













細說Oracle數據庫與操作系統存儲管理二三事
在上大學的時候,學習操作系統感覺特別枯燥,都是些條條框框的知識點,感覺和實際應用的關聯不大。發現越是工作以后,在工作中越想深入了解,發現操作系統知識越發重要。在實踐中結合理論還是不錯的一種學習方法。自從接觸數據庫以后,越來越感覺到很多東西其實都是相通的,操作系統中的很多設計思想在數據庫中也有借鑒和改進之處。
說到存儲管理,是操作系統中最重要的資源之一。因為任何程序和數據等都需要占有一定的存儲空間,存儲管理會直接影響到系統的性能。
存儲器是由主存和外存組成。對于外存,可能覆蓋面更廣,像硬盤,移動硬盤,光盤,磁帶,SSD等等都是外存的覆蓋范圍。主存大家很熟悉,這些年主存的大小也有了極高的提升,現在的服務器配置中幾百GB的內存都是很正常的。
關于存儲的管理技術,先討論以下兩個部分。
固定分區
先來點操作系統的知識。
關于固定分區管理技術,就是把主存分為若干個固定大小的存儲區,每個分區提供給某一個作用使用,如果作業完成會把相應的存儲區歸還。
在多道作業系統中,主存中分區的個數是固定不變的,而且每個分區的大小也是固定不變的。如果分區總是大于作業,那么就有很多分區沒有充分使用,產生碎片。
來結合數據庫來看一看(shared pool中的free list)
在數據庫中,shared pool中的free list(bucket)管理和固定分區管理很相似。
shared pool中存儲單位是chunk,多個chunk組成一個鏈表,也叫做bucket,每個bucket都對chunk的大小都有一定的范圍,是一個連續的值,沒有交叉。
在10g,11g中都設置了255個bucket,可以通過trace文件來了解一下。
- [ora11g@rac1 trace]$ grep Bucket *18155*.trc
- Bucket 0 size=32
- Bucket 1 size=40
- Bucket 2 size=48
- Bucket 3 size=56
- Bucket 4 size=64
- Bucket 5 size=72
- ...
- Bucket 250 size=12352
- Bucket 251 size=12360
- Bucket 252 size=16408
- Bucket 253 size=32792
- Bucket 254 size=65560
可能對于bucket的大小沒有一個直觀的感受,可以生成一個圖來看看就很清楚了。
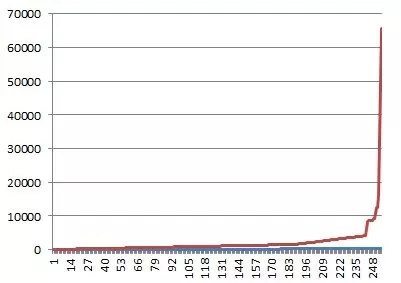
隨著bucket的增長,對應的chunk大小都在遞增,絕大多數的bucket中,chunk的大小都在5k以內。只有很小的一部分bucket的支持的chunk size很大,這個也是Oracle在不斷的改進中得到的一個最優值,按照比例來劃分,保證每次訪問需要的chunk大小都能夠合理的分配,盡量減少冗余。
同時不是每個bucket里面都是有chunk的,這個chunk的分配還是根據進入shared pool以后申請chunk大小緊密相關,bucket中的chunk數目可不是平均的。
Oracle在早期的版本中也碰到了不少的問題,在10g,11g中都對bucket的數目做了提升(目前都是255個),而且分區的大小也做了調整。這是一個比較均衡的比例,能夠保證每次請求的大小都在bucket的范圍之內,盡量提高效率。
回到操作系統中,我們再補充幾點。
在存儲的管理中,存儲的分配和釋放都需要根據分區來說明。在固定分區中采用了一個存儲分塊表(MBT)來維護而存儲的區的信息,存儲區的信息在操作系統中有一個專有名詞叫做數據基,數據基聽起來挺抽象,其實理解起來還是蠻簡單的。
我們用下面的圖標來說明。我們假設下面的這個表格就是存儲分塊表,其中數據基就包括,存儲的分區大小,存儲位置還有狀態。
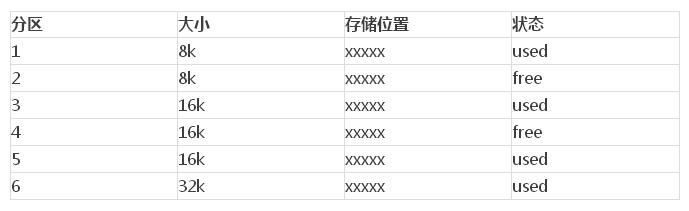
猛一看,上面的方式還是比較簡單而且可行的。但是還是固定分區的硬傷,主存利用率不高,對于進入主存中的作業大小我們也沒法預知,而且對于MBT表的管理感覺還是不夠清晰。如果需要查找哪些分區可用,需要重新分配的時候,就得遍歷整個表,遍歷了已經使用的分區,這樣分配的過程就比較長了。
這個時候可以參考一下:
- 可變分區的多道管理技術
這種技術在一定程度上解決了固定分區帶來的問題,可變分區在主存中不會事先創建一個個分區,而是在作業進入主存的時候按照作業大小再來創建分區。
這樣的話,分區個數不固定,分區大小不固定,在Oracle中也有一些相似之處。
- Oracle中的deferred_segment_creation
比如說對于分區的不固定,在11g中有一個參數deferred_segment_creation,如果我們設定為true,那么在創建之初是不會分配對應的分區的,直到開始插入數據之后,它才會根據插入的數據來創建分區。
- Oracle中的interval partitoning
如果根據需要動態的創建分區,而且分區的大小也不固定。
比如在數據庫的表空間管理中,我們可以指定分區的。
對于可變分區的數據基管理,是采用了兩個存儲分區表來管理的,已使用分區表(UBT)和空閑分區表(FBT),這樣就可以減少存儲分配和釋放的性能。
在這點上,Oracle表空間中的數據字典管理方式是一致的。
Oracle中早期是采用FET$,UET$ 兩個數據字典表來維護分區的信息的。只是在數據基上會有一定的差別。
FET$和UET$的結構如下:
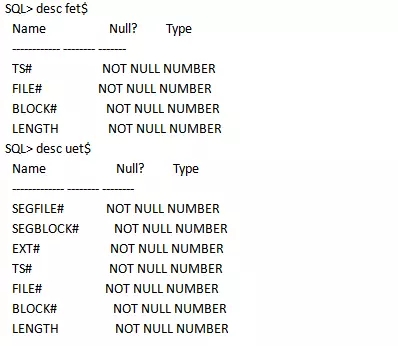
這種方式在早期的Oracle版本中采用,這種表空間管理方式叫數據字典管理。
但是在Oracle的不斷改進中,發現這種方式還是存在一定的問題,資源消耗還是比較高的。對于這兩種數據字典表的DML操作,會產生較多的遞歸SQL來間接完成對兩個數據字典表的更新,在更新的過程中也會存在事務,存在事務也就會產生一定的undo和redo。最后就是對于相鄰空閑空間的合并, 在Oracle中是通過SMON進程來實現的。
回到操作系統,操作系統中對于數據基的管理還有一種方式,就是空閑存儲鏈表。
這種方式就是把空閑分區通過鏈表的形式串起來,形成了一條空閑存儲塊鏈。
這種技術在數據庫中可有一個很響亮的名字,在buffer cache中叫做LRU鏈表。
在buffer cache中的實現方式也是類似的。當然在Oracle中會采用其它的算法和策略。Oracle中是把buffer按照被使用的先后順序掛在LRU鏈表 上,先被使用的buffer放在了鏈表的后面,后被使用的buffer掛載LRU鏈表的前面,如果buffer被修改的時候,buffer就會從LRU鏈 表上取出。這樣始終保持LRU鏈表中都是可用的數據塊。
可變分區的存儲算法
然后來簡單說一下可變分區的存儲算法。
目前主要有以下幾種:
- 最佳適用算法
這種方式就是從所有未分配的分區中挑選一個最接近于作業尺寸且大于或者等于作業大小的分區分配。
- 最先適應法
按照分區序號從存儲分塊表中的第一個表目找找,把最先找到且大約等于作業大小的分區分配。
- 最壞適應法
把所有未分配的分區中挑選最大的且大于等于作業大小的分區分配。
- 位圖法
把所有的分區使用一個位來表示狀態,1表示塊已經被使用,0表示分區空閑。
在Oracle中的存儲算法可能更接近于最佳適應算法,唯一的不同的是在Oracle中采用了hash來該分配到哪個bucket。但是都會保證分配的空間是大于等于請求的大小。
而位圖法在表空間管理中也有相似的使用方式。
表空間的管理有兩種方式,數據字典管理和本地管理。
本地管理中會在數據文件的頭部采用多個位來存放。這個bitmap類似下面的形式。
11110111001110100.....
1代表分區已被使用,0代表分區還是空閑,當進程需要分區的時候,只要掃描數據文件的頭部的bitmap,就可以找到值為0的分區。分配了分區之后把它修 改為1,釋放空間就會從1修改為0. 修改數據文件頭部的操作速度快且不存在事務,就沒有redo,undo,更不會有遞歸SQL。對于相鄰分區的合并來說,兩個連續的0就能說明是連續的空閑 分區,所以也不需要再合并相鄰的可用分區了。
前面討論了固定分區和可變分區管理的一些情況,它們的主要缺點就是主存使用的低效率和存儲分配釋放的低速。固定分區是分區內部的碎片造成主存利用率低,而可變分區是分區外部的碎片,往往小到無法使用,從而主存利用率不高。對于這個問題,分頁是一種很有效的方法。
分頁技術
分頁技術主要是把主存分為許多同樣大小的存儲塊,并以這種存儲塊作為存儲分配單位。Oracle數據庫中物理存儲單位有段,區,數據塊,這個時候所說的數據塊和操作系統數據塊存在著映射,一般都比操作系統塊要大。數據庫中默認為8K,數據的存儲都是以8K的基本單位來存儲的。如果把這一點繼續延伸,Oracle中的區(extent)就和分頁技術中所說的頁很類似。
分頁存儲中的基本實現過程,有以下幾點:
- 把主存分為相同大小的存儲塊,叫做頁架,頁架從0開始,編號依次是0,1,2....
- 用戶邏輯地址的分頁,用戶邏輯地址可以劃分為和頁架大小相同的部分,叫做頁。頁號從0開始,依次為0,1,2...
- 邏輯地址的表示,既然說到了邏輯地址,表示方法也很重要。每一個邏輯地址都是相對地址,用一個數對(p,d)來表示,p代表頁號,d代表邏輯地址在也好為p的頁中相對的地址,也叫偏移量。
聽起來挺枯燥啊,可以簡單舉個例子,我們常看的書就是一個很好的例子,書有很多大小,四開,八開,十六開,可以理解為頁架,書中的每一頁就是我們所說的頁,邏輯地址可以這么理解,一本書有很多章節,小結,比如第二章第3頁,我們就能夠很快找到,這個時候,頁號就是2,偏移量就是3,用(p,d)來表示就 是(2,3)
舉一個嚴謹的例子,比如給定一個虛地址3456,假設頁面大小為1000B,則第0頁對應的地址為0-999,第1頁為1000-1999,則虛地址3456=(3,456)
這一點和Oracle中創建表空間時指定的extent management管理方式很相似,比如我們創建一個表空間test指定分區大小為1M,表空間大小為100M,則語句如下:
create tablespace test add datafile '/u01/app/db/test01/data01/test01.dbf' size 100M extent management local uniform size 1M ;
這樣我們指定分區大小為1M,如果存儲了100M的數據,這樣100M就會分為100個分區。如果數據大于分區1M,則可以存儲在相應的分區上,不一定連續。
可以用下面的表格來說明。
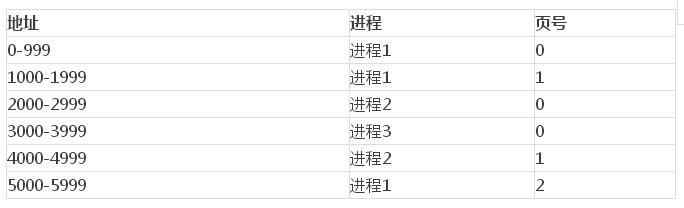
對應到每個進程對應的地址,就是我們所說的邏輯地址,比如進程1對應的邏輯地址就是
- 0-999
- 1000-1999
- 2000-3999
所以在分頁思想中的難點就是對于地址的表示,我們已經說使用(p,d)來表示,但是這個數在機器指令的地址場中表示還有不同,首先會把地址分為兩部分,一部分表示頁號,一部分表示頁內地址。
這種方式每次訪問一個主存單元都用一次除法得到頁號和頁內地址就很繁瑣,實際上效率要更差。這個時候相比前人也是考慮了很多招數,最后還是使用二進制來搞定,指定頁面尺寸是2的冪,這樣就會省去很多額外的轉換。
最后一個例子很關鍵,如果看懂了說明你對分頁思想算是明白了。
假設頁的大小為1KB,計算邏輯地地址為4101的頁號,頁內地址。
按照二進制的思想,4101可以這樣表示 4101=2^12+2^1+2^1+2^0
用0,1來表示就是
0001000000000101
頁的大小是1KB=2^10,則在二進制串中,后10位就是對應的頁內地址,二進制0101代表的是5,表示頁內地址為5
0001000000000101
頁號對應的二進制串000100表示頁號為4
所以4101對應的邏輯地址表示為(4,5)
這種方法可以省去除法運算,硬件層面會自動把邏輯地址拆分為兩部分,對應頁號和頁內地址。
問題來了,地址能夠表示了,那使用的時候是怎么轉換的呢,首先會把邏輯地址抽取出來,像上面的例子,頁號是4,然后根據頁號為索引找到該頁存放的主存頁架號。比如存放的地址為2000-2999,則頁架號為2,然后把頁架號取代邏輯地址,和右邊的頁內地址組成了最終的物理地址去訪問內存。
這種思想還是需要些時間去消化一下,優點也是很明顯的,基本上沒有頁內碎片,同時也不會存在小到無法再用的頁外碎片。因為每個碎片都是頁架的整數倍。
分頁中使用的二進制方式處理地址是一種很值得借鑒的方式,可以減少很多額外的開銷,和Oracle中的rowid存儲方式也很類似。
分段式存儲
分段式存儲管理系統中,會為每個段分配一個連續的分區,而進程中的各個段可以離散地移入內存中不同的分區中,說起分段就會聯想到分頁,我們來聊聊分頁與分段的主要區別。
分頁和分段有許多相似之處,比如兩者都不要求作業連續存放。但在概念上兩者完全不同,主要表現在以下幾個方面:
- 頁是信息的物理單位,分頁是為了實現非連續分配,以便解決內存碎片問題,或者說分頁是由于系統管理的需要。段是信息的邏輯單位,它含有一組意義相對完整的信息,分段的目的是為了更好地實現共享,滿足用戶的需要。
- 頁的大小固定,由系統確定,將邏輯地址劃分為頁號和頁內地址是由機器硬件實現的。而段的長度卻不固定,決定于用戶所編寫的程序,通常由編譯程序在對源程序進行編譯時根據信息的性質來劃分。
- 分頁的作業地址空間是一維的,分段的地址空間是二維的。
從數據庫的角度來看,感覺和數據庫中的段概念還是比較類似的。數據庫中段包含多個分區。各個分區也可以在不相鄰的分區中。
找一個圖來說明。
在分段情況下,會要求每個進程的地址空間劃分為若干個段,每個段都有自己的段名,對應到下圖中就是一個段號。每個段的地地址空間都是從0開始,是一個連續的地址空間。
從地址的存儲情況來說,段和頁的存儲方式都是類似的,都會包含兩部分。分段存儲中是段號和段內地址,和分頁存儲中的頁號和頁內地址類似。
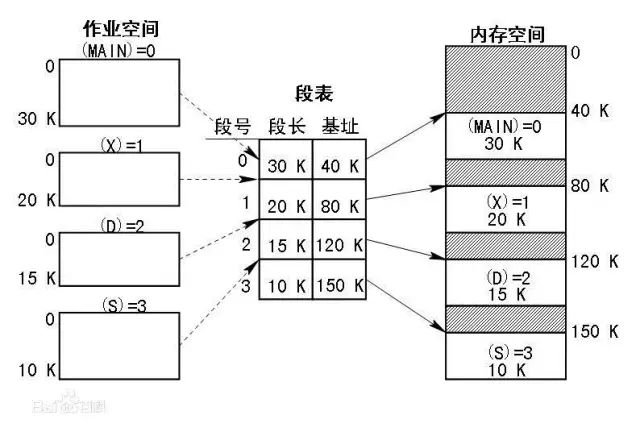
由于一個進程由很多段組成,而且各個段可能被分配在主存中的多個不相鄰的分區中,為了將進程的邏輯地址轉換為物理地址,需要有一個短標來指出進程的某段放在主存中的位置以及段長。
這一點從數據庫層面來說有類似的方面,首先是進程由多個段組成,數據庫中可以理解為一個表包含多個段,數據段,索引段,LOB段,LOB索引段等等。這些都是獨立的段,在存儲的時候也可能分布在不同的表空間中,所以可能不是一個相鄰的分區。
而段的信息在操作系統層面是通過段表來維護的,數據庫層面則是通過數據字典,user_segments,user_extents來維護的,每個表包含的段,每個段包含的區都是很詳實的。
從分段和分頁的優點來說,因為它們涉及的層面和應用方向不同,但是還是有一定的可比性,在段共享方面,分段存儲還是很有優勢,誰讓它是段共享呢。
從操作系統層面舉個例子就是一個多用戶系統,有一個應用程序可能包含的程序段是100K,數據段是40K,按理說需要40K*40+100k*40=1600+4000=5600k
在分段存儲中則需要100k+40k*40=1700k,從這一點上來說還是很大的改進。
從這一點上來說,數據庫中的同義詞就有點分段存儲的味道,每個同義詞都可以訪問源表,相當于共享了數據,同義詞占用的存儲空間很小,幾乎可以忽略。
可能分段存儲和分頁存儲都各有千秋,但是都是在不斷的使用和改進中主鍵發展起來的,分段存儲沒有段內碎片,只有外部碎片,簡單分段技術也是基于多重分區技 術的發展而來。另外簡單分頁對于用戶是不可見的,用戶無法了解進程被分頁或者分頁的細節,但是簡單分段對于用戶基本是可見的,當進程被交換出內存的時候, 對應的頁表和段表也需要隨著進程一起撤出內存。
當然分頁分段方式還在不斷的發展中,要不怎么有后續的段頁式存儲呢,很多時候類比操作系統方面的知識,就會讓我們對于很多事物有了全新的認識和了解。
當然順帶幫大家復習了操作系統的基礎知識,我的目的也算達到了。












