存儲Cache丟失導致數據庫無法open的案例
當存儲Cache由于丟失時,我們應該如何處理,讓數據庫重新能夠open起來呢?讓我們聽聽,專家分享的這篇案例。
發現問題
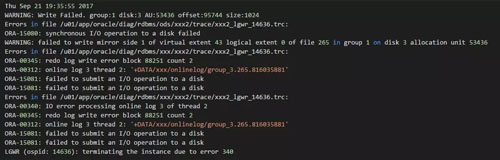
最近某客戶的一套核心數據庫由于存儲問題導致清掉Cache之后無法啟動。首先我們來看看數據庫在啟動的時候報什么錯誤:
錯誤并不復雜。可以看到Oracle這里已經無法正常寫Redo logfile了。
解決思路
由于這套數據庫是非歸檔,只有邏輯備份,因此即使恢復成功也面臨數據丟失的可能性。
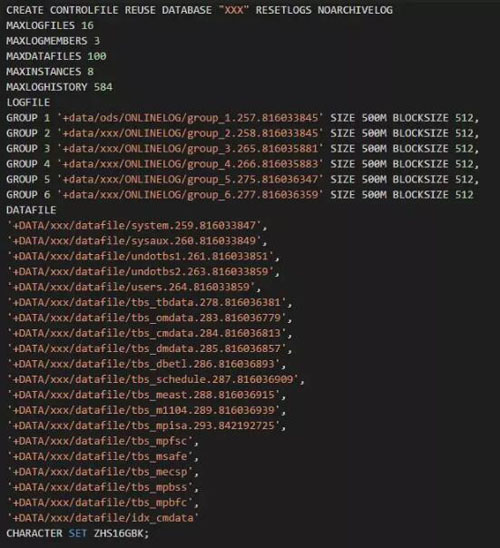
首先我在嘗試進行恢復時,發現居然無法mount數據庫,在mount過程中實例被直接終止了,感覺非常奇怪。也沒有報非常明顯的錯誤。mount過程出錯,那么無疑是controlfile存在異常;由于沒有controlfile備份,因此這里先手工重建控制文件,如下是腳本:
重建完畢后。其實這里我首先嘗試了進行noresetlogs創建,但是發現報錯:

很明顯,Redo logfile有問題。
看來還是只能Resetlogs方式創建。創建完畢之后,嘗試進行了recover database using backup controlfile until cancel恢復操作;然后通過隱含參數強制open發現還是有如下錯誤:
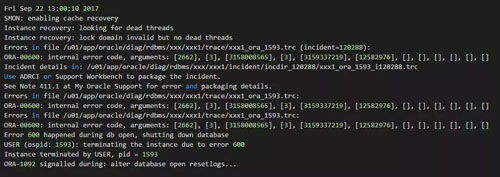
這是非常經典的錯誤了,由于這是scn的問題,而且數據庫版本為11.2.0.3.0,未安裝任何psu。因此這里是可以直接推進scn的。
直接通過10015 event 來推進數據庫的scn;另外由于是異常關機,那么這里Undo 必然也無法進行正常恢復;因此同時設置 undo_management 參數為manual,并同時設置10015 event:
- alter session set events ‘10015 trace name adjust_scn level 2’;
順利打開了數據庫。打開數據庫之后立刻重建數據庫Undo和temp,如下:

再次重啟數據庫之后,發現alert log仍然有一些錯誤。如下所示:
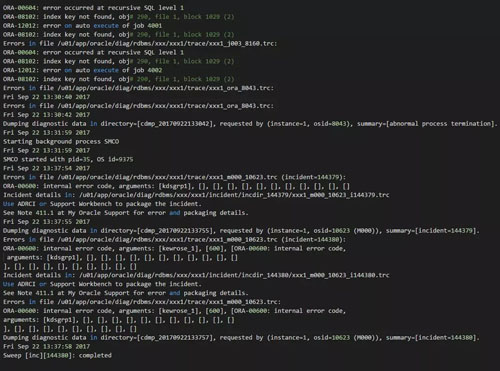
實際上當時在進行恢復時,我手工處理掉了obj# 290。但是進一步檢查發現obj$,col_usage$ ,i_obj4# 都存在問題。而且不一致的記錄還比較多:
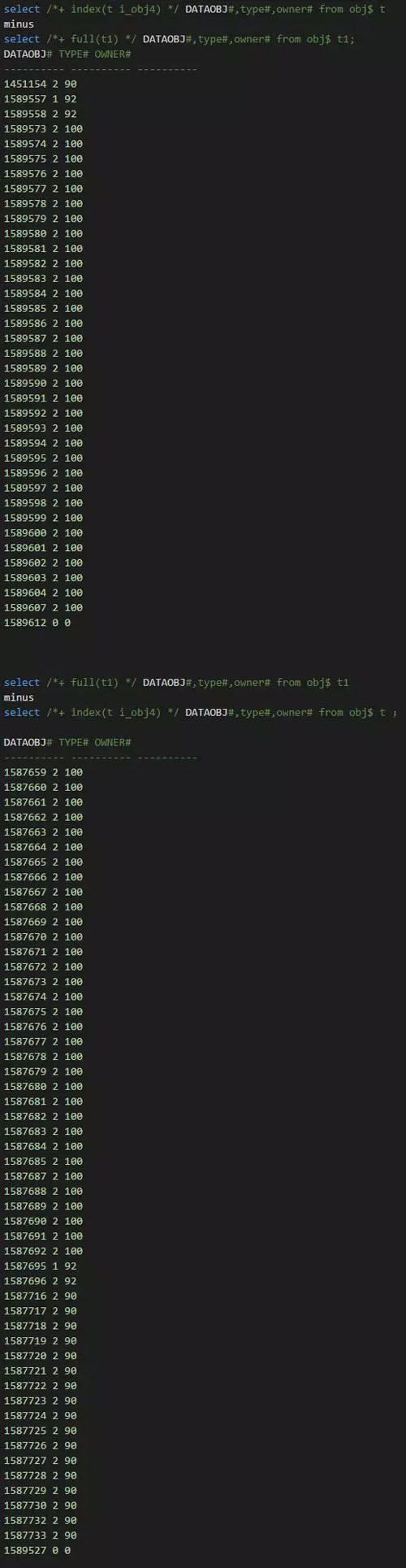
最開始我還嘗試通過bbed修復了2個Block;***發現依然難以處理這個ora-08102錯誤;后續通過上述sql比較發現居然有如此多的記錄不一致。修改起來太過麻煩了。
這里其實本來想嘗試通過重建obj$,i_obj4$,col_usage$ 來解決的。但是擔心有較大的風險,因此這里建議可以進行了數據庫重建。由于obj$這里有問題,expdp操作都報錯,無法執行任何ddl操作。因此***通過exp拆分腳本來進行重建處理。整個數據庫恢復+重建過程將近20小時左右(2tb左右的庫).
由于客戶存儲環境io較差,因此導致整個重建過程比較復雜,比較耗時。我們在開玩笑講到:如果可能的數據庫運行在我們的Zdata環境上,那么數據庫重建過程在2小時內即可完成,而且也不會出現類似故障。因此Zdata的io操作上直接落盤或者寫到Pcie上,不存在數據丟失的風險。
補充說明
1) 由于數據庫很多事務無法正常恢復,導致SMON在不斷嘗試進行事務恢復時報錯,達到一定次數之后會crash實例,進而影響數據庫的重建工作。可通過設置_smon_internal_errlimit 參數來避免該問題。
2) 為了加快exp和imp速度,這里我們利用了管道技術,腳本如下: