













數據庫的“行式存儲”和“列式存儲”
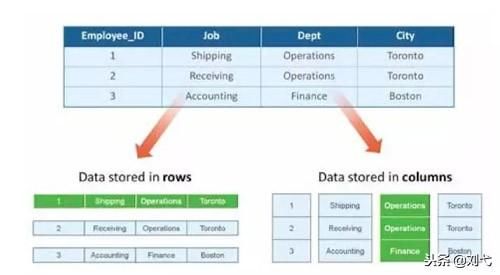
傳統的關系型數據庫,如 Oracle、DB2、MySQL、SQL SERVER 等采用行式存儲法(Row-based),在基于行式存儲的數據庫中, 數據是按照行數據為基礎邏輯存儲單元進行存儲的, 一行中的數據在存儲介質中以連續存儲形式存在。
我們知道,當今的數據處理大致可分為兩大類,聯機事務處理 OLTP(on-line transaction processing)和聯機分析處理 OLAP(On-Line Analytical Processing)。OLTP 是傳統關系型數據庫的主要應用,用來執行一些基本的、日常的事務處理,比如數據庫記錄的增、刪、改、查等等;而 OLAP 則是分布式數據庫的主要應用,它對實時性要求不高,但處理的數據量大,通常應用于復雜的動態報表系統上。
OLTP與OLAP的主要區別
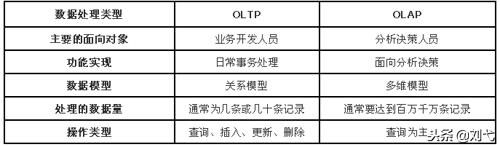
OLTP與OLAP,在數據庫的應用類別方面,為何會出現顯著差別呢?其實,這是因數據庫存儲模式不同而造成的。
行式存儲和列式存儲
傳統的關系型數據庫,如 Oracle、DB2、MySQL、SQL SERVER 等采用行式存儲法(Row-based),在基于行式存儲的數據庫中, 數據是按照行數據為基礎邏輯存儲單元進行存儲的, 一行中的數據在存儲介質中以連續存儲形式存在。
列式存儲(Column-based)是相對于行式存儲來說的,新興的 Hbase、HP Vertica、EMC Greenplum 等分布式數據庫均采用列式存儲。在基于列式存儲的數據庫中, 數據是按照列為基礎邏輯存儲單元進行存儲的,一列中的數據在存儲介質中以連續存儲形式存在。
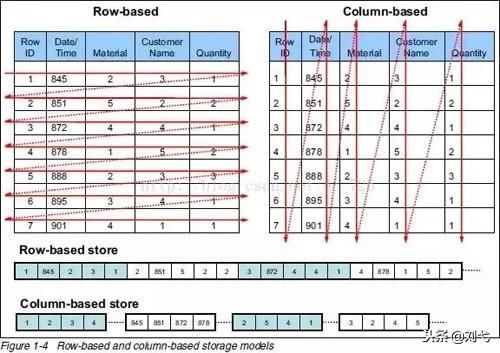
行式存儲的適用場景包括:
1、適合隨機的增刪改查操作;
2、需要在行中選取所有屬性的查詢操作;
3、需要頻繁插入或更新的操作,其操作與索引和行的大小更為相關。
實操中我們會發現,行式數據庫在讀取數據的時候會存在一個固有的“缺陷”,比如,所選擇查詢的目標即使只涉及少數幾項屬性,但由于這些目標數據埋藏在各行數據單元中,而行單元往往又特別大,應用程序必須讀取每一條完整的行記錄,從而使得讀取效率大大降低。對此,行式數據庫給出的優化方案是加“索引”,在OLTP類型的應用中,通過索引機制或給表分區等手段,可以簡化查詢操作步驟,并提升查詢效率。
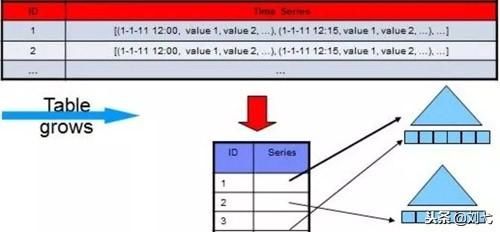
但針對海量數據背景的OLAP應用(例如分布式數據庫、數據倉庫等等),行式存儲的數據庫就有些“力不從心”了。行式數據庫建立索引和物化視圖,需要花費大量時間和資源,因此還是得不償失,無法從根本上解決查詢性能和維護成本等問題也不適用于數據倉庫等應用場景,所以后來出現了基于列式存儲的數據庫。
對于數據倉庫和分布式數據庫來說,大部分情況下它會從各個數據源匯總數據,然后進行分析和反饋,其操作大多是圍繞同一列屬性的數據進行的,而當查詢某屬性的數據記錄時,列式數據庫只需返回與列屬性相關的值,在大數據量查詢場景中,列式數據庫可在內存中高效組裝各列的值,最終形成關系記錄集,因此可以顯著減少IO消耗,并降低查詢響應時間,非常適合數據倉庫和分布式的應用。
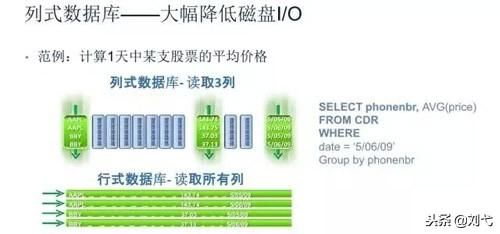
列式存儲引擎的適用場景包括:
1、查詢過程中,可針對各列的運算并發執行(SMP),***在內存中聚合完整記錄集,***可能降低查詢響應時間;
2、可在數據列中高效查找數據,無需維護索引(任何列都能作為索引),查詢過程中能夠盡量減少無關IO,避免全表掃描;
3、因為各列獨立存儲,且數據類型已知,可以針對該列的數據類型、數據量大小等因素動態選擇壓縮算法,以提高物理存儲利用率;如果某一行的某一列沒有數據,那在列存儲時,就可以不存儲該列的值,這將比行式存儲更節省空間。

當然,跟行數據庫一樣,列式存儲也有不太適用的場景。
主要包括:
- 數據需要頻繁更新的交易場景
- 表中列屬性較少的小量數據庫場景
- 不適合做含有刪除和更新的實時操作
隨著列式數據庫的發展,傳統的行式數據庫加入了列式存儲的支持,形成具有兩種存儲方式的數據庫系統。例如,隨著Oracle 12c推出了in memory組件,使得Oracle數據庫具有了雙模式數據存放方式,從而能夠實現對混合類型應用的支持,當然列式數據庫也有對行式存儲的支持比如HP Vertica。總之,沒有***的數據庫,一切都要以實際的數據存儲和分析需求為準!














