













區塊鏈與機器學習如何創造出最給力的人工智能?
通過基于區塊鏈市場的數據訓練獲得機器學習模型,能夠有潛力來創造世界上***影響力的人工智能。他們將兩個部分組合起來:私有機器學習,這可以進行在私密信息上進行訓練,而且不用泄露信息,同時基于區塊鏈給予激勵,這樣做可以讓這些系統吸引***的數據和模型,讓它們更加聰明。***的結果會組成一個開放式的市場,任何人可以售出他們的數據并且保留私密數據,同時開發人員也可以通過激勵為他們的算法吸引***的數據。
建造這些系統是非常具有挑戰性的,所需要的建造基石也正在創建,但是從現在的簡單初始版本看起來,這是有可能的。我相信這些市場會將我們從現在的Web 2.0時代轉移到代碼和算法開放競爭的Web3.0時代,并且這些算法和數據都可以直接獲得收益。
起源
這個想法來自于2015年和來自Numerai基金的Richard之間的討論。Numerai是一個對沖基金,它會把加密貨幣市場的數據發送給任何想要和做股票市場模型的數據專家。Numerai將***的模型提交到一個“元模型“,交易這個元模型,并且支付給建立這些模型平臺的數據科學家費用。
讓數據科學家進行競爭看起來是個非常好的主意。所以這就帶來了更多思考:我們能夠建立一個完全去中心化版本的系統,能夠應用任何場景?我認識這個答案是肯定的。
創建
舉例來說,我們嘗試在去中心化交易所上建立完全去中心化的系統來交易數字貨幣。這是眾多潛在的創建方法之一。
數據 數據提供者以數據為權益并且給模型建立者使用。
模型建立建模人員選擇需要使用什么數據并且創建模型。培訓使用安全的計算方式進行,這也允許模型可以在不需要泄露底層數據的情況下進行訓練。模型需要有不同權重。
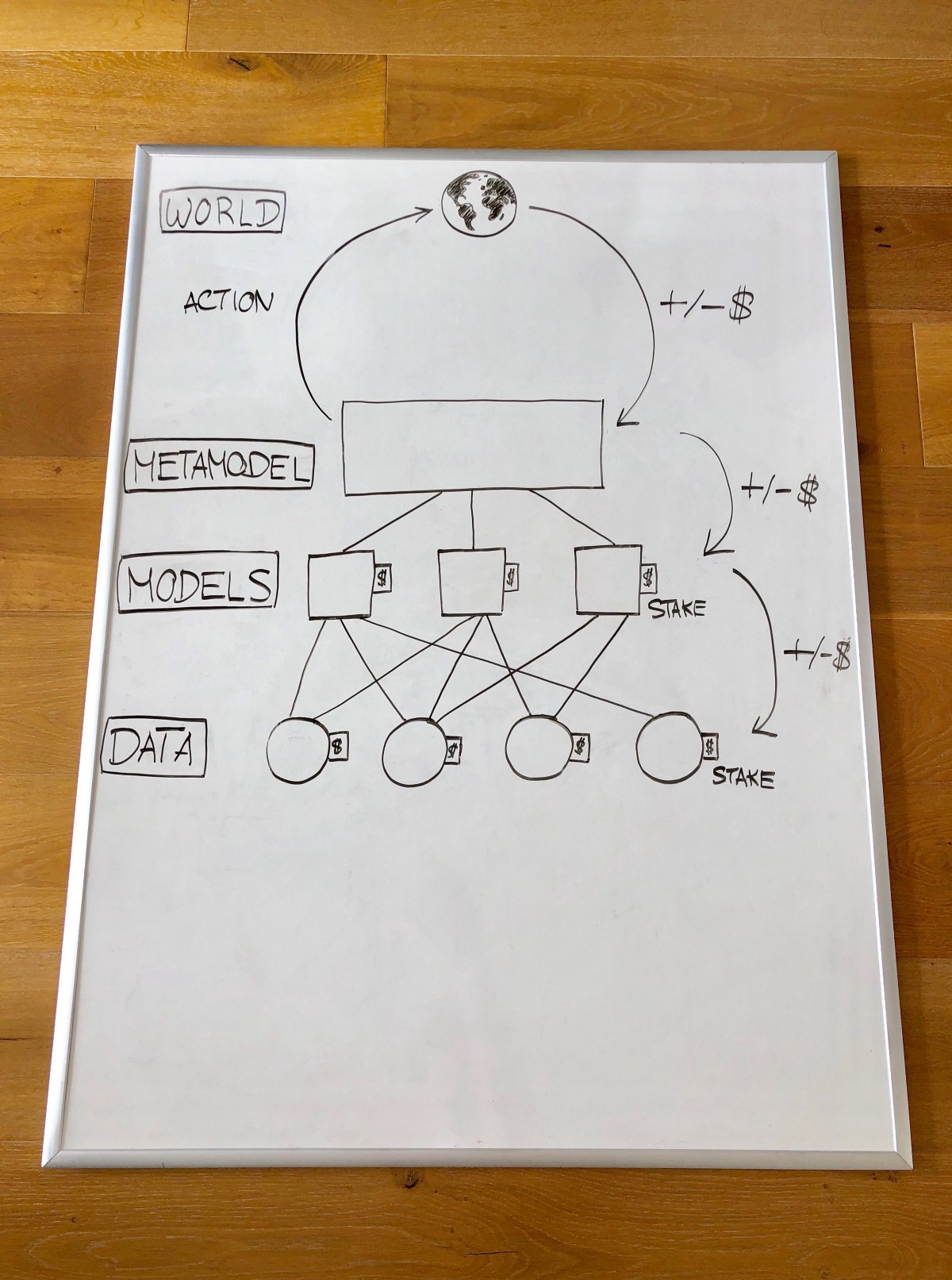
建立元模型元模型是基于考慮到每個模型權重的算法上而創建的。
創建元模型是可選的—你可以想象很多模型沒有和元模型結合使用。
使用元模型智能合約使用元模型并且通過去中心化交易機制在鏈上進行交易。
分發收益/損失 在一段時間后,交易會產生收益或者損失。這部分利潤或者損失就會基于貢獻多少分發給這個元模型的貢獻者。那些做出負貢獻的模型會被拿走部分或者全部的抵押資金。
驗證計算對每步的計算是中心化的,但是驗證和挑戰會使用像Truebit或者使用安全多重計算的去中心化系統。
存儲 數據和模型會存儲在類似IPFS或者在多重角色計算網絡的節點上,因為鏈上的存儲會太昂貴。
是什么驅動了這樣的系統?
吸引全球***數據的激勵 吸引數據的激勵模式是這個系統最重要的部分,因為數據是機器學習的限制因素。同樣,比特幣通過開放的激勵建立了世界上***大的算力網絡,合適的數據激勵架構也會吸引世界上***的數據來為你應用。并且幾乎不可能禁止來源于幾千或者百萬處的數據。
- 代碼間的競爭 在模型/代碼間創建公開的競爭,這之前從未出現過。在去中心化的Facebook上發布幾千個競爭性的新聞發送算法。
- 獎勵透明 數據和模型的提供者可以看到他們獲得了和提交任務相關的公平收益,因為所有計算都是可驗證的,這會使得人們更加愿意參加這類項目。
- 自動化 通過鏈上操作,并且直接從token上獲得價值,創建了自動化和無需信任的閉環回路。
- 網絡效果 多面網絡會受到用戶,數據提供者和數據專家的影響,這也使得系統自我強化。系統能夠表現的更好,就會吸引更多的資本,這也意味著更有潛力的回報,會吸引更多的數據提供者和數據專家,他們會讓系統更加智能,從而吸引更多資本,形成良性循環。
隱私
除了以上所說的點,一個主要的功能就是隱私性。它可以讓1)用戶提交太隱私并且不能分享的數據 2)防止數據的經濟價值和模型被破壞。如果讓非加密數據公開,數據和模型就可以免費復制并且被別人使用,但是那些人卻沒有作任何貢獻(“搭便車”問題)
解決這個問題的部分方案是將數據銷售隱私化。盡管買家選擇重新銷售或者釋放數據,它的價值也會隨時間減少。但是,這種方法限制了短期使用案例,并且也還是存在典型的隱私問題。因此,更為復雜但是有效的解決方案就是使用某種安全計算方法。
安全計算
安全計算方法讓模型可以在不泄露數據本身的基礎上進行訓練。現在使用和研究的安全計算方法有3種方式:同態加密(HE), 多方安全計算(MPC)和零知識證明(ZKPs)。多方計算目前是私人機器學習使用最廣泛的算法,因為同態加密太慢,而且對于如何將零知識證明加入到機器學習中也不是很明顯。安全計算方法是計算機科學研究的前沿。他們通常會比普通的計算慢到指數級,體現了這個系統的瓶頸,但是這些年提高了很多。
***推薦系統
為了描述私人機器學習的潛力,假設有一個叫做“***推薦系統”的app。它可以通過你的設備看到你在做的任何事情:你的瀏覽歷史,你在app上做的任何事情,手機里面的圖片,定位數據,消費記錄,可穿戴傳感器,信息內容,你家里的攝像頭,AR眼睛上的攝像頭等等。然后它會給你建議:你應該訪問的下個網站,需要閱讀的文章,要聽的音樂或者是要買的產品。
這個推薦系統會非常有用。谷歌,Facebook或者其他現有的數據庫可能都不會有這樣的系統因為它對于你有***的縱向視圖,并且這個系統可以從你的私密不可泄漏的信息中學習。和之前說到的數字貨幣交易系統的案例類似,它會通過關注不同領域的模型(例如:網站推薦,音樂)來運作,進行競爭來獲得用戶加密數據的準入以及像用戶進行推薦,也許甚至是因為用戶貢獻了數據以及對推薦的東西進行專注而像他們付費。谷歌的聯合學習和蘋果的差分隱私是這個私人機器學習方向的一個步驟,但是仍然需要信任,不會允許用戶直接檢驗安全性,并且讓數據保持隱秘。
什么樣的方案可能會首先實行?
我無法非常精確地說明什么樣的構造是***的,但是我有一些想法。我用來評估區塊鏈方案的一個準則是:從物理原生,到數字原生再到區塊鏈原生的一系列研究,越區塊鏈原生,那么就越好。越不那么區塊鏈原生,那么就需要更多的第三方介入,使得增加復雜性和減少使用與其他系統作為構建塊的易用性。
在這兒,我認為如果系統中價值創造是合格的,那么這意味著系統更可能會成功運行—直接來說就是以法幣的方式,更好的選擇就是代幣。這樣就會完成一個純粹,閉環的系統。可以將之前的加密貨幣交易系統和X光線腫瘤識別系統相比較。對后者來說,你需要說服保險公司X光線模型是由價值的,并且去協商多么有價值,然后相信一小部分現在的人從而嚴重模型的成功/失敗。
這并不是說社會使用數字原生系統的正和情況不會發生。就像之前提到的推薦系統也會非常有用。如果和數字市場聯系,有另一種使用案例是模型可以在鏈上進行代碼運行,并且系統的獎勵是代(對于數字市場案例而言),這樣會會創造一個純粹的閉環。現在看起來可能還不是很明朗,但是我期待基于區塊鏈的原生任務會隨著時間而逐漸擴大。
影響
首先,去中心化機器學習市場可以去除現有技術巨頭對數據的壟斷。他們在過去20年標準化以及商品化了互聯網價值創造的主要資源:專有的數據網絡和他們周邊的強大網絡效應。因此,價值創造從數據往算法層面開始轉移。
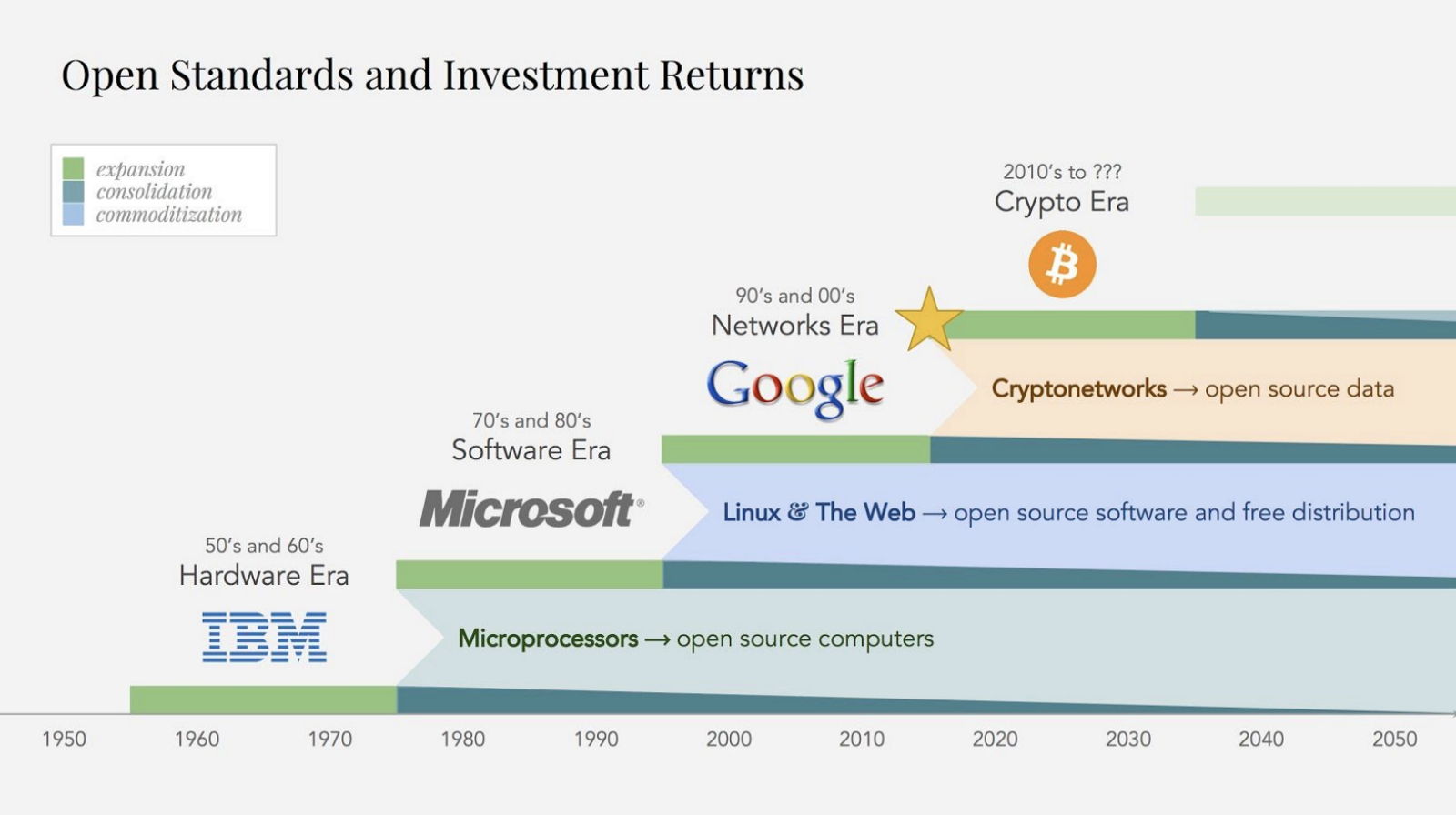
技術上的標準化和商業化循環,我們現在正處在互聯網時代價值壟斷的末尾。換句話說,他們為AI創造了一個直觀的商業模式。
其次,去中心化機器學習市場創造了世界上***力量的AI系統,通過直接的經濟激勵吸引了世界上***的數據和模型。他們的強處隨著多方網絡的效率而增強。由于互聯網2.0時代數據網絡壟斷成為商業化,他們看起來像是下個重新聚合點的候選人。可能我們還需要幾年時間,但是這個方向是正確的。
第三,就像推薦系統展示的那樣,搜索發生了倒置。人們不會去搜索產品,而是產品進行搜索同時競爭為人們服務。每個人也許都有自己喜愛的市場,推薦系統就可以將最相關的內容展示,并且這些內容和個人定義的很相關。
第四,去中心化機器學習市場可以讓我們獲得和Google和Facebook同樣的收益,并且還不需要給出我們的數據。
第五,機器學習可以更快速地發展,因為任何工程師都可以進入到開放的市場獲取數據,而不是只有在Web2.0時代的那幾所大公司的小群體工程師。
挑戰
首先,安全計算模型現在運行速度很慢并且機器學習在計算方面已經很昂貴了。另一方面,安全計算的性能也在逐漸提升。我也看到一些方案可以在過去6個月內完成HE,MPC和ZKP的重大性能提升。計算出特定的數據或者模型值并提供給元模型是很困難的。清理和格式化擁擠的數據是具有挑戰性的。我們希望看到工具,標準化和小型企業能夠聯合解決這個問題。***,創建這種系統的廣義構造的業務模型比創建一個單獨的實例更不明朗。這對于很多新的加密事物都是正確的,包括精選市場。
結論
私人機器學習和區塊鏈激勵的組合可以在廣泛不同的應用中創造***的機器智慧。但是仍然有幾個非常嚴重的技術挑戰。他們的長期潛力是巨大的,并且會改變現有大型互聯網公司擁有數據的現狀。這其實也有點恐怖,因為這類系統可以存在,自我增強,消費私密數據,并且幾乎不可能被關閉,讓我在想是否創造他們會召喚個更加強大的摩洛克。不論如何,這是加密貨幣如何緩慢發展,然后突然進入任何行業的另一個案例。























