UCloud分布式數據庫UDDB:技術實現
在此之前,我們介紹過UDDB的功能特性和產品理念,明確了產品的發展方向——基于數據庫中間件來做公有云上的分布式數據庫。在剛開始選擇較為簡單的工程實現復雜度,然后通過公有云這種互聯網服務的快速迭代能力和在線服務能力,不斷的提高對業務的支持度,從而覆蓋更多的業務。最終演進為大數據時代的分布式數據庫解決方案,為互聯網、物聯網、傳統行業的轉型提供海量數據存儲、處理的在線服務。
1.UDDB的技術演進路徑
雖然技術服務于產品,而產品的發展方向體現了根據客戶和市場所做的戰略思考,但是在執行層面上,還只是一個模糊的目標。因此,在技術實現上,需要把執行的路徑想清楚,才能將目標清晰地落地。互聯網創業,強調的是樹目標、定路徑、滾雪球式發展。其中,定路徑是關鍵的一環:向上,必須與戰略規劃很好地對接;往前,每一步都要踩到點上。如此,才能在每一個階段創造價值,吸收資源,發展壯大。
執行路徑的確定,需要回歸到客戶需求上,要深入到客戶業務中,去尋找規律和辦法。通過大量的調研,我們發現目前技術圈的熱點:超大表水平拆分問題,其實并不是客戶主要的痛點,讀寫分離和垂直分庫的需求,反而是沉默的大多數。從技術演進的趨勢來看,水平拆分必然是分布式數據庫最終的目標。但現階段水平拆分對SQL的支持度不高,導致為了做水平拆分,很多業務層必須要做脫胎換骨的改造。因此在數據量或性能要求還沒有到這個程度的情況下,客戶并不希望為了水平拆分做業務層的改造,而是傾向于更保守的讀寫分離和垂直分庫策略。UCloud技術團隊基于客戶的這個訴求,最終確定了這樣一條技術演進路徑:
- 基于數據庫中間件,用最短的時間做到一主多從讀寫分離場景下100% 兼容 MySQL,讓客戶的業務在庫表零變動、代碼零改動的情況下,使用上UDDB;
- 在垂直分庫場景下對MySQL的 100%兼容,讓一部分有垂直分庫需求的客戶,只需要調整好庫表位置,即可將業務接入UDDB;
- 逐步完善對水平拆分的支持,在產品推出初期,功能對齊業內主流數據庫中間件。后續進一步完善對SQL和事務的支持,結合對存儲系統(MySQL)的優化、裁減或替換,實現最終的產品目標。
在技術演進上,三個階段并非割裂,每一個階段目標的達成,都為下一個階段的目標做好鋪墊。在讀寫分離和垂直分庫場景下,實現對MySQL的100%兼容,核心在于構建一個完全對齊MySQL的語法解析器,解析完成后識別SQL的操作類型,即可進行讀寫分離;識別SQL的作用對象(庫/表/視圖),即可在垂直分庫場景下,將SQL進行有效路由和透傳;語法解析器的完善和成熟,又為水平拆分場景下,完善語義分析、分布式執行計劃的生成、優化和執行打下了基礎。
總之,UDDB的最終目標就是通過該技術演進路徑,成為一款基于Shared-Nothing架構的分布式數據庫。
在系統架構和計算模型上,數據庫中間件+MySQL節點的分布式數據庫解決方案和NewSQL產品本質上是一回事。限于本文的主題,關于數據庫中間件和NewSQL討論,在此不作展開。
2.UDDB的技術實現
技術路徑的確定是將產品目標進行落地,而技術實現則是將技術路徑進行落地。到了技術實現的層面,重點有兩個:***是把基礎打好,讓產品的生長有一個牢靠的地基;第二是要進行大膽創新,在時間和人力資源有限的情況下,通過靈活巧妙的辦法滿足客戶的需求或解決客戶的問題。
2.1UDDB的系統架構
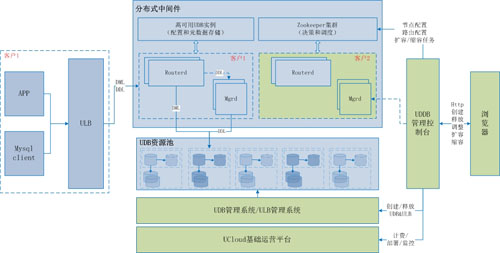
如圖所示UDDB的整個架構主要有三大模塊:
- UDB資源池:等同于UDB產品的資源池, UDDB存儲節點和只讀實例直接復用處于同一可用區的UDB資源。
- 分布式數據庫中間件系統:基于數據庫中間件技術構建的分布式、多租戶數據庫中間件系統由以下幾個模塊構成:Routerd、 Mgrd、高可用UDB實例(負責元數據和配置存儲)、Zookeeper集群(負責決策和調度)。
- UDDB管理控制臺:提供 UDDB 創建、管理、釋放等操作的 Web 界面。
我們可以從以下兩個方面理解該系統架構:
① 從左往右,以業務訪問的視角來看待該架構,可以看到:
- 客戶可以通過標準的MySQL API或者客戶端來訪問UDDB, 客戶的請求均發往ULB,由ULB轉發到某個中間件節點的Routerd模塊。
- Routerd模塊將對客戶請求進行分析:
如果是DML請求,則在進行處理后,直接轉發到相關的UDB節點,然后將各UDB節點的返回結果進行聚合并返回給客戶端;
如果是 DDL請求,則通過Zookeeper集群,將該DDL任務通知到Mgrd模塊。 由Mgrd模塊將該 DDL任務取出、處理并廣播到UDDB下所有UDB節點。廣播完成后,將返回結果按原路經Zookeeper集群遞交到Routerd ,***返回給客戶端。
②從右往左,以系統管理的視角來看待該架構,可以看到:UDDB的創建過程基本等同于目前利用數據庫中間件軟件+MySQL實例+負載均衡組件來搭建一個分布式數據庫解決方案的過程。這個過程為眾多開發團隊的研發或者DBA所熟悉, 而UDDB的管理平臺無非是對這些流程做了一個完整的封裝,把這些煩瑣的操作替換為點擊鼠標即可搞定。
2.2SQL解析和路由模塊
UDDB 在架構上注重穩健務實,而在SQL的解析和路由模塊(Routerd)的設計和實現上,則注重規范和專業。
Routerd的核心是一個SQL解釋器。它接收SQL語句,解析其語法和語義,確定該SQL影響哪些UDB節點,然后將SQL轉換成子SQL并下推到相關UDB節點。待UDB節點將結果返回后,可能需要根據原始SQL的語義將結果進行過濾聚合,最終返回到客戶端。
該 SQL 解釋器的完善程度是 Routerd 的一個重要設計指標。SQL 解釋器越完善,則對業務的支持越好,能夠支持的客戶端就越多,從而具備更好的通用性。公有云產品不能限制客戶類型和使用場景,因此通用性是非常重要的指標。
業內不少歷史悠久的數據庫中間件,雖然穩定可靠支撐了不少實際項目,但是其SQL解釋器,卻一直做得不夠好。考察業內各種數據庫中間件的源碼實現,我們可以看到, 不少中間件的實現存在兩個問題:
①有的中間件沒有獨立的SQL語法解析模塊,而是直接復用其他數據庫(如SqlLite)的語法解析器,或者開源SQL解析庫(如alibaba druid)。短期內,這種做法的確能夠讓項目迅速得以推進,但是后續功能的擴展卻往往受制于該SQL語法解析器,因此不利于產品的長期發展。
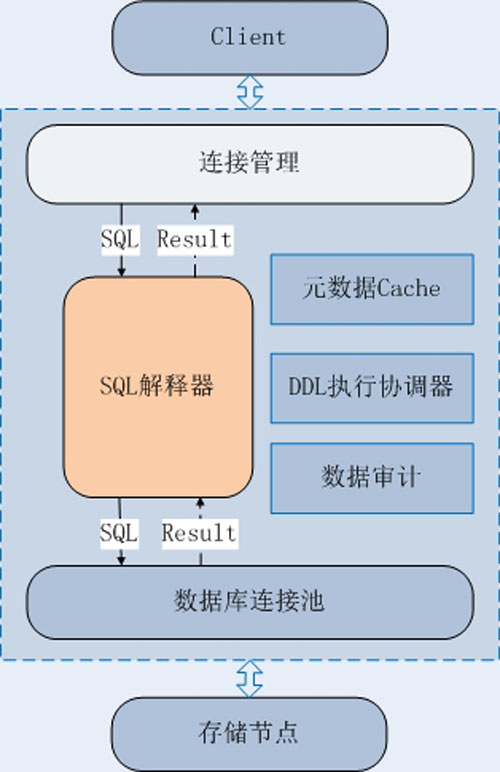
②有的數據庫中間件有獨立、規范的語法解析器,但是在語義解析上做的不夠專業,這些中間件一般的解析流程如圖:
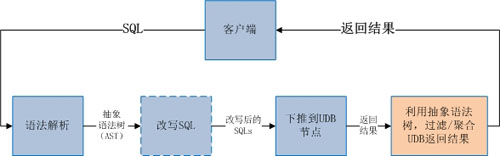
這樣雖然也能夠讓中間件工作,但是SQL的生成和結果的過濾聚合,都依賴抽象語法樹(AST)來完成。然而AST結構復雜,攜帶信息也有限,使用AST來做SQL的生成和結果的過濾聚合,一方面會帶來編程上的復雜度;另一方面也不能執行一些復雜的操作,比如 group by、order by、distinct、limit和集函數同時存在的SQL語句的聚合操作,因此很難實現通用性和可擴展性。
如何做好Routerd的通用性? 可以從兩個方面著手:
***是基于Lex&Yacc構建一個獨立、規范的語法解析模塊。讓研發團隊做到對SQL語法圖和SQL語法解析實現,做到了如指掌。這樣才能在有Bug時迅速修復,需要添加新功能時能夠立即支持。
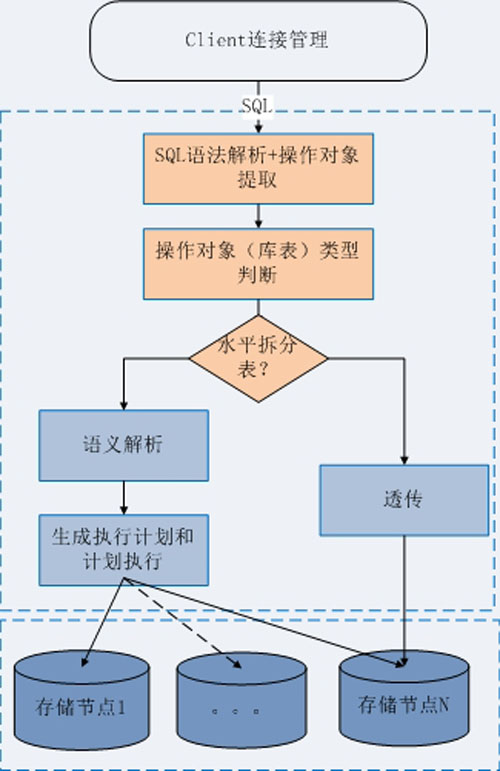
第二是采用類似數據庫系統實現的方式,來實現Routerd的語義解析。如大家所知,通用的數據庫系統,執行一條SQL有規范的流程如圖:
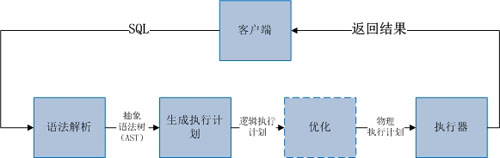
流程可以概括為語法解析、生成執行計劃、執行計劃優化(查詢優化)和執行4個步驟。每一個步驟能夠很好地解耦,步驟之間通過約定的數據結構來交互。這些數據結構中,執行計劃是最核心的,它詳細描述了SQL的語義、涉及到哪些數據庫內部對象以及對這些內部對象操作的順序。
參考數據庫系統的SQL解釋流程,UDDB的Routerd模塊的流程是:
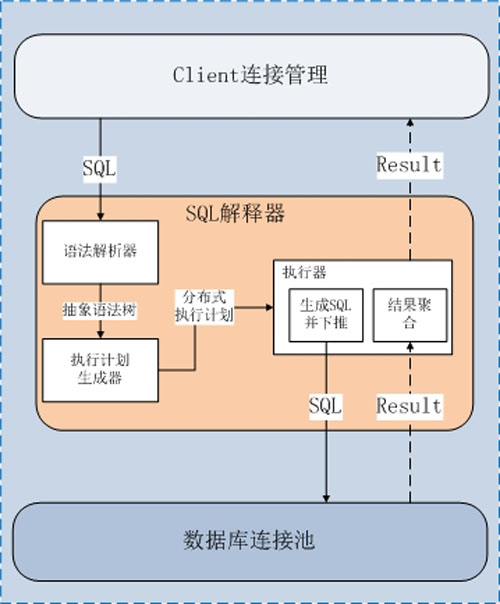
Routerd中的分布式執行計劃:一方面是對抽象與語法樹結構更加精簡、扁平的描述,讓子SQL的生成更方便;另一方面,加入SQL結果過濾聚合的控制信息,方便對UDB節點返回結果的提取、過濾和聚合。
經過一年多的演進和迭代,UDDB的分布式執行計劃和計劃執行在逐步完善。從最初實現對單表SQL,以及落到同一節點 的JOIN SQL的100%支持,到支持多表跨節點Join、分布式事務這兩個核心功能(分布式事務功能目前內測中,跨節點JOIN計劃于2018年上半年推出)。實踐證明,通過合理的架構,能夠讓UDDB從一款簡單的中間件出發,走向更開闊的未來,成為基于MySQL并保留MySQL原生部署和運維體驗的,真正的分布式數據庫。同時,引入和數據庫內核同樣的架構,這意味著還可以添加執行計劃優化的環節,對分布式執行計劃進行優化,最終不僅在功能上對齊單機數據庫,在性能上也有不斷優化的空間。
2.3讀寫分離模式100%兼容MySQL
接下來我們將給出讀寫分離100%兼容MySQL的一個創新性的技術實現供業內參考。垂直分庫實現對MySQL DDL、DML語法的100%支持,其原理也類似,在本文中不做贅述。
如果做一款單純的讀寫分離中間件, 在這款中間件中做到100%SQL兼容并不難。 只需要對SQL做輕量的解析,識別SQL的是讀SQL還是寫SQL,然后使用透傳的方法透傳到主從節點即可:
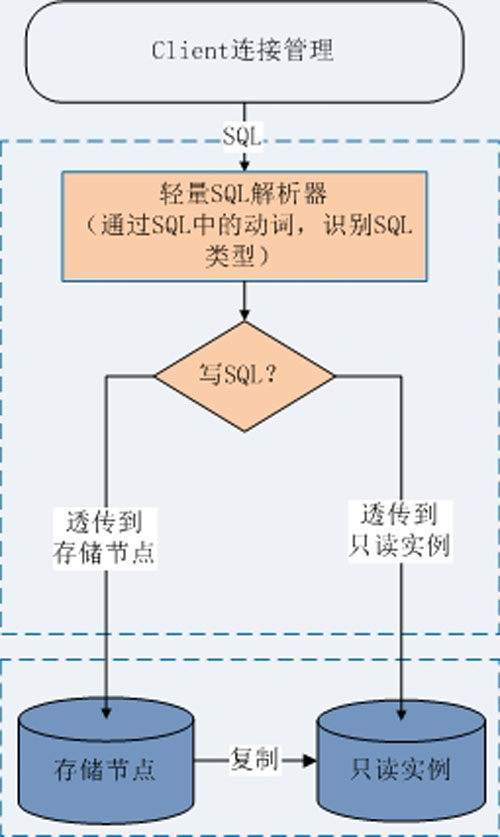
作為一種描述性語言,SQL的語法有一個非常明顯的規律:最前面的單詞必然是操作行為(動詞), 后面是操作對象(名詞)和限制條件。而從操作行為即可完全判斷出該SQL的讀/寫類型(call 存儲過程除外,因為存儲過程可寫可讀)。因此只需要提取前面幾個單詞,即可做正確的路由。
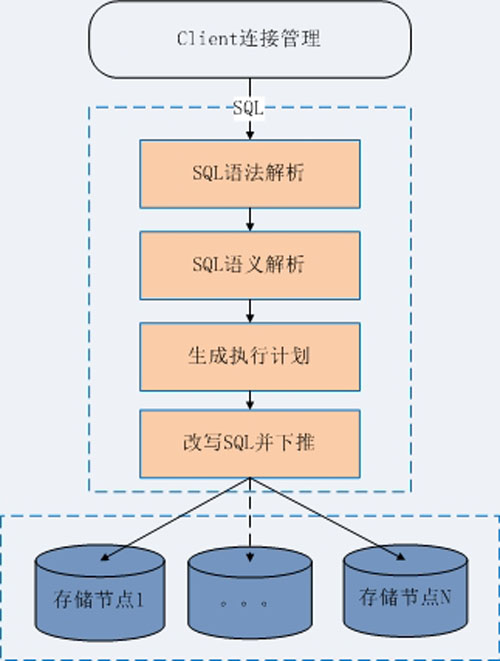
通過這兩個流程可以看到讀寫分離和水平分表兩種模式,在技術實現上的一個矛盾:讀寫分離假定所有的表都是不拆分的普通表, 需要提取SQL中的動作語義來識別讀寫SQL,繼而將SQL進行透傳; 而水平分表模式下,則需要提取SQL中的作用對象,識別到底是哪幾張表,然后進行表名的改寫(必要時也進行其他子句的改寫)。兩者提取信息的邏輯沒有交集,導致兩種模式無法有機結合。
2.4UDDB的技術創新
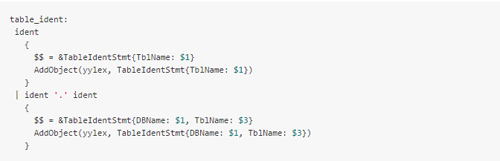
1. 修改語法解析模塊:在解析SQL生成抽象語法樹的同時,將SQL中的庫表名稱提出到一個鏈表中。 假如語法解析器足夠規范,那么必然會有一個或幾個非終結符用于歸約SQL中的庫表名稱。此時,可以在這些非終結符對應的語義動作代碼中,增加將庫表名稱保存到鏈表的操作:
2. 在語法解析之后獲得抽象語法樹以及鏈表,然后掃描鏈表,依次取出該SQL涉及的庫表名稱,結合中間件的元數據信息,判斷這些表是普通表還是水平分表。如果都是普通表,則將該SQL按照讀寫類型透傳到主節點或從節點;如果是水平分表,則再進行語義分析、執行計劃生成和計劃執行。
通過以上兩步,做到讀寫分離模式下,SQL接近100%的兼容以及讀寫分離模式和水平分表模式在一個產品中***共存。 這其中的關鍵點在于語法解析模塊:需要實現一個規范完整并且能夠和MySQL官方對齊的語法解析模塊,有了該模塊即可做到對所有SQL都能夠進行語法解析,在解析過程中進行庫表提取;同時, 需要精心設計該語法解析模塊,將所有SQL的庫表子句,抽象為特定的幾個非終結符,從而方便植入庫表提取代碼。
該方法的優點在于性能和實現上的簡單:庫表的提取,充分復用了語法解析過程,沒有額外的開銷;庫表類型(普通表/水平拆分的大表)的判斷,則只需要掃描提取出的庫表鏈表即可完成,性能開銷幾乎可以忽略不計;實現上也非常簡單,總共不超過150行代碼。
3.結語
本文介紹了UDDB的技術演進路徑及其背后的系統架構技術實現原理,以幫助客戶解決單機MySQL中的問題、讓客戶業務運行更順暢為宗旨。結合UCloud高水平的數據庫內核開發能力,打造了一個結構規范、實現工整的數據庫中間件,具備獨立完整的語法解析、語義解析、執行計劃生成和計劃執行模塊;我們不斷解決MySQL的兼容性問題,目前已經支持所有的MySQL客戶端管理工具,包括PhpMyAdmin、Navicat、SequelPro等。2018年上半年,我們將實現對分布式事務和分布式Join的原生支持,從而完成對存儲、事務以及SQL執行三大塊的分布式化,最終成為既保留MySQL原生部署和運維體驗,又徹底解決單機MYSQL容量和性能問題的真正的分布式數據庫。