慢SQL,壓垮團隊的最后一根稻草
先說結論,我支持將邏輯寫在 Java 等應用系統中。
背景:
今天只討論一種應用模式,就是最普遍的,前端實時調用后端web服務,服務端經過DB的增刪改查作出響應的應用。至于離線數據分析,在線規則引擎模板執行,流式計算等不在本次討論范疇。
重SQL開發的場景
先看一個例子吧。用經典的 Controller Service DAO 開發模式描述。
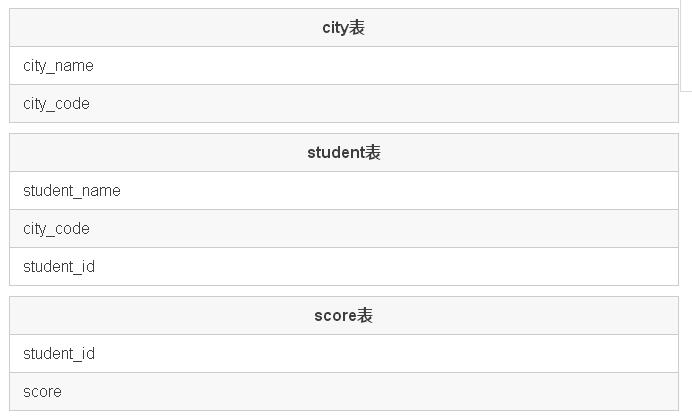
需求:
查詢出每個學生所在的城市名以及分數展示到前端。
重SQL模式
- class Controller{
- Service service;
- Map<String,String> get(Map<String,Object> param){
- return service.get(param);
- }
- }
- class Service{
- DAO dao;
- Map<String,String> get(Map<String,Object> param){
- return dao.get(param);
- }
- }
- class DAO{
- SQLTemplate template;
- Map<String,String> get(Map<String,Object> param){
- String sql = "select city_name,student_name,score from student,score,city where city.city_code=student.city_code and score.student_id=student.student_id" ;
- return template.execute(sql,param);
- }
- }
重Java模式
- class View{
- String studentName;
- String cityName;
- String score;
- }
- class Requent{
- }
- class Controller{
- Service service;
- List<View> get(Requent request){
- return service.get(param);
- }
- }
- class Service{
- StudentDAO studentDAO;
- ScoreDAO scoreDAO;
- CityDAO cityDAO;
- List<View> get(Requent param){
- Student studentRequest = new Student();
- //查詢學生
- List<Student> students = studentDAO.select(studentRequest);
- List<View> result = new ArrayList(students.size());
- for(Student student : students){
- View view = new View();
- view.setStudentName(student.getStudentName());
- //拼接城市名
- City cityRequest = new City();
- cityRequest.setStudentId(student.getStudentId());
- City city = cityDAO.select(cityRequest);
- view.setCityName(city);
- //拼接分數
- Score scoreRequest = new Score();
- scoreRequest.setStudentId(student.getStudentId());
- Score score = scoreDAO.select(scoreRequest);
- view.setScode(score.getScore());
- result.add(view);
- }
- return result;
- }
- }
- class StudentDAO{
- SQLTemplate template;
- Student select(Student param){
- String sql = "select * from Student where param = ...";
- template.select(sql,param);
- }
- }
- class ScoreDAO{
- SQLTemplate template;
- Score select(Score param){
- String sql = "select * from Score where param = ...";
- template.select(sql,param);
- }
- }
- class CityDAO{
- SQLTemplate template;
- City select(City param){
- String sql = "select * from City where param = ...";
- template.select(sql,param);
- }
- }
可以看到,使用重SQL的模式來進行開發確實很快很快,只需要把SQL開發出來基本就完事了,但是看著用重 Java 的模式開發,需要寫一堆的代碼,這么看來好像是 SQL 勝利一籌。
好,PD突然說了,我要把城市名為 “大蕉” 的,分數乘于2展示出來。握草,這個怎么搞??
重SQL模式
- class DAO{
- SQLTemplate template;
- Map<String,String> get(Map<String,Object> param){
- String sql = "select city_name,student_name,CASE WHEN city.city_name='大蕉' THEN 2*score.score ELSE score END score from student,score,city where city.city_code=student.city_code and score.student_id=student.student_id " ;
- return template.execute(sql,param);
- }
- }
好了。。這個SQL已經變得很復雜了基本沒法看了。。
重 Java 模式
- Service.class
- //拼接分數
- Score scoreRequest = new Score();
- scoreRequest.setStudentId(student.getStudentId());
- Score score = scoreDAO.select(scoreRequest);
- if("大蕉".equals(city.getCityName()){
- view.setScode(score.getScore() * 2);
- }else{
- view.setScode(score.getScore());
- }
咦好像改動也不多嘛。
這時候PD又來了我要把城市名為 “大蕉” ,并且城市Code小于10086的,分數乘于2展示出來。握草,完蛋了,之前全是SQL,這個需求要怎么搞??繼續疊加上去繼續 CASE WHEN?
還沒想清楚呢,突然 DBA 電話飛過來了,兄dei你的SQL太慢了,現在把整個庫拖垮了,你是不是沒有加索引?
我:索引加了啊。。。難道是沒走到?那是先解決慢SQL還是先開發需求呢?拆庫是不可能了,邏輯這么死鬼復雜拆庫完全沒法跑啊,加CPU加內存啊 DBA大佬!!!
[DBA日報] 慢SQL 180+,已解決10。
又上了一個版本
[DBA日報] 慢SQL 200+,已解決15。
又上了一個版本
[DBA日報] 慢SQL 250+,已解決30。
慢慢的,開發和運營和DBA每天都疲勞于監控這些SQL。。。。
前言
觀察了一下,傳統企業以及絕大部分轉型中的企業的 Java 應用中,很神奇的是,他們的開發人員包括我自己以前,大家都非常非常希望使用一個 SQL 來完成所有的邏輯的編寫,非常多企業更是把數據庫的存儲過程和數據庫自定義函數來完成。
這些關于邏輯應該寫在哪里的爭論從來沒有停止過,不僅僅發生在后端和數據庫端,連前后端都經常會發生這種爭論,現在只討論后端和數據庫端的糾結。
我將從這五個方面分別對比一下兩種模式的異同。
- 出現場景
- 開發效率
- 缺陷排查
- 架構升級
- 系統維護
出現場景
SQL
我們絕大多數的歷史代碼都是用存儲過程來實現的啊,如果有新需求不往上面做的話,很難兼容原來的邏輯啊啊。
前面的人呢是這樣寫的,我來了看大家都這樣寫就這樣寫了。
Java
新應用嘛,我想怎么樣寫就怎樣寫。
監控和埋點寫起來簡單吖,排查問題可方便了。
前面的人呢是這樣寫的,我來了看大家都這樣寫就這樣寫了。
開發效率
SQL
這樣寫起來很快啊,而且寫 Java 代碼多難受啊,寫 SQL 我自己在數據庫開發環境跑一下結果正確我就直接丟到代碼中提交了,多爽啊。
老實說,這樣子確實會提高開發的效率,因為不用寫那么多查庫聚合的操作,一切都在 SQL 中搞定了。另一方面來看,這確實會讓 Java 代碼看起來很雞肋,好像只是把數據從 web 層到數據層的一個管道而已,一切 if else 能寫在 SQL 中的都寫在 SQL 中了。
但是新需求來或者需求變更的時候,我經常要重新寫SQL,如果變動不多我可能要改動到原來的 SQL,但是我又不敢改,所以只好 copy 重新寫一個,改 SQL 的風險好大,一報錯又要重啟好難受。
Java
一次要寫N個類,有點煩。
新需求來或者需求變更的時候,如果邏輯比較復雜,我直接抽成方法或者改成一些設計模式,維護起來效率還是可以接受的。
缺陷排查
SQL
開發排查問題的時候,除了看日志,直接把SQL和參數丟到 PL/SQL 或者 其他工具里跑一下,基本就能知道數據問題出現在哪了。測試同學在進行測試的時候,如果發現有不對的東西,直接跟開發同學一樣的思路,把SQL 跑一下,問題基本就定位得七七八八了。
但是呢,一旦遇到跑 SQL 無法一眼看出問題的 bug 或者 SQL 實在是太長太長了的的時候,就蒙圈了。我曾經就維護了一個幾千行的存儲過程,一旦發生問題,排查問題的過程巨艱難。但是呢直接用一個數據庫一個功能搞定所有功能未嘗不是一件很爽的事情,因為關系型數據庫實在是實在是太太太穩定了,一次編寫***運行。
Java
看日志看監控。
根據報錯的代碼位置 check 一下代碼邏輯。
一些入參分支肉眼 check 不出來,只能遠程 debug 慢慢看數據流向。
測試的同學基本無法幫忙 check 缺陷,只能靠程序的表現來判斷。
架構升級
SQL
SQL 慢沒關系,它穩定啊,慢就把機器垂直擴展一下好啦,加cpu,加內存,換SSD,加加加絕對可以解決事情的。
SQL 有各種索引和優化策略,說不定跑起來比我們自己寫邏輯還快呢。
加加加,加內存加cpu垂直升級。也沒有其他招數了,除了前置緩存,但是如果查詢都很個性化SQL很復雜,前置緩存也基本沒啥亂用。。。
如果你的邏輯全部寫在 SQL 中,那完蛋了,你這個表基本就沒法分表了,因為你的業務邏輯跟數據庫的數據完整性是強耦合的,需要一切數據基本都在一個數據庫中,這是一件很難受很難受的事情,不信你去問問那些所有業務邏輯全寫在 SQL 中的小伙。
數據庫中非常復雜的表關聯會極大程度拖慢數據庫處理每條 SQL 的平均時間,極大程度拖慢數據庫 RT,降低了數據庫的 RT ,如果邏輯都寫在 SQL 中,那么只能進行垂直升級。因為一旦進行水平擴展,那么多機器的非常復雜的分布式表關聯,RT 基本不是一個高并發的業務應用的能容忍的。
Java
如果是數據庫瓶頸,加數據庫機器,分庫分表一下,應用層基本不用改,在DAO層進行路由一下。
如果是服務器cpu瓶頸,多加幾臺機器就好了。
如果還有瓶頸,增加一下查詢緩存。
在應用快速發展的過程中一般都會分庫分表的拆分或者自動水平擴展,這時候其實只需要數據庫層面做好自己的數據遷移和同步就好了,對于業務層來說是完全無感知的。即使業務非常非常復雜,需要拆應用,其實也非常簡單,只需要把對應的 DAO 層的操作拆分出去,換成 RPC 或者其他方式的調用就好了。
系統維護
SQL
舊SQL完全不敢動,來一個需求加一個 SQL。
慢SQL日益增加,應對疲乏。
Java
SQL寫完一次基本不用動,來一個需求加一個方法聚合一下數據操作即可。
應用維護比較簡單,只要監控做好了,定位到問題基本都能很快解決。
邏輯越來越復雜,沒有好的開發框架的話,代碼維護起來也是挺要命,因為完全不知道跑哪個分支去了。但是現在已經有很多優秀的開源框架來更好地維護代碼了,比如 Spring 的全家桶。
怎么破
舊的重 SQL 邏輯暫時不要動,新的邏輯都基于 Java 模式開發,先保證慢 SQL 不增加,舊的 SQL 穩定運行,畢竟業務穩定是***要素。
如果業務初期需要非常非常快速開發,那么使用重 SQL 模式也是可以理解的,但是還是要抽時間重構成 Java 模式。
結論
我支持將邏輯寫在 Java 等應用系統中。其實原因在上面基本描述完了,***就是復雜 SQL 的表關聯其實跟個人的能力有非常大的關系,如果一個 SQL 寫得不好,那是極慢極慢的非常容易把整個數據庫拖慢的。第二就是維護這些 SQL 也是一件很難受的事情,因為你完全不知道這個 SQL 背后的數據流轉是怎樣的,你只能根據自己的猜測去查看 SQL 中的 bug,Java 應用好歹還能 debug 一下還有打點看看數據不是?如果邏輯寫在 Java 中那么其實你的 DAO 層只需要編寫一次,但是可以***使用,基本不會在這一層浪費很多的時間(用過 ibatis 的都知道改了 SQL 需要重啟應用吧?)。第三就是邏輯都寫在 SQL ,中對于分庫分表和應用拆分來說是一件非常難受的事情,真的難受。
昨天寫的被吐槽了,回爐重造了,重新看看。