云端大戰的下一步,邊緣
十多年前,Amazon Web Services(AWS)以一個可提供靈活計算實例的系統的形象出現在了人們面前。對于AWS的誕生,人們持有不同的觀點,比如有人認為Amazon創建AWS的目的就是讓那些在自己平臺中的零售商不用再承擔那些自建系統所帶來的IT負擔。其實在當時,大多數人僅僅將AWS視為Amazon推出的一項附加業務,而Amazon那邊也沒對AWS進行過多的宣傳。
后來,隨著大大小小的各種企業組建接受了AWS的服務,AWS一直處穩健地增長之中。不過直到2015年AWS年度收入超過了50億美元之后,Amazon方面才將AWS的數據公布了出來,這自然是Amazon過人之處。如今,幾乎所有Amazon的營業收入均來自于AWS,它顯然成為了Amazon的增長引擎。
在2006到2015年時,大多數的本地服務器、存儲和網絡廠商均經歷了一個增速放緩期,這時,他們通常會以整體市場表現不好(特別是2008的金融危機)以作為相關的推辭。但事實是,增速與利潤均流向了那些云端的公司,如Amazon、Linkedin、Facebook、Twitter和Google等。
微軟方面則做出了一些關鍵性的轉型,它取消了對客戶和合作伙伴征收“戰略稅”,并最終重新確定了Windows在其自身體系中的重要性。這促成了“Azure時代”的來臨以及微軟對自身的重塑。
Google自然不甘人后,它意識到,企業服務是一個相當穩定并具有很高利潤的商業模式,這可為它帶來持續性地增長。同時,Google也在Android、自動駕駛、Google眼鏡(VR/AR)以及長壽研究等領域中探索。
當我們將時間快進到當前的2018年,云端大戰的上半場已經結束。對于各個云服務玩家來說,他們對未來3-5年的市場變化均擁有一個清晰的認識,那就是:數據。廠商所爭奪的重心正逐漸從功能/性能快速轉變到數據之上。這些數據具有相當大的吸引性,并具有“人們可隨時查看,但不能說走就走”(即,入口是免費的,但從云端拿取數據時必須支付費用)的特征。之后,技術的發展帶來了更多鎖定性的產品,如API(如Google的 Vision APIs)和作為算法的服務(如AmazonLex的會話接口)。
目前,云廠商都關注的一點還在于物聯網技術的發展,而這將推動物聯網邊緣(IoT edge)技術的出現。在定義中,物聯網是一套需要本地智能計算支持才能生成大量數據的智能系統。
而物聯網邊緣將成為一種挑戰,是因為現在的云計算并沒有為物聯網的到來做好準備。如果這個問題不能得以解決,那么云計算的增長勢必會具有一個增長瓶頸。Gartner分析師Thomas Bitman在他的“邊緣將吃掉云計算”(The Edge will Eat the Cloud)文章中寫到,“云計算具有很棒的靈活性...但是它有克服不了物理問題:數據的重量和光的速度”。
云供應商自然沒忽視這一點,他們正在想辦法以解決這個問題。今年2月,Google收購了LogMeIn的Xively物聯網平臺,而今年4月,微軟則宣布它對于物聯網方面的支出將提升兩倍,達到50億美元以上。
這是因為,這些云廠商意識到了他們失去了IT市場中很大的一部分,及物聯網/邊緣市場。而且,他們也明白,如果不能解決現有的問題,他們現有的云收入很可能就會受到極大的影響。因為物聯網邊緣所產生的數據量級將使得那些存儲在云數據中心中的數據相形見絀。
目前的云產品之所以不能解決物聯網邊緣的問題,是因為云計算的設計原則是與那些邊緣需求并不相關。
相比于云計算,物聯網和邊緣系統具有截然不同的特性:
具有占地面積小,功耗敏感的軟件堆棧。軟件不可能被***制地擴展,而在云中添加容器的成本又不可能為零。因此,我們需要進行優化,以盡量減少內存和CPU的占地面積。盡管在進行大規模的部署時,這會為企業帶來更大的利益,但是當在快速解決重要挑戰時,它反倒成為了一個問題。而物聯網邊緣則正好相反,物聯網邊緣可以設計在一個非常小的設備或傳感器上,幾乎不會占用額外的軟件空間。
延遲可變。從邊緣設備到云的延遲可能從幾百毫秒到***延遲不等。而云端的延遲則是由跨虛擬機和跨區域的實際情況決定的,往往更加穩定。
多樣的網絡。邊緣堆棧可在多種不同的網絡中運行。一些邊緣計算可以通過以太網、蜂窩(Cellular)、衛星與WiFi進行連接。而云計算一般只能通過標準化的有線連接、以太網類網絡系統進行聯通。
不可預測的帶寬。在物聯網中,帶寬也可能是變化的,軟件需要能夠應對這一問題。
偶發連接性。物聯網/邊緣系統的連接具有偶發性。對于那些列車和貨船來說,每當他們在一個車站或碼頭停靠時,它們都需要對網絡進行重新偶發連接。這也適用于那些小型承包商偶爾對物聯網設備進行連接的情況。
而伴隨著公司開始通過AI和數據以塑造出自身的互聯網邊緣系統,我們還是要記住歷史告訴我們的一些原則:
開放API。企業應該使用一個開放的API平臺,而不是鎖定在某一云供應商的平臺之上。
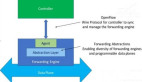
結構。我們需要了解到多個物聯網系統與區域和全球云系統的連接實際上構建了一個數據結構。我們確保應用程序能夠訪問全系統的單一數據,以便數據移動不會導致重寫應用程序。
在當地行動、在全球學習。AI及其邊緣機器學習的子分支需要企業具備本地和獨立行為的能力,以便在不依賴云的情況下有效應對當地的情況。 話雖如此,系統/結構仍需要以一種可從全部邊緣進行全方位學習的方式,然后將該智能反饋到每個邊緣。
不要將系統設置的過于龐大。將所有控制和管理功能都放在云中,反而可能會是系統更容易出現故障。該系統應該可以被分解為單獨的數據集群, 無論是在邊緣,在區域云中還是在全球云中,這樣就可以將它們進行統一管理或單獨管理。
安全。隨著數據驅動策略將聚合型的智能數據推送到云上,現在我們有了安全機制來確保云中的數據安全。但是邊緣呢?安全策略框架不應該為同一數據進行多次重新創建,這取決于當前數據所在的位置。
云是過去與現在,那么當物聯網時代來臨時,邊緣是否將成為未來?