分布式數據庫排序及優化

一、背景
1. 分布式數據庫架構
當前分布式數據庫架構有不少,但是總體架構相差不大,主要組件都包含協調節點、數據分片、元數據節點、全局時鐘。一種常見的分布式架構如下圖:
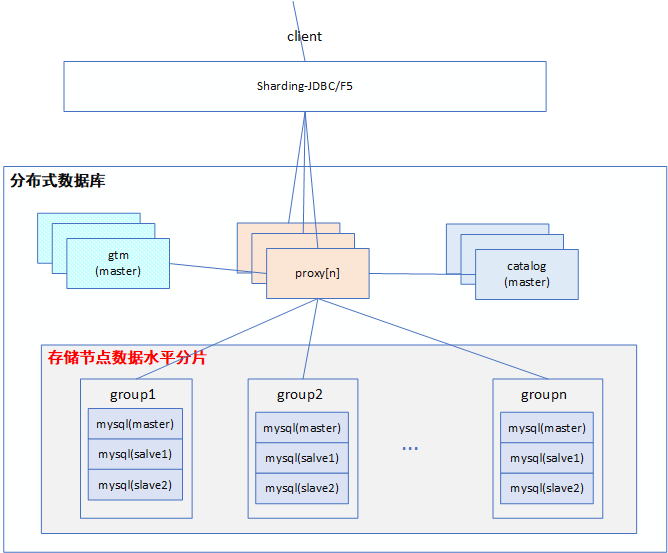
- gtm :全局事務管理器(全局時鐘),一主多備;
- catalog: 元數據管理,一主多備;
- group: 水平分片,每個group由一主多備數據存儲節點組成;
- proxy : 協調節點,無狀態,負責處理客戶端的請求,把請求按照分片規則發送到數據分片,匯總數據分片返回的數據,協同其它組件保證分布式事務的一致性。
2. 排序問題
分布式數據庫中排序也是一種重要的功能。一條查詢排序語句select *from t1 order by field1,需要查詢的數據可能會分布在不同的數據分片中。這就需要proxy對為不同數據分片返回的有序數據進行重排序,然后后給client返回全局有序的數據。
當相關的數據量不大時,proxy可把不同數據分片返回的數據保存在內存中,然后對內存中的數據重排序后返回給client。當相關的數據量比較大時,如果把待重排序數據放到內存中則可能會導致OOM,如果把待重排序數據暫存在proxy的磁盤中,則也有耗盡磁盤的風險并且會存在大量的磁盤IO。下面將介紹一種分布式數據庫排序及優化方法。
二、解決方案
1. 排序方案介紹
為了提高分布式排序的性能,每個數據分片本身也要參與排序。這樣在proxy上得到分片返回的數據是有序的,proxy對有序的數據重排序可以采用歸并排序或者優先級隊列排序方法,大大減輕proxy的壓力。
可以根據proxy內存大小配置sort buffer大小,通常默認為10M。如果一次查詢語句關聯N個數據分片,則需要到sort buffer按照N份進行切分,每個數據分片對應切分后的sort buffer大小為10M/N。
直接在內存中進行,具體步驟如下圖:
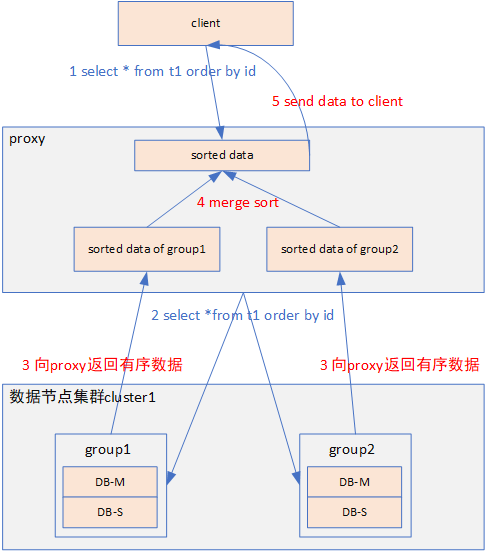
- client向proxy下發排序查詢語句 select *from t1 order by id。
- proxy根據分片鍵以及分片規則向相關的數據分片group1、group2下發排序查詢語句select *from t1 order by id。
- 數據分片在本地對數據進行查詢排序后,發送有序數據到proxy。
- proxy把數據分片返回的有序數據存儲在數據分片對應的sort buffer中,并對有序數據進行歸并排序。
- proxy把歸并排序好的數據發送給client。
2. 排序方案缺陷
這種方法只能滿足小數據量排序,當排序的數據量較大我們可以選擇調大proxy上的sort buffer。但是調大sort buffer會占用更多的內存資源,所以不能無限制的調大sort buffer。
3. 排序優化思路
把數據分片返回的有序數據保存到磁盤上,然后對磁盤數據進行重排序。下面將介紹一種優化方案,針對大數據量進行分布式排序的方法。
三、優化方案
1. 排序方案介紹
由于內存的限制,在內存中對大數據量數據進行歸并排序方案不可行,針對這種情況需要把數據分片返回的數據暫存在磁盤中。具體優化方案步驟如下圖:
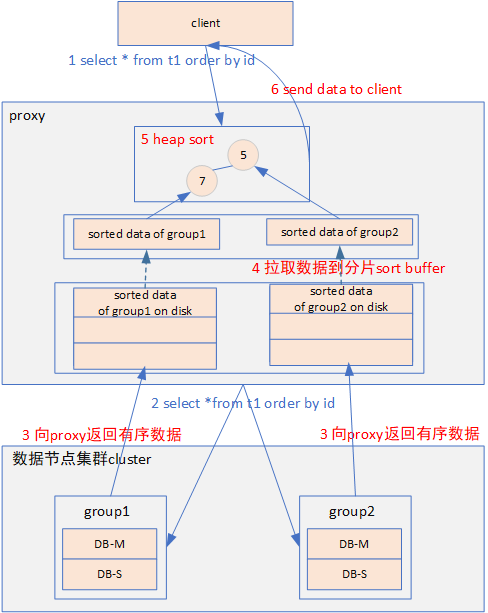
(1) client向proxy下發排序查詢語句 select *from t1 order by id。
(2) proxy根據分片鍵向相關的數據分片group1、group2下發排序查詢語句select *from t1 order by id。
(3) 數據分片在本地對數據進行查詢排序后,發送有序數據到proxy。
(4) proxy把數據分片返回的有序數據存儲在數據分片對應的磁盤文件中。
(5) 使用優先級隊列排序方法進行重排序:
- 每個數據分片出一條數據構建堆,heap包含的節點個數等于數據分片的個數。
- 為了避免優先級隊列排序過程中從磁盤中逐條讀取數據造成的性能問題,proxy從磁盤文件中讀取數據預填充到數據分片對應的sort buffer。
- 每個分片的sort buffer出一條數據構造成一個heap。
- 從堆頂彈出數據發送給client。
- 堆頂數據彈出后,從已彈出節點對應的sort buffer再讀取一條數據push到堆。
- 分片sort buffer中的數據取完后,需要繼續從對應的磁盤文件中拉取數據,對sort buffer進行填充。
- 直至取完所有數據發送到client。
2. 排序方案缺陷
proxy需要收集完所有相關數據分片的有序數據存入磁盤可以解決內存不夠的問題,但是磁盤也是有限的,當數據量太大在proxy上磁盤也可能無法容納需要排序的數據。
proxy上把數據存在磁盤,存在大量的磁盤IO。
以select * from t1 order by field1 limit 100w為例:如果本次查詢的數據在50個數據分片上,則proxy節點需要從每個數據分片上拉取100w數據然后保存到磁盤上。這樣需要保存5000W數據(100w*50),而client只需要100w條數據,浪費了很多網絡帶寬和磁盤IO。
3. 排序優化思路
這種方法是proxy把相關數據分片的有序數據全部拉取到proxy上,然后再進行排序。我們是否分批從數據分片拉取數據,批量數據處理后再從數據分片拉取下一批數據呢?下面將介紹一種分批排序的方法。
四、最終方案
1. 排序方案介紹
proxy上磁盤上不保存數據分片數據,一次從數據分片拉取固定大小的有序數據,proxy把拉取的數據填充到分片對應的sort buffer,sort buffer中數據使用完后再次從對應的數據分片上拉取。具體步驟如下圖:
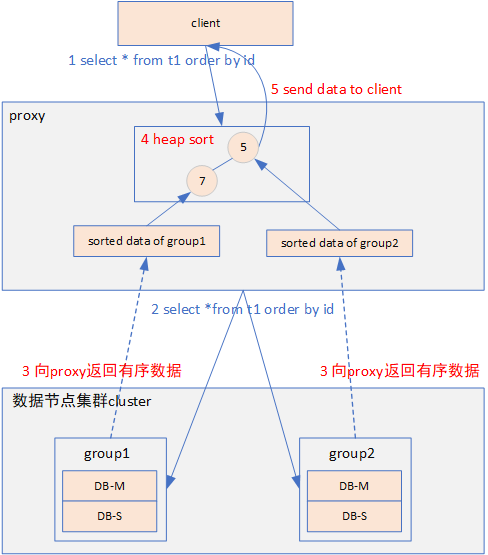
(1) client向proxy下發排序查詢語句 select *from t1 order by id。
(2) proxy根據分片鍵向相關的數據分片group1、group2下發排序查詢語句select *from t1 order by id。
(3) 數據分片在本地對數據進行查詢排序后,發送固定大小有序數據到proxy。
(4) proxy把數據分片返回的有序數據存儲在數據分片對應的sort buffer中。
(5) 優先級隊列排序:
- 每個數據分片對應的sort buffer出一條數據構建堆,堆節點的個數等于數據分片的個數;
- 從堆頂彈出數據發送給client;
- 堆頂數據彈出后,從已彈出節點對應的sort buffer再讀取一條數據push到堆;
- 分片sort buffer中的數據取完后,需要繼續從對應的數據分片節點中拉取數據,對sort buffer進行填充;
- 直至取完所有數據發送到client。
2. 排序方案分析
針對優化方案3.2存在的三個缺陷的解決情況:
(1) 缺陷1:proxy需要收集完所有相關數據分片的有序數據存入磁盤可以解決內存不夠的問題,但是磁盤也是有限的,當數據量太大在proxy上磁盤也可能無法容納需要排序的數據。
解決情況:從圖中可以看出proxy的磁盤上不保存數據分片的數據。
(2) 缺陷2 :proxy上把數據存在磁盤,存在大量的磁盤IO。
解決情況:proxy的磁盤上不保存數據分片的數據,所以不存在磁盤壓力太大問題。
(3) 缺陷3:select * from t1 order by field1 limit 100w為例:如果本次查詢的數據在50個數據分片上,則proxy節點需要從每個數據分片上拉取100w數據然后保存到磁盤上,需要保存5000W數據(100w*50),而client只需要100w條數據,浪費了很多網絡帶寬和磁盤IO。
解決情況:每次從數據分片拉取固定大小的數據,邊排序邊給客戶端返回數據,當給客戶端返回的數據達到100W時則完成本次查詢,網絡帶寬浪費得到大大改善。
假設proxy上數據分片對應的sort buffer大小為2M,從數據分片拉取的數據量:
最壞情況:拉取的數據量為 2M*50+100W,并且不需要保存磁盤。
最好情況:數據分布很均勻,給client返回100w數據后,所有sort buffer分片對應的數據正好基本取空(都剩下一條),此時拉取的數據量為 100W+50。
3. 方案使用限制
(1) 數據分片節點本身支持排序,絕大多數數據分片都是支持排序的。
(2) 數據分片需要支持分批讀取。
以MySQL作為數據分片為例,則需要 proxy上可以使用流式查詢或者游標查詢。另外有些分布式數據庫在設計時就考慮到一些分布式的問題,它們數據分片節點在查詢結束前一直保留上下文,它們的分批讀取性能更高,這里就不再舉例。