Tokenformer:下一代Transformer架構

1. 導言
Transformer架構已經成為當今大模型的基石,不管是NLP還是CV領域,目前的SOTA模型基本都是基于Transformer架構的,比如NLP中目前的各種知名大模型,或者CV中的Vit等模型
本次介紹的論文標題為:Tokenformer: Rethinking Transformer Scaling with Tokenized Model Parameters,” 顧名思義,本文提出了Tokenformer架構,其優勢在于增量學習能力:在增加模型尺寸時,無需從頭開始重新訓練模型,大大降低了成本。 本文代碼已開源。
2. Transformer vs Tokenformer - 結構比較
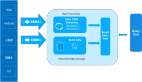
首先我們從頂層設計的角度,對于傳統 Transformer 架構和 本文提出的 Tokenformer 架構進行比較,如下圖所示:

2.1 Transformer 架構
自注意力機制是Transformer的核心,主要包括以下幾個步驟:






如上圖所示,一個Transformer層主要由兩個部分組成:
- 多頭自注意力機制(Multi-Head Self-Attention) :輸入首先經過一個線性投影模塊,以計算注意力模塊的輸入,即矩陣 Q、K 和 V。然后利用子注意力機制計算出Token之間的權重
- 前饋神經網絡(Feed-Forward Network, FFN) :對于注意力層的輸出進行投影,計算出下一層的輸入
2.2 Transformer 架構的缺陷
傳統Transformer在處理token與參數的交互時,依賴于固定數量的線性投影,這限制了模型的擴展性,這句話本身較難理解,因此接下來詳細論述架構的缺陷。
2.2.1 模型的拓展性是什么
模型的拓展性(Scalability)指的是模型在需要更強大性能時,能夠有效地增加其規模(如參數數量、計算能力等)而不導致性能下降或計算成本過高的能力。
簡而言之,拓展性好的模型可以在保持或提升性能的同時,靈活且高效地擴大其規模。
2.2.2 為什么說傳統Transformer的固定線性投影限制了模型的擴展性

3. TokenFormer的解決方案
為了解決模型維度固定導致的模型缺乏拓展性的問題,TokenFormer提出了一種創新的方法,通過將模型參數視為tokens,并利用注意力機制來處理token與參數之間的交互,從而實現更高效、更靈活的模型擴展。

3.1 模型參數Token化
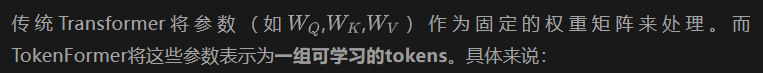
參數Tokens:原本transformer模型的Q、K、V投影層不再是固定的矩陣,而是轉化為一組向量(tokens),例如:

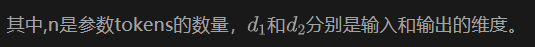
3.2. Token-Parameter Attention(Pattention)層
Pattention層是TokenFormer的核心創新,它通過注意力機制來處理token與參數之間的交互。從而替代原本的Q,K,V,具體過程如下:







4. 總體結構
為方便閱讀再把圖扔到這:

與傳統transformer結構相同,其總體上也包括兩層:多頭自注意力層和前饋網絡層。
4.1 多頭自注意力(Single-Head Variant:


4.2 前饋網絡(Feed-Forward Network, FFN)


這里也可以看到,相對于Transformer,Tokenformer就是將所有的投影層從固定的全連接網絡也變成了Pattention層。
4.3 與transformer的比較

下方公式左側代表傳統Transformer的自注意力機制,右側代表tokenformer的自注意力機制:

從上邊的圖中可以清楚看到,相對于transformer,本論文只是將投影層與連接層替換成了新的層。
5. 可擴展性
之前說過,相對于transformer,tokenformer主要是解決可拓展性的問題,那么假設我們要增加參數數量,或者要增加輸入維度,tokenformer如何進行增量學習?



這樣,模型的參數量可以按需擴展。
初始化策略:新增的參數tokens初始化為零,類似于LoRA技術(Low-Rank Adaptation),確保模型能夠在保持原有知識的基礎上,快速適應新的參數擴展。
6. 實驗部分

與從零重訓練的 Transformer 相比,如上圖所示,Y 軸代表模型性能,X 軸代表訓練成本。藍線代表使用 3000 億個 token 從頭開始訓練的 Transformer 模型,不同的圓圈大小代表不同的模型大小。
其他線條代表 Tokenformer 模型,不同顏色代表不同的Token數量。例如,紅線從 1.24 億個參數開始,擴展到 14 億個參數,其訓練集為從300B token中抽樣出的30B Token。最終版本模型的性能與相同規模的 Transformer 相當,但訓練成本卻大大降低。
黃線顯示,使用 60B個Token來訓練的增量版本在更低的訓練成本下,性能已經比 Transformer 更優。