MySQL實戰篇:建立高性能的MySQL技巧
前言
MySQL是一種關系數據庫管理系統,關系數據庫將數據保存在不同的表中,而不是將所有數據放在一個大倉庫內,這樣就增加了速度并提高了靈活性。由于其體積小、速度快、總體擁有成本低,尤其是開放源碼這一特點,一般中小型網站的開發都選擇 MySQL 作為網站數據庫。
由于其社區版的性能卓越,搭配 PHP 和 Apache 可組成良好的開發環境。
常用技巧
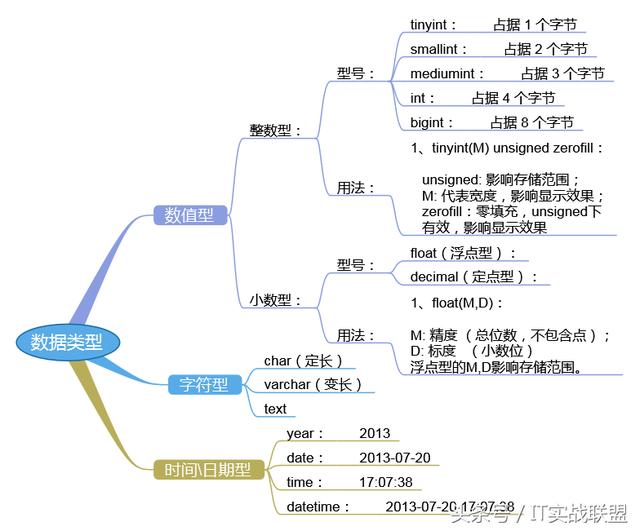
優化的數據類型
優先確認數據類型
在為列選擇數據類型時,***步需要確定合適的大類型:數字,字符串,時間等。下一步是選擇具體類型。很多MySQL的數據類型可以存儲相同類型的數據,只是存儲的長度和范圍不一樣,允許的精度不一樣,或者需要的物理空間(磁盤和內存空間)不同。相同大類型的不同子類型數據有時也有一些特殊的行為和屬性。
更小的通常更好
一般情況下,應該盡量使用可以正確存儲數據的最小數據類型。更小的數據類型通常更快,因為它們占用更少的磁盤,內存和CPU緩存,并且處理時需要的CPU周期也更少。但是要確保沒有低估需要存儲的值得范圍。
簡單就好
簡單數據類型的操作通常需要更少的CPU周期。例如,整型比字符操作代價更低,因為字符集和校對規則(排序規則)使字符比整型比較更復雜。
盡量避免使用NULL
很多表都包含可為NULL(空值)的列,即使應用程序并不需要保存NULL也是如此,這是因為可為NULL是列的默認屬性。通常情況下***指定列為NOT NULL,除非真的需要存儲NULL值。如果查詢中包含可為NULL的列,對MySQL來說更難優化,因為可為NULL的列使得索引,索引統計和值比較都更復雜。可為NULL的列會使用更多的存儲空間,在MySQL里也需要特殊處理,當可為NULL的列被索引時,每個索引記錄需要一個額外的字節。如果計劃在列上建索引,就應該避免設計成可為NULL的列。
備注:例如:DATETIME和TIMESTAMP列都可以存儲相同類型的數據:時間和日期,精確到秒。然而TIMESTAMP只使用DATETIME一半的存儲空間,并且會根據時區變化,具有特殊的自動更新能力。另一方面,TIMESTAMP允許的時間范圍要小很多,有時候它的特殊能力會成為障礙。
遵循數據庫設計的三大范式
***范式
確保每列的原子性(強調的是列的原子性,即列不能夠再分成其他幾列). 如果每列(或者每個屬性)都是不可再分的最小數據單元(也稱為最小的原子單元),則滿足***范式. 例如:顧客表(姓名、編號、地址、……)其中"地址"列還可以細分為國家、省、市、區等。
第二范式
在***范式的基礎上更進一層,目標是確保表中的每列都和主鍵相關(一是表必須有一個主鍵;二是沒有包含在主鍵中的列必須完全依賴于主鍵,而不能只依賴于主鍵的部分) 如果一個關系滿足***范式,并且除了主鍵以外的其它列,都依賴于該主鍵,則滿足第二范式. 例如:訂單表(訂單編號、產品編號、定購日期、價格、……),"訂單編號"為主鍵,"產品編號"和主鍵列沒有直接的關系,即"產品編號"列不依賴于主鍵列,應刪除該列。
第三范式
在第二范式的基礎上更進一層,目標是確保每列都和主鍵列直接相關,而不是間接相關(另外非主鍵列必須直接依賴于主鍵,不能存在傳遞依賴). 如果一個關系滿足第二范式,并且除了主鍵以外的其它列都不依賴于主鍵列,則滿足第三范式. 為了理解第三范式,需要根據Armstrong公里之一定義傳遞依賴。假設A、B和C是關系R的三個屬性,如果A-〉B且B-〉C,則從這些函數依賴中,可以得出A-〉C,如上所述,依賴A-〉C是傳遞依賴。 例如:訂單表(訂單編號,定購日期,用戶編號,用戶姓名,……),初看該表沒有問題,滿足第二范式,每列都和主鍵列"訂單編號"相關,再細看你會發現"用戶姓名"和"用戶編號"相關,"用戶編號"和"訂單編號"又相關,***經過傳遞依賴,"用戶姓名"也和"訂單編號"相關。為了滿足第三范式,應去掉"用戶姓名"列,放入用戶表中。
總結
范式優點:
(1) 范式化的更新操作通常比反范式化要快(2)當數據較好地范式化時,就只有很少或者沒有重復數據,所以只需要修改更少的數據(3)范式化的表通常更小,占用更小的內存,所以處理速度更快(4)很少有多余的數據,意味著檢索列表時更少需要distinct和group by語句時間
范式缺點:
符合范式的schema設計,查詢時通常需要關聯查詢
schema設計簡單原則
- 盡量避免過度設計,例如會導***其復雜查詢的schema設計,或者有很多列的表設計;
- 使用小而簡單的合適數據類型,除非真是數據模型中有確切的需要,否則應該盡可能地避免使用NULL值
盡量使用相同的數據類型存儲相似或相關的值,尤其是要在關聯條件中使用的列;
- 注意可變長字符串,其在臨時表或者排序時可能悲觀的按***長度分配內存
- 盡量使用整型標識列
- 避免使用mysql已經遺棄的特性,例如指定浮點數的精度(可用decimal代替),或者整數的顯示寬度
小心使用ENUM和SET,盡量避免使用;避免使用BIT;
創建高性能索引
高性能的索引策略
獨立的列 我們通常會看到一些查詢不當地使用索引,或者使得MySQL無法使用已有的索引。如果查詢中的列不是獨立的,則MySQL就不會使用索引。“獨立的列”是指索引列不能是表達式的一部分,也不能是函數的參數。
前綴索引和索引的選擇性 有時候需要索引很長的字符列,這會讓索引變得大且慢。一個策略是前面提到過的模擬哈希索引。通常可以索引開始的部分字符,這樣可以大大節約索引空間,從而提高索引效率,但是也會降低索引的選擇性。(索引選擇性是指不重復的索引值和數據表的記錄總數的比值)索引的選擇性越高則查詢效率越高。
多列索引 一個常見的錯誤是:為每個列創建獨立的索引,或者按照錯誤的順序創建索引。但實際上,在多個列上建立獨立的單列索引大部分情況下并不能提高MySQL的查詢性能。5.0和之后的版本引入“索引合并”的策略,一定程度上緩解了這個問題。(但沒有徹底解決)
索引合并策略有時候是一種優化的結果,但實際上更多時候則說明了表上的索引很糟糕
當出現服務器對多個索引做相交操作的時候,意味著需要一個包含所有相關列的多列索引而不是多個獨立的單列索引
當服務器需要對多個索引做聯合操作時,通常需要耗費大量的CPU和內存資源在算法上的緩存、排序和合并。優化其不會把這些計算到“查詢成本”中,優化器只關心隨機頁面的讀取。這會使得查詢的成本被“低估”,導致該執行計劃還不如直接走全表掃描。選擇合適的索引列順序。 正確的順序依賴于使用該索引的查詢,并且同時需要考慮如何更好地滿足排序和分組的需要。 在一個多列B-TREE中,索引列的順序意味著索引首先要按照最左列進行排序,其次是第二列,以此類推。
對于如何建立索引列的順序有一個經驗法則:將選擇性***的列放到索引最前面。
索引的優點
a. 通過創建唯一性索引,可以保證數據庫表中每一行數據的唯一性。b. 可以大大加快數據的檢索速度,這也是創建索引的最主要的原因。c. 可以加速表和表之間的連接,特別是在實現數據的參考完整性方面特別有意義。d. 在使用分組和排序子句進行數據檢索時,同樣可以顯著減少查詢中分組和排序的時間。e. 通過使用索引,可以在查詢的過程中,使用優化隱藏器,提高系統的性能。
索引的缺點
a. 創建索引和維護索引要耗費時間,這種時間隨著數據量的增加而增加。b. 索引需要占物理空間,除了數據表占數據空間之外,每一個索引還要占一定的物理空間,如果要建立聚集索引那么需要的空間就會更大。c. 當對表中的數據進行增加、刪除和修改的時候,索引也要動態的維護,這樣就降低了數據的維護速度。
備注:因為索引非常占內存,所以索引也需要謹慎添加,那些字段需要索引。
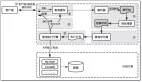
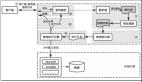
mysql查詢生命周期
- 客戶端發送一條查詢給服務器 ;
- 服務器先查詢緩存,如果***了緩存,直接返回結果;否則,進入下一步;
- 服務器進行sql解析、預處理,再由優化器生成對應的執行計劃;
mysql根據優化器生成的執行計劃,再調用存儲引擎API來執行查詢;
將查詢結果返回給客戶端;
SHOW FULL PROCESSLIST可查看當前狀態;sleep:線程正在等待客戶端發送新的請求;Query:線程正在執行查詢或者正在將結果發送給客戶端;Locked:該線程正在等待表鎖;Analyzing and statistics:線程正在收集存儲引擎的統計信息,并生產查詢的執行計劃;Coping to tmp table:線程正在執行查詢,并將其結果復制到臨時表中;Sorting result:線程正在對結果集進行排序;Sending data:線程可能在多種狀態之間傳送數據,或者正在生成結果集,或者正在向客戶端發送數據;
查詢性能優化
1、慢查詢基礎:優化數據訪問
低效查詢分析方法:
a. 確認應用程序是否在檢索大量超過需要的數據。通常意味著訪問了太多的行,也有可能訪問太多的列。b. 確認mysql服務器層是否在分析大量超過需要的數據行。
低效查詢典型案列:
a. 查詢不需要的記錄b. 多表關聯時返回全部列c. 總是取出全部列d. 重復查詢相同的數據
衡量查詢開銷的三個指標:
a. 響應時間 響應時間包括服務時間和排隊時間;服務時間:是指數據庫處理這個查詢真正花了多長時間,排隊時間:服務器因為等待某些資源而沒有真正執行查詢的時間(可能是IO,行鎖等等);
b. 掃描的行數;
c. 返回的行數 較短的行的訪問速度更快,內存中的行比磁盤中的行訪問速度更快;較短的行數,是在內存中查詢,當行數較多時則在磁盤中查詢;
將查詢方式進行重構
a. 一個復雜查詢還是多個簡單查詢;
b. 切分查詢(大查詢分為小查詢,例如:大掃描行數查詢切分成多個小掃描行數的查詢);
c. 分解關聯查詢,優點:讓緩存效率更高;讓單個查詢減少鎖競爭;在應用層做關聯,容易對數據庫進行拆分,提高系統性能;減少冗余記錄的查詢;