Accordion :一種HBase內存壓縮算法
現如今,人們對基于HBase的產品的讀寫速度要求越來越高。在理想情況下,人們希望HBase 可以在保證其可靠的持久存儲的前提下能并擁有內存數據讀寫的速度。為此,在HBase2.0中引入Accordion算法。
Hbase RegionServer 負責將數據劃分到多個Region中。RegionServer 內部(垂直)的可伸縮性能對于最終用戶體驗以及整個系統的利用率至關重要。Accordion 算法通過提高對RAM利用來提升RegionServer擴展性。這樣就使得內存中可以存放更多數據,從而降低了對磁盤的讀取頻率(即降低了HBase中磁盤占用和寫入方法,更多的讀寫RAM,降低了對于磁盤的IO訪問)。在HBase2.0之前,這些指標是不能同時滿足的,并且相互限制,在引入Accordion之后,這一狀況得到了改善。
Accordion算法來源于HBase核心架構LSM算法。在HBase Region 中,數據是按照key-value形式映射為可查找的存放,其中put進來的新數據以及一些topmost(靠前)數據存放在內存中(MemStore),其余的為不變的HDFS文件,即HFile。當MemStore寫滿時,數據被flush到硬盤里,生成新的HFile文件。HBase采用多版本并發控制,MemStore將所有修改后的數據存儲為獨立版本。一條數據的多個版本可能同時存儲在MemStore和HFile中。當讀取一條多版本數據時,根據key從HBase掃描BlockCache中的HFile獲取最新的版本數據。為了降低對磁盤的訪問頻率,HFiles在后臺合并(即壓縮過程,刪除多余的cells,創建更大的文件)。
LSM通過將隨機讀寫轉換為順序讀寫,從而提高了寫入性能。之前的設計并未采用壓縮內存數據,主要原因是在LSM樹設計當初,RAM還是非常緊缺的資源,因此MemStore的容量很小。隨著硬件不斷提升,RegionServer管理的整個MemStore可能為數千兆字節,這就為HBase優化留下了大量空間。
Accordion算法重新將LSM應用于MemStore,以便當數據仍在RAM中時可以消除冗余和其他開銷。這樣做可以減少flush到HDFS的頻率,從而降低了寫入放大和磁盤占用。 隨著flush次數的減少,MemStore寫入磁盤的頻率會降低,進而提高HBase寫入性能。磁盤上的數據較少也意味著對塊緩存的壓力較小,提高了讀取的響應時間。最終,減少對磁盤寫入也意味著在后臺壓縮次數降低,即讀取和寫入周期將縮短。總而言之,內存壓縮算法的效果可以被看作是一個催化劑,它使整個系統的運行速度更快。
目前Accordion提供了兩個級別的內存壓縮:basic 級別和 eager 級別。前者適用于所有數據更新的優化,后者對于高數據流的應用非常有用,如生產-消費隊列,購物車,共享計數器等。所有這些使用案例都會對rowkey進行頻繁更新,生成多個冗余版本的數據,這些情況下Accordion算法將發揮其價值。但另一方面,eager 級壓縮優化可能會增加計算開銷(更多內存副本和垃圾收集),這可能會影響數據寫入的響應時間。如果MemStore使用堆內MemStore-本地分配緩沖區(MSLAB),這會導致開銷增大。所以建議不要將此配置與eager級壓縮結合使用。
如何使用
內存壓縮可以在全局和列族級別配置。目前支持三種級別配置:none(傳統實現),basic和eager。默認情況下,所有表都是basic內存壓縮。此配置可以在hbase-site.xml中修改,如下所示:
- <property>
- <name> hbase.hregion.compacting.memstore.type </name>
- <value> <none|basic|eager> </value>
- </property>
也可在HBase shell中為每個列族進行單獨配置,如下所示:
- create '<tablename>',
- {NAME =>'<cfname>',
- IN_MEMORY_COMPACTION =>' <NONE|BASIC|EAGER>' }
性能提高
通過利用YCSB(Yahoo Cloud Service Benchmark)對HBase進行了全面測試。試驗中采用數據集大小為100-200 GB,結果表明Accordion算法對于HBase性能有顯著的提升。
Heavy-tailed (Zipf)分布:在測試負載中國,rowkey遵循大多數現實生活場景中出現的Zipf分布。在這種情況下,當100%的操作是寫入操作時,Accordion實現寫入放大率降低30%,寫入吞吐量提高20%,GC降低22%。當50%的操作是讀取時,tail讀取延遲降低12%。
均勻分布:第二個測試中rowkey都均衡分布。當100%的操作是寫入操作時,Accordion的寫入放大率降低25%,寫入吞吐量提高50%,GC降低36%。tail讀取延遲不受影響(由于沒有本地化)。
Accordion如何工作
High Level設計:
Accordion引入了MemStore的內部壓縮(CompactingMemStore)實現方法。與默認的MemStore相比,Accordion將所有數據保存在一個整的數據結構中用segment來管理。最新的segment,稱為active segment,是可變的,可用來接收Put操作,若active segment達到overflow條件(默認情況下32MB,MemStore的25%大小),它們將會被移到in-memory pipeline 中,并設為不可變segment,我們稱這一過程為in-memory flush。Get操作通過掃描這些 segment和HFiles 取數據(后者操作通過塊緩存進行訪問,與平常訪問HBase一樣)。
CompactingMemStore 可能會不時在后臺合并多個不可變segment,從而形成更大的segment。因此,pipeline是“會呼吸的”(擴張和收縮),類似于手風琴波紋管,所以我們也將Accordion 譯為手風琴。
當RegionServer 刷入一個或多個MemStore到磁盤釋放內存時,它會刷入 CompactingMemStore中已經移入pipeline中的segment到磁盤。基本原理是延長MemStore有效管理內存的生命周期,以減少整體I/O。當flush發生時,pipeline中所有的segment 段將被移出合成一個快照, 通過合并和流式傳輸形成新的HFile。圖1展示了CompactingMemStore與傳統設計的結構。
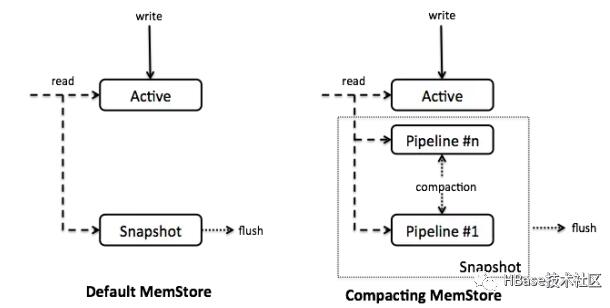
圖1. CompactingMemStore與DefaultMemStore
Segment結構:
與默認的MemStore類似,CompactingMemStore在單元存儲之上維護一個索引,這樣可以通過key快速搜索。兩者不同的是,MemStore索引實現是通過Java skiplist (ConcurrentSkipListMap--一種動態但奢侈的數據結構)管理大量小對象。CompactingMemStore 則在不可變的segment 索引之上實現了高效且節省空間的扁平化布局。這種優化可以幫助所有壓縮策略減少RAM開銷,甚至可以使數據幾乎不存在冗余。當將一個Segment加入pipeline中,CompactingMemStore 就將其索引序列化為一個名為CellArrayMap 的有序數組,該數組可以快速進行二進制搜索。
CellArrayMap既支持從Java堆內直接分配單元,也支持MSLAB的自定義分配(堆內或堆外),實現差異通過被索引引用的KeyValue對象抽象出來(圖2)。CellArrayMap本身始終分配在堆內。
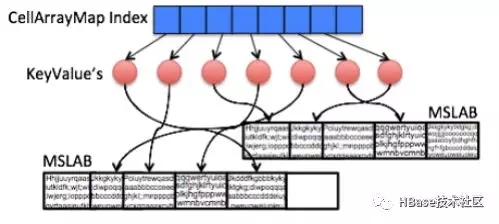
圖2.具有扁平CellArrayMap索引和MSLAB單元存儲的不可變Segment
壓縮算法:
內存中壓縮算法在pipeline中的Segment上維護了一個單一的扁平化索引。這樣的設計節省了存儲空間,尤其是當數據項很小時,可以及時將數據刷入磁盤。單個索引可使搜索操作在單一空間進行,因此縮短了tail讀取延遲。
當一個active segment被刷新到內存時,它將排列到壓縮pipeline中,并會立即觸發一個異步合并調度任務。該調度任務將同時掃描pipeline中的所有Segment(類似于磁盤上的壓縮)并將它們的索引合并為一個。basic和eager 壓縮策略之間的差異體現在它們處理單元數據的方式上。basic壓縮不會消除冗余數據版本以避免物理復制,它只是重新排列KeyValue對象的引用。eager壓縮則相反,它會過濾出冗余數據,但這是以額外的計算和數據遷移為代價的。例如,在MSLAB存儲器中,surviving 單元被復制到新創建的MSLAB中。
未來的壓縮可能會在basic壓縮策略和eager壓縮策略之間實現自動選擇。例如,該算法可能會在一段時間內嘗試eager壓縮,并根據所傳遞的值(如:數據被刪除的比例)安排下一次壓縮。這種方法可以減輕系統管理員的先驗決定,并適應不斷變化的訪問模式。