













高級長短期記憶網絡:關于更優時間依賴性刻畫在情感識別方面的應用
原創【51CTO.com原創稿件】長短期記憶網絡(LSTM)隱含了這樣一個假設,本層的現時狀態依賴于前一時刻的狀態。這種“一步”的時間依賴性,可能會限制LSTM對于序列信號動態特性的建模。在這篇論文里,針對這樣的一個問題,我們提出了高級長短期記憶網絡(advanced LSTM (A-LSTM)),利用線性組合,將若干時間點的本層狀態都結合起來,以打破傳統LSTM的這種局限性。在這篇文章中,我們將A-LSTM應用于情感識別中。實驗結果顯示,與應用傳統LSTM 的系統相比,應用了A-LSTM的系統能相對提高5.5%的識別率。
研究背景
LSTM 現在被廣泛的應用在RNN中。它促進了RNN在對序列信號建模的應用當中。LSTM 有兩個輸入,一個來源于前一層,還有一個來源于本層的前一個時刻。因此,LSTM隱含了這樣一個假設,本層的現時狀態依賴于前一時刻的狀態。這種“一步”的時間依賴性,可能會限制LSTM對于序列信號動態特性的建模(尤其對一些時間依賴性在時間軸上跨度比較大的任務)。在這篇論文里,針對這樣的一個問題,我們提出了advanced LSTM (A-LSTM),以期打破傳統LSTM的這種局限性。A-LSTM利用線性組合,將若干時間點的本層狀態都結合起來,因此不僅可以看到”一步“以前的狀態,還可以看到更遠以前的歷史狀態。
在這篇文章中,我們把A-LSTM應用到整句話層級(utterance level)上的情感識別任務中。傳統的情感識別依賴于在整句話上提取底端特征(low level descriptors)的統計數據,比如平均值,方差等等。由于實際應用中,整句話中可能會有一些長靜音,或者是一些非語音的聲音,這種統計數據就可能不準確。在這篇論文中,我們使用基于注意力模型(attention model)的加權池化(weighted pooling)遞歸神經網絡(recurrent neural network)來更有效的提取整句話層級上的特征。
高級長短期記憶網絡
A-LSTM利用線性組合,將若干時間點的本層狀態都結合起來。這其中的線性組合是利用與注意力模型(attention model)類似的機制進行計算的。具體公式如下。
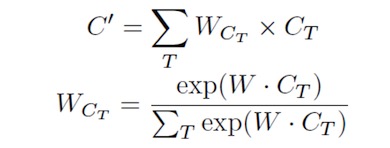
Fig 1 中C'(t)即為前面若干時間狀態的線性組合。這個線性組合以后的時間狀態將被輸入下一時間點進行更新。可以想象,每次的更新都不只是針對前一時刻,而是對若干時刻的組合進行更新。由于這種組合的權重是有注意力模型控制,A-LSTM可以通過學習來自動調節各時間點之間的權重占比。如果依賴性在時間跨度上比較大,則更遠以前的歷史狀態可能會占相對大的比重;反之,比較近的歷史狀態會占相對大的比重。
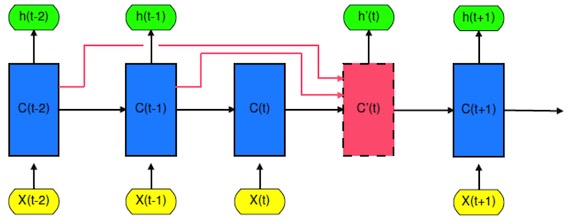
Fig 1 The unrolled A-LSTM
加權池化遞歸神經網絡
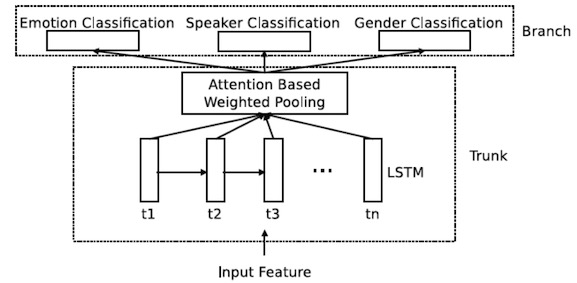
Fig 2 The attention based weighted pooling RNN.
在這篇論文中,我們使用基于注意力模型的加權池化遞歸神經網絡來進行情感識別(見Fig 2)。這一神經網絡的輸入是序列聲學信號。利用注意力模型,我們的神經網絡可以自動調整各個時間點上的權重,然后將各個時間點上的輸出進行加權平均(加權池化)。加權平均的結果是一個能夠表征這一整串序列的表達。由于注意力模型的存在,這一表達的提取可以包含有效信息,規避無用信息(比如輸入序列中中的一些長時間的靜音部分)。這就比簡單的計算一整個序列的統計數值要更好(比如有opensmile提取的一些底端特征)。 為了更好的訓練模型,我們在情感識別任務之外還添加了兩個輔助任務,說話人識別和性別識別。 我們在這個模型當中使用了A-LSTM來提升系統性能。
實驗
在實驗階段,我們使用IEMOCAP數據集中的四類數據(高興,憤怒,悲傷和普通)。這其中一共有4490句語音文件。我們隨機選取1位男性和1位女性說話人的數據作為測試數據。其余的數據用來訓練(其中的10%的數據用來做驗證數據)。我們采用三個衡量指標,分別為無權重平均F-score(MAF),無權重平均精密度(MAP),以及準確率(accuracy)。
我們提取了MECC,信號過零率(zero crossing rate),能量,能量熵,頻譜矩心(spectral centroid),頻譜流量(spectral flux),頻譜滾邊(spectral rolloff),12維彩度向量(chroma vector),色度偏差(chroma deviation),諧波比(harmonic ratior) 以及語音基頻,一共36維特征。對這些序列特征進行整句話層級上的歸一化后,將其送入系統進行訓練或測試。
在這個實驗中,我們的系統有兩層神經元層,***層位全連接層(fully connected layer),共有256個精餾線性神經元組成(rectified linear unit)。第二層位雙向長短期記憶網絡(bidirectional LSTM (BLST))。兩個方向一共有256個神經元。之后即為基于注意力模型的加權池化層。最上方為三個柔性***值傳輸函數層,分別對應三個任務。我們給三個任務分配了不同的權重,其中情感識別權重為1,說話人識別權重為0.3,性別識別為0.6。如果是應用A-LSTM,我們就將第二層的BLSTM替換成雙向的A-LSTM,其他的所有參數都不變。這里的A-LSTM選取三個時間點的狀態作線性組合,分別為5個時間點前(t-5),3個時間點前(t-3),以及1個時間點前(t-1)。實驗結果如下:
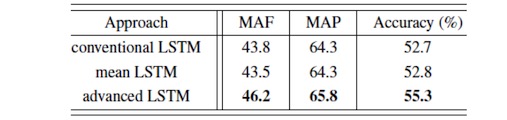
其中的mean LSTM 與A-LSTM比較類似,唯一區別是,當我們為選取的幾個時間點的狀態作線性組合的時候,不是采用注意力模型,而是簡單的做算術平均。
結論
與應用傳統LSTM 的系統相比,應用了A-LSTM的系統顯示出了更好的識別率。由于加權池化過程是將所有時間點上的輸出進行加權平均,因此系統性能的提升只可能是來源于A-LSTM更加靈活的時間依賴性模型,而非其他因素,例如高層看到更多時間點等等。并且,這一提升的代價只會增加了數百個參數。
作者:陶菲/Fei Tao, 劉剛/Gang Liu
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】













