一根網線引發的血案-趙班長談運維
原創一根網線引發的血案-趙班長談運維
--運維的故障哲學
51CTO學院IT課程1折起秒殺,12月12日0點萬人秒殺準時開啟,我是51CTO學院高級講師趙班長,跟大家分享一些個人經驗。
“沒有經歷過故障的運維生涯是不完美的”--路人甲
在我們日常運維工作中,會遭遇各種各樣,甚至亂七八糟的故障。而且有些故障剛開始會讓你莫名其妙,但結果卻讓人苦笑不得。這次分享,我想通過闡述個人運維生涯中的其中兩個故障作為引子,進而聊聊發生故障之前和之后,我們應該怎么辦。
一、我只是插了一個網線,全網中斷
環境描述
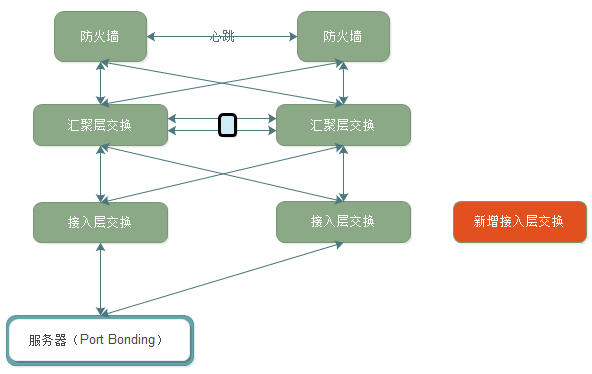
某年某月某日,機房上架新的服務器。我們的架構是服務器上聯兩臺接入層交換,做端口bonding。每兩個機柜都會有接入層交換機,所有接入層交換,雙鏈路上聯到匯聚層交換中。然后,匯聚層交換運行MSTP+HSRP協議。架構圖如下:我們的操作是要新增一個接入層交換,用來擴展網絡規模。
故障現象
當時網絡工程師(路人甲)正在準備登錄匯聚層交換配置端口Trunk,其他人員配合機房工作人員走線,當接入層交換的上聯網線拉到匯聚層交換機的機柜的時候,作為負責人的我(領導不能閑著啊)就問網絡工程師插哪里,回復:兩臺匯聚層交換的23端口。
插線誰不會啊,于是我就先把其中一根接入層交換機的線,插入了23端口。剛過去不到一分鐘,QQ群就有人反映打不開網站了,緊接著監控的系統各種報警就來了。
故障處理
1. 我當時的第一反映,趕緊詢問網絡工程師(路人甲)剛才執行了什么操作,回復剛登錄到交換機上還沒有操作。可以排除他的誤操作。
2. 然后詢問其他配合人員是否在線路上有插拔操作,同樣回復沒有。
3. 登錄監控系統,發現報警的是主機無法連接,也就是網絡不通,肯定是網絡方面的原因。
4. 開始思考在故障之前我們都干了什么?我馬上反映過來,我插了一根網線!雖然覺得不可思議,但是根據故障回滾的原則,我立即把網線拔掉,過了一會,故障恢復了。當時的想法就是這個黑鍋,我背定了,真心冤啊!
故障排查:
網絡工程師(路人甲),登錄匯聚層交換后,發現該交換機的23端口之前開啟了portfast特性。
故障原因剖析:
Portfast快速端口是一個Cisco Catalyst交換機的一個特性,在STP(Spanning Tree Protocol)中,端口有5個狀態:disable、blocking、listening、learning、forwarding,只有forwarding狀態,端口才能發送用戶數據。
一個端口接入設備后,就會經歷blocking->listening->learing->forwarding,每個狀態的變化要經歷一段時間。這樣從pc接上網線,到能發送用戶數據,需要進行等待的時間。但如果設置了portfast,那就不需要等待了。
好的,重點來了!portfast只能用在接入層,也就是說交換機的端口是接主機的才能啟用portfast,如果是接交換機的就一定不能啟用,否則會造成新的環路。(不過,Cisco也提供了BPDU guard特性解決這個問題,但是我們沒有啟用。)
那么為什么,這個匯聚層交換的23端口會開啟這個特性呢?原因是之前這個交換機確實有服務器接入,后來架構拓展了,才只用來接入二層的接入層交換機。
故障經常就是來的很突然,而且肯定會有各種奇葩的原因。甚至有的時候就是讓你還債,還是那句話“出來混,終究要還的。”我們繼續看下一個故障,直接沒有任何關聯性。
二、NFS故障,服務全部宕機
環境描述:
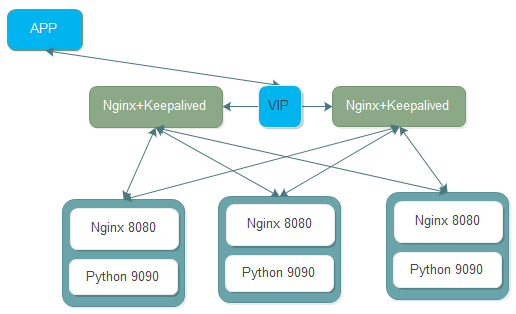
某APP后端API,Nginx+Python的架構,本地靜態文件由Nginx處理,其他請求轉發到后端Python編寫的API上,端口9090,接入層負載均衡Nginx+Keepalived。簡單的架構圖如下:
故障現象:
某年某月某日某時突然某后端API節點報警,API http code not 200。(Zabbix監控Nginx代理的某個接口),然后登陸查看所有API服務,發現進程都在。手動測試每個節點的監控URL,發現確實無法訪問。
故障處理:
1.查看API的錯誤日志,并未發現特別異常的報警,并沒有新版本發布。
2.手動測試API監聽的端口,訪問正常。直接訪問Nginx代理的8080端口,發現不正常,懷疑Nginx和API直接的通信存在問題。
3.這時有一個特殊情況就是api-nod1節點的訪問時是正常的。
4.查看其他節點的Nignx錯誤日志,發現有大量的請求用戶的一個URL失敗。例如/user/ID/xxx
5.通過對比發現api-node1和其他節點的唯一不同是api-node1節點運行了NFS,其他節點之前是掛載該節點的NFS。原因是:后端API會生成二維碼在各個服務器上,由于數據量不大,所以在api-node1節點啟動了NFS,其他所有節點生成的二維碼全部寫入到這個NFS共享上。查看發現該節點的NFS異常終止。手動啟動NFS和重啟所有API節點后,服務恢復正常。
故障原因剖析:
通過仔細查看報警才發現,之前api-node1這臺虛擬機因為內存跑滿自動重啟了,但是NFS并沒有開機啟動(這個是另外一個問題,暫不討論),因為當時報警太多就沒有仔細看每個報警。那么,為什么NFS故障會導致api不能訪問呢?應該是某個接口功能不能使用才對。
經過分析,這個功能是用戶用來生成二維碼的接口,如果用戶發現生成失敗會不停的重試,那么這些重試的api就會到nginx上,當然肯定都會失敗,因為NFS無法讀寫。但是,我們知道Nginx做后端健康檢查默認是無法指定URL的,突然這么多重試的API請求到達Nginx都失敗了,那么Nginx根據健康檢查策略就會認為后端服務器宕機。然后,就沒有然后了。不過,這個故障確實是多種因素疊加的一個效果。
好的,由于篇幅問題,就拿這兩個故障,來進行分析,看看我們能學到什么東西。
三、故障發生前,我們能做好什么
1.操作的規范性
第一個故障的背景,其實我們已經制定好了機房上架的操作流程,每個人都知道自己應該干什么,但是并沒有按之前的操作計劃執行。這是發生這個故障的根本原因,因為如果按流程,網絡工程師肯定會發現這個端口的設置并修改。
還有就是非實際操作人員不能盲目介入,這也是操作規范性的一個例子,雖然我只是想幫個忙而已,但是幫了倒忙。
2.建立完善的監控體系
監控體系的重要性不言而喻,不準備多說。但正如第二個故障案例,我們有監控,但是遇到的問題是當報警很多的時候,并沒有仔細的查看所有監控,而是把api無法連接當作重點,而忽略了其他報警。所以說,仔細的看報警,以及給故障進行準確的分級非常重要。
3.故障處理流程
在發生故障前要盡可能的建立完善的故障處理流程,先干什么,后干什么,故障的分級、故障的職能性升級都要有確切的流程和文檔。保證故障的處理人能夠合理的將故障解決,不能解決的及時進行故障升級。
四、發生故障后,我們能做好什么
1.恢復是故障管理的第一要務
ITIL的服務運營有一個故障管理的流程,故障管理的目標是盡可能快地恢復到正常的服務運營,將故障對業務運營的負面影響減小到最低。那么,故障管理的大忌,就是試圖快速定位故障原因而忽略了故障處理流程。下面有個小段子,可以幫助你理解:
某電商系統,一次用戶系統升級,導致串號,也就是用戶A登錄后,看到的是用戶B的帳號信息。領導問怎么辦:
開發人員:老板,給我10分鐘,馬上修復這個bug。然后開發人員實際使用了8分鐘修代碼并上線。結果:故障依舊。
開發主管:你這水平不行啊,我來,我只需要5分鐘。然后開發主管用了4分鐘修代碼并上線。結果:故障依舊。
開發經理:你們都閃開,我只需要1分鐘。然后開發經理真的1分鐘修改代碼并上線。結果:故障依舊。
老板:誰能快速的回復這個故障,我們已經故障整整13分鐘了!這個時候運維甲奮力的擠進人群:我們有秒級回滾腳本,所有節點回滾上一個版本并啟動不到1分鐘。結果:1分鐘后,故障恢復了。
篇幅問題,這個故障就到這里。我想無論你是老板、經理、開發、測試、運維都應該已經明白了,不做過多的解釋了。
2.故障復盤
每一次發生故障后,運維負責人都需要牽頭進行故障的復盤。開發、測試、運維要一起審查這次故障,搞明白是哪里出了問題,我們應該怎么避免這類故障的再次發生。俗話說:故障是我們最好的老師。不過,這個老師大家都不會喜歡。當然還需要我們詳細做好故障的記錄。
3.問題管理
故障復盤的目的和問題管理是相同的。ITIL的服務運營中,問題管理流程的目標是預防問題的產生及由此引發的故障,消除重復出現的故障,并對不能預防的故障盡量降低他對業務的影響。
所以我們可以在故障復盤的時候,要把這個故障轉化為問題管理,全面分析故障的原因,務必徹底解決,而且每項工作一定要落實到具體的負責人。
推薦課程:
云計算與自動化運維實踐視頻課程套餐
http://edu.51cto.com/pack/view/id-298.html
趙舜東
江湖人稱趙班長,51CTO學院高級講師,在學院開設10門精品課程。曾負責武警某部指揮自動化架構和運維工作,2008年退役后一直從事互聯網運維工作。UnixHot運維社區創始人、《SaltStack入門與實踐》作者。