下一代大數據即時分析架構--IOTA架構
經過這么多年的發展,已經從大數據1.0的BI/Datawarehouse時代,經過大數據2.0的Web/APP過渡,進入到了IOT的大數據3.0時代,而隨之而來的是數據架構的變化。
Lambda架構
在過去Lambda數據架構成為每一個公司大數據平臺必備的架構,它解決了一個公司大數據批量離線處理和實時數據處理的需求。一個典型的Lambda架構如下:
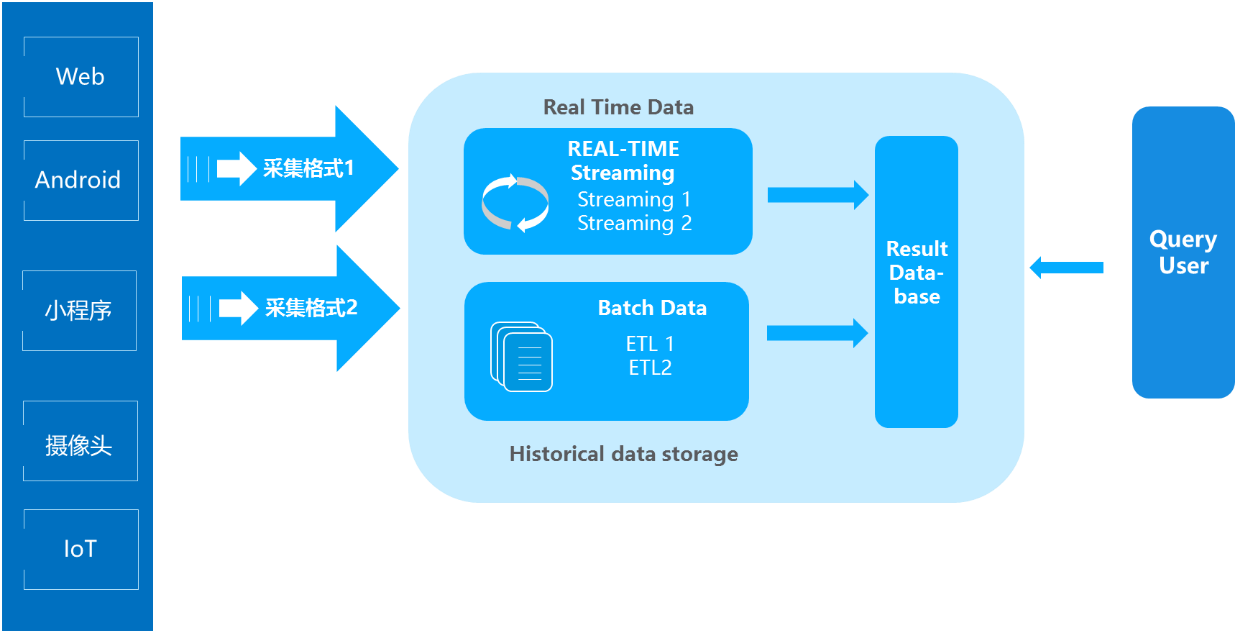
數據從底層的數據源開始,經過各種各樣的格式進入大數據平臺,在大數據平臺中經過Kafka、Flume等數據組件進行收集,然后分成兩條線進行計算。一條線是進入流式計算平臺(例如 Storm、Flink或者Spark Streaming),去計算實時的一些指標;另一條線進入批量數據處理離線計算平臺(例如Mapreduce、Hive,Spark SQL),去計算T+1的相關業務指標,這些指標需要隔日才能看見。
Lambda架構經歷多年的發展,其優點是穩定,對于實時計算部分的計算成本可控,批量處理可以用晚上的時間來整體批量計算,這樣把實時計算和離線計算高峰分開,這種架構支撐了數據行業的早期發展,但是它也有一些致命缺點,并在大數據3.0時代越來越不適應數據分析業務的需求。缺點如下:
- 實時與批量計算結果不一致引起的數據口徑問題:因為批量和實時計算走的是兩個計算框架和計算程序,算出的結果往往不同,經常看到一個數字當天看是一個數據,第二天看昨天的數據反而發生了變化。
- 批量計算在計算窗口內無法完成:在IOT時代,數據量級越來越大,經常發現夜間只有4、5個小時的時間窗口,已經無法完成白天20多個小時累計的數據,保證早上上班前準時出數據已成為每個大數據團隊頭疼的問題。
- 數據源變化都要重新開發,開發周期長:每次數據源的格式變化,業務的邏輯變化都需要針對ETL和Streaming做開發修改,整體開發周期很長,業務反應不夠迅速。
- 服務器存儲大:數據倉庫的典型設計,會產生大量的中間結果表,造成數據急速膨脹,加大服務器存儲壓力。
Kappa架構
針對Lambda架構的需要維護兩套程序等以上缺點,LinkedIn的Jay Kreps結合實際經驗和個人體會提出了Kappa架構。Kappa架構的核心思想是通過改進流計算系統來解決數據全量處理的問題,使得實時計算和批處理過程使用同一套代碼。此外Kappa架構認為只有在有必要的時候才會對歷史數據進行重復計算,而如果需要重復計算時,Kappa架構下可以啟動很多個實例進行重復計算。
一個典型的Kappa架構如下圖所示:
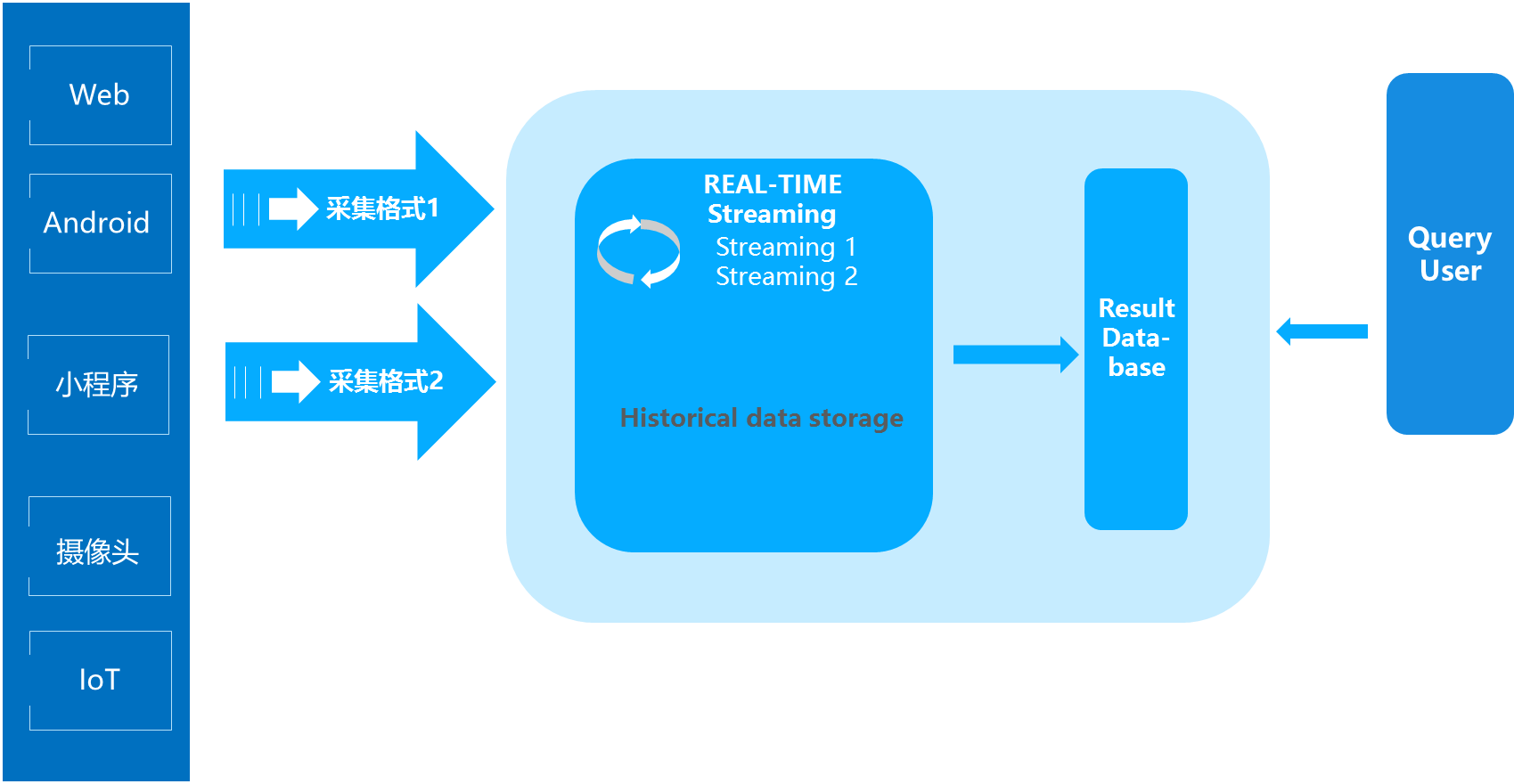
Kappa架構的核心思想,包括以下三點:
- 用Kafka或者類似MQ隊列系統收集各種各樣的數據,你需要幾天的數據量就保存幾天。
- 當需要全量重新計算時,重新起一個流計算實例,從頭開始讀取數據進行處理,并輸出到一個新的結果存儲中。
- 當新的實例做完后,停止老的流計算實例,并把老的一些結果刪除。
Kappa架構的優點在于將實時和離線代碼統一起來,方便維護而且統一了數據口徑的問題。而Kappa的缺點也很明顯:
- 流式處理對于歷史數據的高吞吐量力不從心:所有的數據都通過流式計算,即便通過加大并發實例數亦很難適應IOT時代對數據查詢響應的即時性要求。
- 開發周期長:此外Kappa架構下由于采集的數據格式的不統一,每次都需要開發不同的Streaming程序,導致開發周期長。
- 服務器成本浪費:Kappa架構的核心原理依賴于外部高性能存儲redis,hbase服務。但是這2種系統組件,又并非設計來滿足全量數據存儲設計,對服務器成本嚴重浪費。
IOTA架構
而在IOT大潮下,智能手機、PC、智能硬件設備的計算能力越來越強,而業務需求要求數據實時響應需求能力也越來越強,過去傳統的中心化、非實時化數據處理的思路已經不適應現在的大數據分析需求,我提出新一代的大數據IOTA架構來解決上述問題,整體思路是設定標準數據模型,通過邊緣計算技術把所有的計算過程分散在數據產生、計算和查詢過程當中,以統一的數據模型貫穿始終,從而提高整體的預算效率,同時滿足即時計算的需要,可以使用各種Ad-hoc Query來查詢底層數據。