distance == null) {
- // 移動到父節點或其他無關系節點,不需要做額外動作
- } else if (distance == 0) {
- throw new IllegalArgumentException("不能移動到自己下面");
- } else {
- // 如果移動的目標是其子類,需要先把子類移動到本類的位置
- int parent = categoryMapper.selectAncestor(id, 1);
- moveNode(target, parent);
- moveSubTree(target, target);
- }
- moveNode(id, target);
- moveSubTree(id, id);
- }
- /**
- * 將指定節點移動到另某節點下面,該方法不修改子節點的相關記錄,
- * 為了保證數據的完整性,需要與moveSubTree()方法配合使用。
- *
- * @param id 指定節點id
- * @param parent 某節點id
- */
- private void moveNode(int id, int parent) {
- categoryMapper.deletePath(id);
- categoryMapper.insertPath(id, parent);
- categoryMapper.insertNode(id);
- }
- /**
- * 將指定節點的所有子樹移動到某節點下
- * 如果兩個參數相同,則相當于重建子樹,用于父節點移動后更新路徑
- *
- * @param id 指定節點id
- * @param parent 某節點id
- */
- private void moveSubTree(int id, int parent) {
- int[] subs = categoryMapper.selectSubId(id);
- for (int sub : subs) {
- moveNode(sub, parent);
- moveSubTree(sub, sub);
- }
- }
其中的categoryMapper 是Mybatis的Mapper,這里只展示部分代碼
- /**
- * 查詢某個節點的第N級父節點。如果id指定的節點不存在、操作錯誤或是數據庫被外部修改,
- * 則可能查詢不到父節點,此時返回null。
- *
- * @param id 節點id
- * @param n 祖先距離(0表示自己,1表示直屬父節點)
- * @return 父節點id,如果不存在則返回null
- */
- @Select("SELECT ancestor FROM CategoryTree WHERE descendant=#{id} AND distance=#{n}")
- Integer selectAncestor(@Param("id") int id, @Param("n") int n);
- /**
- * 復制父節點的路徑結構,并修改descendant和distance
- *
- * @param id 節點id
- * @param parent 父節點id
- */
- @Insert("INSERT INTO CategoryTree(ancestor,descendant,distance) " +
- "(SELECT ancestor,#{id},distance+1 FROM CategoryTree WHERE descendant=#{parent})")
- void insertPath(@Param("id") int id, @Param("parent") int parent);
- /**
- * 在關系表中插入對自身的連接
- *
- * @param id 節點id
- */
- @Insert("INSERT INTO CategoryTree(ancestor,descendant,distance) VALUES(#{id},#{id},0)")
- void insertNode(int id);
- /**
- * 從樹中刪除某節點的路徑。注意指定的節點可能存在子樹,而子樹的節點在該節點之上的路徑并沒有改變,
- * 所以使用該方法后還必須手動修改子節點的路徑以確保樹的正確性
- *
- * @param id 節點id
- */
- @Delete("DELETE FROM CategoryTree WHERE descendant=#{id}")
- void deletePath(int id);
5.結語
在分析推論后,終于找到了一種既有查詢簡單、效率高等優點,也符合數據庫設計范式,而且是真正的***級分類的設計。本方案的寫入操作雖然需要遞歸,但相比于前序遍歷樹效率仍高出許多,并且在本博客系統中分類不會頻繁修改。可見對于在關系數據庫中存儲一棵樹的需求,ClosureTable是一種比較***的解決方案。
完整的JAVA實現代碼見 https://github.com/Kaciras/Examples-java/tree/master/ClosureTable