從SQL Server到MySQL,近百億數據量遷移實戰
我們成立于 2001 年,作為較早期的教育學習網站,當時技術選型范圍并不大:Java 的版本是 1.2,C# 尚未誕生,MySQL 還沒有被 Sun 收購,版本號是 3.23。工程師們選擇了當時最合適的微軟體系,并在日后的歲月里,逐步從 ASP 過度到 .net,數據庫也跟隨 SQL Server 進行版本升級。
十幾年過去了,技術社區已經發生了天翻地覆的變化。滬江部分業務還基本在 .net 體系上,這給業務持續發展帶來了一些限制,在人才招聘、社區生態、架構優化、成本風險方面都面臨挑戰。集團經過慎重考慮,發起了大規模的去 Windows 化項目。這其中包含兩個重點子項目:開發語言從 C# 遷移到 Java,數據庫從 SQL Server 遷移到 MySQL。
本文主要向大家介紹,從 SQL Server 遷移到 MySQL 所面臨的問題和我們的解決方案。
遷移方案的基本流程
設計遷移方案需要考量以下幾個指標:
- 遷移前后的數據一致性;
- 業務停機時間;
- 遷移項目是否對業務代碼有侵入;
- 需要提供額外的功能:表結構重構、字段調整。
經過仔細調研,在平衡復雜性和業務方需求后,遷移方案設計為兩種:停機數據遷移和在線數據遷移。如果業務場景允許數小時的停機,那么使用停機遷移方案,復雜度低,數據損失風險低。如果業務場景不允許長時間停機,或者遷移數據量過大,無法在幾個小時內遷移完成,那么就需要使用在線遷移方案了。
數據庫停機遷移的流程:
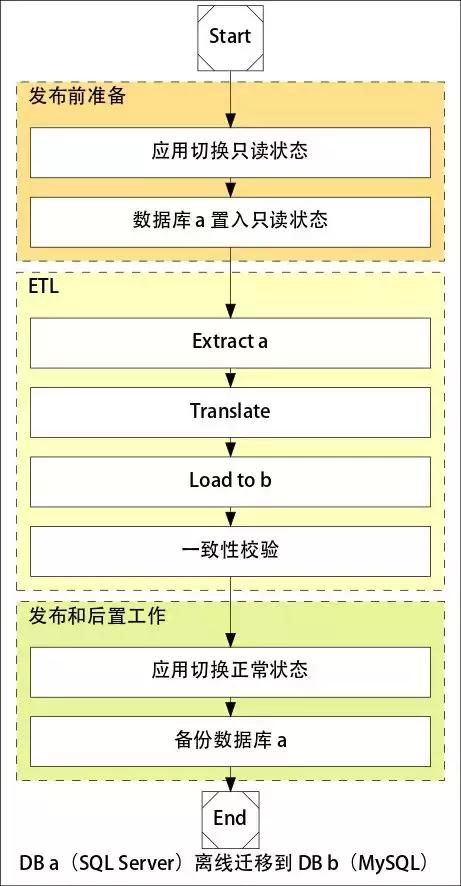
停機遷移邏輯比較簡單,使用 ETL(Extract Translate Load) 工具從 Source 寫入 Target,然后進行一致性校驗,***確認應用運行 OK,將 Source 表名改掉進行備份。
在線遷移的流程:
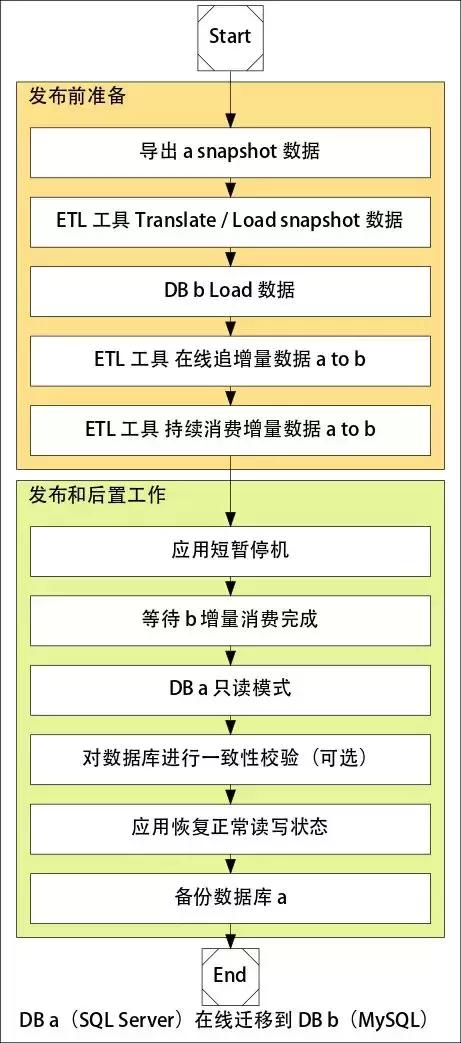
在線遷移的方案稍微復雜一些,流程上有準備全量數據,然后實時同步增量數據, 在數據同步跟上(延遲秒級別)之后,進行短暫停機(Hang 住,確保沒有流量),就可以使用新的應用配置,并使用新的數據庫。
需要解決的問題
從 SQL Server 遷移到 MySQL,核心是完成異構數據庫的遷移。
基于兩種數據遷移方案,我們需要解決以下問題:
- 兩個數據庫的數據結構是否可以一一對應?出現不一致如何處理?
- MySQL 的使用方式和 SQL Server 使用方式是否一致?有哪些地方需要注意?
- 如何確保遷移前后的數據一致性?
- 在遷移中,如何支持數據結構調整?
- 如何保證業務不停情況下,實現在線遷移?
- 數據遷移后如果發現業務異常需要回滾,如何處理新產生的數據?
為了解決以上問題,我們需要引入一整套解決方案,包含以下部分:
- 指導文檔 A:SQL Server 轉換 MySQL 的數據類型對應表;
- 指導文檔 B:MySQL 的使用方式以及注意點;
- 支持表結構變更,從 SQL Server 到 MySQL 的 ETL 工具;
- 支持 SQL Server 到 MySQL 的在線 ETL 工具;
- 一致性校驗工具;
- 一個回滾工具。
讓我們一一來解決這些問題。
SQL Server 到 MySQL 指導文檔
非常幸運的是,MySQL 官方早就準備了一份如何從其他數據庫遷移到 MySQL 的白皮書。MySQL :: Guide to Migrating from Microsoft SQL Server to MySQL 里提供了詳盡的從 SQL Server 到 MySQL 的對應方案。 包含了:
- SQL Server to MySQL - Datatypes 數據類型對應表;
- SQL Server to MySQL - Predicates 邏輯算子對應表;
- SQL Server to MySQL - Operators and Date Functions 函數對應表;
- T-SQL Conversion Suggestions 存儲過程轉換建議。
需要額外處理的數據類型:
在實際進行中,還額外遇到了一個用來解決樹形結構存儲的字段類型 Hierarchyid。這個場景需要額外進行業務調整。
我們在內部做了針對 MySQL 知識的摸底排查工作,并進行了若干次的 MySQL 使用技巧培訓,將工程師對 MySQL 的認知拉到一根統一的線。
關于存儲過程使用,我們和業務方也達成了一致:所有 SQL Server 存儲過程使用業務代碼進行重構,不能在 MySQL 中使用存儲過程。原因是存儲過程增加了業務和 DB 的耦合,會讓維護成本變得極高。另外,MySQL 的存儲過程功能和性能都較弱,無法大規模使用。
***我們提供了一個 MySQL 開發規范文檔,借數據庫遷移的機會,將之前相對混亂的表結構設計做了統一約束(部分有業務綁定的設計,在考慮成本之后沒有做調整)。
ETL 工具
ETL 的全稱是 Extract Translate Load(讀取、轉換、載入),數據庫遷移最核心過程就是 ETL 過程。如果將 ETL 過程簡化,去掉 Translate 過程,就退化為一個簡單的數據導入導出工具。我們可以先看一下市面上常見的導入導出工具,了解他們的原理和特性,方便我們選型。
MySQL 同構數據庫數據遷移工具:
- mysqldump 和 mysqlimport:MySQL 官方提供的 SQL 導入導出工具;
- pt-table-sync:Percona 提供的主從同步工具;
- XtraBackup:Percona 提供的備份工具。
異構數據庫遷移工具:
- Database migration and synchronization tools:國外一家提供數據庫遷移解決方案的公司;
- DataX :阿里巴巴開發的數據庫同步工具;
- yugong :阿里巴巴開發的數據庫遷移工具;
- MySQL Workbench :MySQL 提供的 GUI 管理工具,包含數據庫遷移功能;
- Data Integration - Kettle :國外的一款 GUI ETL 工具;
- Ispirer :提供應用程序、數據庫異構遷移方案的公司;
- DB2DB 數據庫轉換工具 :國產的一款商業數據庫遷移軟件;
- Navicat Premium :經典的數據庫管理工具,帶數據遷移功能;
- DBImport :個人維護的遷移工具,非常簡陋,需要付費。
看上去異構數據庫遷移工具和方案很多,但經過我們調研,其中不少是為老派的傳統行業服務的。比如 Kettle / Ispirerer,他們關注的特性,不能滿足互聯網公司對性能、遷移耗時的要求。簡單篩選后,以下幾款工具進入了我們候選列表(為了做特性對比,加入幾個同構數據庫遷移工具):
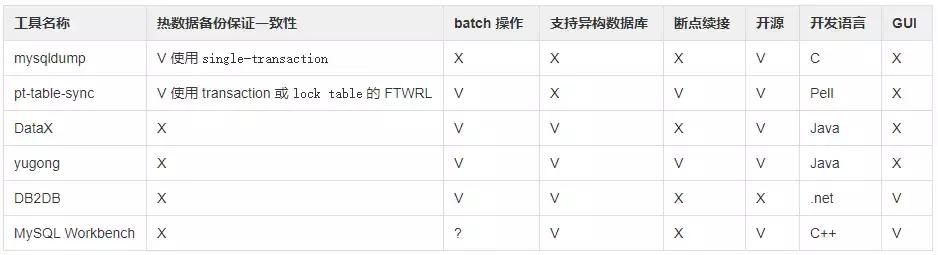
由于異構數據庫遷移,真正能夠進入我們選型的只有 DataX / yugong / DB2DB / MySQL Workbench。經過綜合考慮,我們最終選用了三種方案,DB2DB 提供小數據量、簡單模式的停機模式支持,足以應付小數據量的停機遷移,開發工程師可以自助完成。DataX 為大數據量的停機模式提供服務,使用 JSON 進行配置,通過修改查詢 SQL,可以完成一部分結構調整工程。yugong 的強大可定制性也為在線遷移提供了基礎,我們在官方開源版本的基礎之上,增加了以下額外功能:
- 支持 SQL Server 作為 Source 和 Target;
- 支持 MySQL 作為 Source;
- 支持 SQL Server 增量更新;
- 支持使用 YAML 作為配置格式;
- 調整 yugong 為 fat jar 模式運行;
- 支持表名、字段名大小寫格式變化,駝峰和下劃線自由轉換;
- 支持表名、字段名細粒度自定義;
- 支持復合主鍵遷移;
- 支持遷移過程中完成 Range / Time / Mod / Hash 分表;
- 支持新增、刪除字段。
關于 yugong 的二次開發,我們也積累了一些經驗,下文會詳細分享。
一致性校驗工具
在 ETL 之后,需要有一個流程來確認數據遷移前后是否一致。雖然理論上不會有差異,但是如果中間有程序異常,或者數據庫在遷移過程中發生操作,數據就會不一致。
業界有沒有類似的工具呢?有,Percona 提供了 pt-table-checksum 這樣的工具,這個工具設計從 master 使用 checksum 來和 slave 進行數據對比。這個設計場景是為 MySQL 主從同步設計,顯然無法完成從 SQL Server 到 MySQL 的一致性校驗。盡管如此,它的一些技術設計特性也值得參考:
- 一次檢查一張表;
- 每次檢查表,將表數據拆分為多個 trunk 進行檢查;
- 使用 REPLACE...SELECT 查詢,避免大表查詢的長時間帶來的不一致性;
- 每個 trunk 的查詢預期時間是 0.5s;
- 動態調整 trunk 大小,使用指數級增長控制大小;
- 查詢超時時間 1s / 并發量 25;
- 支持故障后斷點恢復;
- 在數據庫內部維護 src / diff,meta 信息;
- 通過 Master 提供的信息自動連接上 slave;
- 必須 Schema 結構一致。
我們選擇 yugong 作為 ETL 工具的一大原因也是因為它提供了多種模式。支持 CHECK / FULL / INC / AUTO 四種模式。其中 CHECK 模式就是將 yugong 作為數據一致性檢查工具使用。yugong 工作原理是通過 JDBC 根據主鍵范圍變化,將數據取出進行批量對比。
這個模式會遇到一點點小問題,如果數據庫表沒有主鍵,將無法進行順序對比。其實不同數據庫有自己的邏輯主鍵,Oracle 有 rowid,SQL Server 有 physloc。這種方案可以解決無主鍵進行比對的問題。
如何回滾
我們需要考慮一個場景,在數據庫遷移成功之后業務已經運行了幾個小時,但是遇到了一些 Critical 級別的問題,必須回滾到遷移之前狀態。這時候如何保證這段時間內的數據更新到老的數據庫里面去?
最樸素的做法是,在業務層面植入 DAO 層的打點,將 SQL 操作記錄下來到老數據庫進行重放。這種方式雖然直觀,但是要侵入業務系統,直接被我們否決了。其實這種方式是 binlog statement based 模式,理論上我們可以直接從 MySQL 的 binlog 里面獲取數據變更記錄。以 row based 方式重放到 SQL Server。
這時候又涉及到逆向 ETL 過程,因為很可能 Translate 過程中,做了表結構重構。我們的解決方法是,使用 Canal 對 MySQL binlog 進行解析,然后將解析之后的數據作為數據源,將其中的變更重放到 SQL Server。
由于回滾的過程也是 ETL,基于 yugong,我們繼續定制了 SQL Server 的寫入功能,這個模式類似于在線遷移,只不過方向是從 MySQL 到 SQL Server。
其他實踐
我們在遷移之前做了大量壓測工作, 并針對每個遷移的 DB 進行線上環境一致的全真演練。我們構建了和生產環境機器配置一樣、數據量一樣的測試環境,并要求每個系統在上線之前都進行若干次演練。演練之前準備詳盡的操作手冊和事故處理方案。演練準出的標準是:能夠在單次演練中不出任何意外,時間在估計范圍內。通過演練我們保證了整個操作時間可控,減少操作時的風險。
為了讓數據庫的狀態能更為直觀地展現出來,我們對 MySQL / SQL Server 添加了細致的 Metrics 監控。在測試和遷移過程中,可以便利地看到數據庫的響應情況。
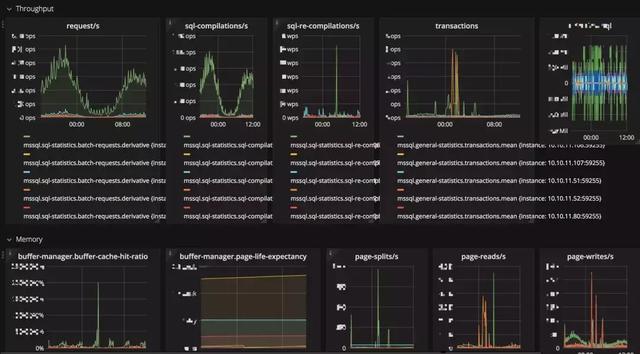
為了方便 DBA 快速 Review SQL。我們提供了一些工具,直接將代碼庫中的 SQL 拎出來,可以方便地進行 SQL Review。再配合其他 SQL Review 工具,比如 Meituan-Dianping / SQLAdvisor,可以實現一部分自動化,提高 DBA 效率,避免線上出現明顯的 Slow SQL。
小結
基于這幾種方案我們打了一套組合拳。經過將近一年的使用,進行了 28 個通宵,遷移了 42 個系統,完成了包括用戶、訂單、支付、電商、學習、社群、內容和工具的遷移。遷移的數據總規模接近百億,所有遷移項目均一次成功。遷移過程中積累了豐富的實戰經驗,保障了業務快速向前發展。
在線遷移的原理和流程
上文介紹了從 SQL Server 到 MySQL 異構數據庫遷移的基本問題和全量解決方案。全量方案可以滿足一部分場景的需求,但是這個方案仍然是有缺陷的:遷移過程中需要停機,停機的時長和數據量相關。對于核心業務來說,停機就意味著損失。比如用戶中心的服務,以它的數據量來使用全量方案,會導致遷移過程中停機若干個小時。而一旦用戶中心停止服務,幾乎所有依賴于這個中央服務的系統都會停擺。
能不能做到無縫地在線遷移呢?系統不需要或者只需要極短暫的停機?作為有追求的技術人,我們一定要想辦法解決這些問題。
針對 Oracle 到 MySQL,市面上已經有比較成熟的解決方案——alibaba 的 yugong 項目。在解決 SQL Server 到 MySQL 在線遷移之前,我們先研究一下 yugong 是如何做到 Oracle 的在線遷移。
下圖是 yugong 針對 Oracle 到 MySQL 的增量遷移流程:

這其中有四個步驟:
- 增量數據收集(創建 Oracle 表的增量物化視圖);
- 進行全量復制;
- 進行增量復制(可并行進行數據校驗);
- 原庫停寫,切到新庫。
Oracle 物化視圖(Materialized View)是 Oracle 提供的一個機制。一個物化視圖就是主庫在某一個時間點上的復制,可以理解為是這個時間點上的 Snapshot。當主庫的數據持續更新時,物化視圖的更新則是要通過獨立的批量更新完成,稱之為 refreshes。一批 refreshes 之間的變化,就可以對應到數據庫的內容變化情況。物化視圖經常用來將主庫的數據復制到從庫,也常常在數據倉庫用來緩存復雜查詢。
物化視圖有多種配置方式,這里比較關心刷新方式和刷新時間。刷新方式有三種:
- Complete Refresh:刪除所有數據記錄重新生成物化視圖;
- Fast Refresh:增量刷新;
- Force Refresh:根據條件判斷使用 Complete Refresh 和 Fast Refres。
刷新機制有兩種模式: Refresh-on-commit 和 Refresh-On-Demand。
Oracle 基于物化視圖,就可以完成增量數據的獲取,從而滿足阿里的數據在線遷移。將這個技術問題泛化一下,想做到在線增量遷移需要有哪些特性?
我們得到如下結論(針對源數據庫):
- 增量變化:支持增量獲得增量數據庫變化;
- 延遲:獲取變化數據這個動作耗時需要盡可能低;
- 冪等一致性:變化數據的消費應當做到冪等,即不管目標數據庫已有數據什么狀態,都可以無差別消費。
回到我們面臨的問題上來,SQL Server 是否有這個機制滿足這三個特性呢?答案是肯定的,SQL Server 官方提供了 CDC 功能。
CDC 的工作原理
什么是 CDC?CDC 全稱 Change Data Capture,設計目的就是用來解決增量數據的。它是 SQL Server 2008 新增的特性,在這之前可以使用 SQL Server 2005 中的 after insert / afterdelete/ after update Trigger 功能來獲得數據變化。
CDC 的工作原理如下:
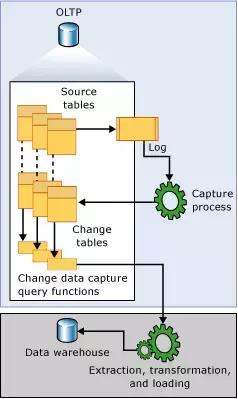
當數據庫表發生變化時候,Capture process 會從 transaction log 里面獲取數據變化,然后將這些數據記錄到 Change Table 里面。有了這些數據,用戶可以通過特定的 cdc 存儲查詢函數將這些變化數據查出來。
CDC 的數據結構和基本使用
CDC 的核心數據就是那些 Change Table 了,這里我們給大家看一下Change Table 長什么樣,可以有個直觀的認識。
通過以下的函數打開一張表(fruits)的 CDC 功能。
-- enable cdc for dbsys.sp_cdc_enable_db;-- enable by tableEXEC sys.sp_cdc_enable_table @source_schema = N'dbo', @source_name = N'fruits', @role_name = NULL;-- list cdc enabled tableSELECT name, is_cdc_enabled from sys.databases where is_cdc_enabled = 1;
左右滑動可完整查看
至此 CDC 功能已經開啟,如果需要查看哪些表開啟了 CDC 功能,可以使用一下 SQL:
-- list cdc enabled tableSELECT name, is_cdc_enabled from sys.databases where is_cdc_enabled = 1;
左右滑動可完整查看
開啟 CDC 會導致產生一張 Change Table 表 cdc.dbo_fruits_CT,這張表的表結構如何呢?
.schema cdc.dbo_fruits_CTname default nullable type length indexed-------------- ------- -------- ------------ ------ -------__$end_lsn null YES binary 10 NO__$operation null NO int 4 NO__$seqval null NO binary 10 NO__$start_lsn null NO binary 10 YES__$update_mask null YES varbinary 128 NOid null YES int 4 NOname null YES varchar(255) 255 NO
左右滑動可完整查看
這張表的 __ 開頭的字段是 CDC 所記錄的元數據, id 和 name 是 fruits 表的原始字段。這意味著 CDC 的表結構和原始表結構是一一對應的。
接下來我們做一些業務操作,讓數據庫的數據發生一些變化,然后查看 CDC 的 Change Table:
--
1 stepDECLARE @begin_time datetime, @end_time datetime, @begin_lsn
binary(10), @end_lsn binary(10);-- 2 stepSET @begin_time = '2017-09-11
14:03:00.000';SET @end_time = '2017-09-11 14:10:00.000';-- 3 stepSELECT
@begin_lsn = sys.fn_cdc_map_time_to_lsn('smallest greater than',
@begin_time);SELECT @end_lsn = sys.fn_cdc_map_time_to_lsn('largest less
than or equal', @end_time);-- 4 stepSELECT * FROM
cdc.fn_cdc_get_all_changes_dbo_fruits(@begin_lsn, @end_lsn, 'all');
左右滑動可完整查看
這里的操作含義是:
- 定義存儲過程中需要使用的 4 個變量;
- begintime / endtime 是 Human Readable 的字符串格式時間;
- beginlsn / endlsn 是通過 CDC 函數轉化過的 Log Sequence Number,代表數據庫變更的唯一操作 ID;
- 根據 beginlsn / endlsn 查詢到 CDC 變化數據。
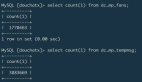
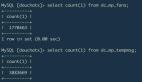
查詢出來的數據如下所示:
__$start_lsn __$end_lsn __$seqval __$operation __$update_mask id name-------------------- ---------- -------------------- ------------ -------------- -- ------0000dede0000019f001a null 0000dede0000019f0018 2 03 1 apple0000dede000001ad0004 null 0000dede000001ad0003 2 03 2 apple20000dede000001ba0003 null 0000dede000001ba0002 3 02 2 apple20000dede000001ba0003 null 0000dede000001ba0002 4 02 2 apple30000dede000001c10003 null 0000dede000001c10002 2 03 3 apple40000dede000001cc0005 null 0000dede000001cc0002 1 03 3 apple4
左右滑動可完整查看
可以看到 Change Table 已經如實的記錄了我們操作內容,注意 __$operation 代表了數據庫操作:
- 1 刪除
- 2 插入
- 3 更新前數據
- 4 更新后數據
根據查出來的數據,我們可以重現這段時間數據庫的操作:
- 新增了 id 為 1 / 2 的兩條數據;
- 更新了 id 為 2 的數據;
- 插入了 id 為 3 的數據;
- 刪除了 id 為 3 的數據。
CDC 調優
有了 CDC 這個利器,意味著我們的方向是沒有問題的,終于稍稍吁了一口氣。但除了了解原理和使用方式,我們還需要深入了解 CDC 的工作機制,對其進行壓測、調優,了解其極限和邊界,否則一旦線上出現不可控的情況,就會對業務帶來巨大損失。
我們先看看 CDC 的工作流程,就可以知道有哪些核心參數可以調整:
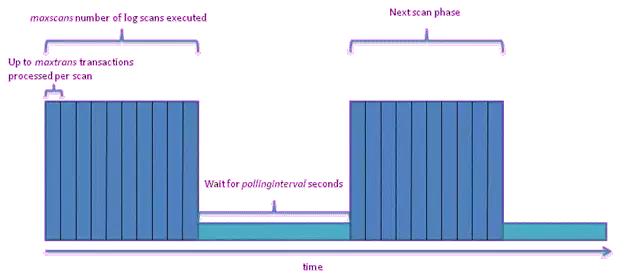
上圖是 CDC Job 的工作流程:
- 藍色區域是一次 Log 掃描執行的***掃描次數:maxscans number(maxscans);
- 藍色區域同時被***掃描 transcation 數量控制:maxtrans;
- 淺藍色區域是掃描間隔時間,單位是秒:pollinginterval。
這三個參數平衡著 CDC 的服務器資源消耗、吞吐量和延遲,根據具體場景,比如大字段,寬表,BLOB 表,可以調整從而達到滿足業務需要。他們的默認值如下:
- maxscan 默認值 10;
- maxtrans 默認值 500;
- pollinginterval 默認值 5 秒。
CDC 壓測
掌握了能夠調整的核心參數,我們即將對 CDC 進行了多種形式的測試。在壓測之前,我們還需要確定關鍵的健康指標,這些指標有:
- 內存:buffer-cache-hit / page-life-expectancy / page-split 等;
- 吞吐:batch-requets / sql-compilations / sql-re-compilations / transactions count;
- 資源消耗:user-connections / processes-blocked / lock-waits / checkpoint-pages;
- 操作系統層面:CPU 利用率、磁盤 IO。
出于篇幅考慮,我們無法將所有測試結果貼出來,這里放一個在并發 30 下面插入一百萬數據(隨機數據)進行展示:
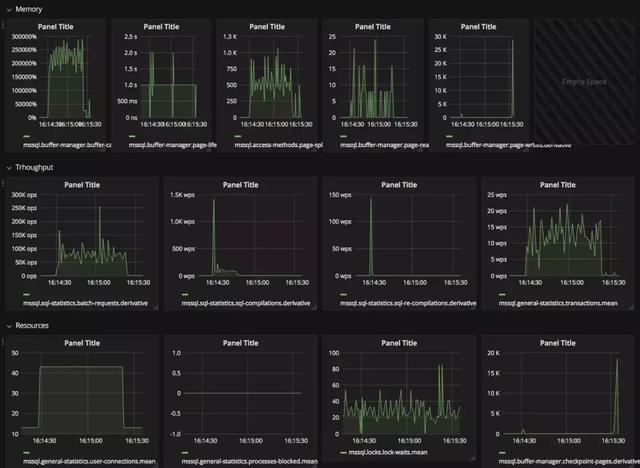
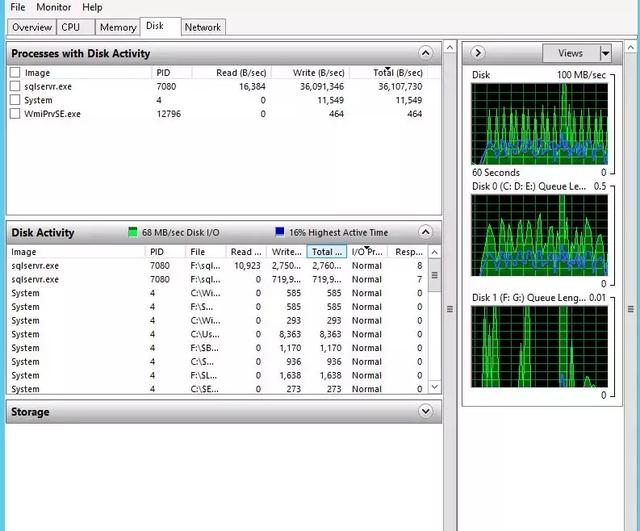
測試結論是,在默認的 CDC 參數下面:
CDC 的開啟/關閉過程中會導致若干個 Process Block,大流量請求下面(15k TPS)過程會導致約 20 個左右 Process Block。這個過程中對服務器的 IO / CPU 無明顯波動,開啟/關閉瞬間會帶來 mssql.sql-statistics.sql-compilations 劇烈波動。CDC 開啟后,在大流量請求下面對 QPS / Page IO 無明顯波動,對服務器的 IO / CPU 也無明顯波動, CDC 開啟后可以在 16k TPS 下正常工作。
如果對性能不達標,官方有一些簡單的優化指南:
- 調整 maxscan maxtrans pollinginterval;
- 減少在插入后立刻插入;
- 避免大批量寫操作;
- 限制需要記錄的字段;
- 盡可能關閉 net changes;
- 沒任務壓力時跑 cleanup;
- 監控 log file 大小和 IO 壓力,確保不會寫爆磁盤;
- 要設置 filegroup_name;
- 開啟 spcdcenable_table 之前設置 filegroup。
yugong 的在線遷移機制
截至目前為止,我們已經具備了 CDC 這個工具,但是這僅僅提供了一種可能性,我們還需要一個工具將 CDC 的數據消費出來,并喂到 MySQL 里面去。
還好有 yugong。Yugong 官方提供了 Oracle 到 MySQL 的封裝,并且抽象了 Source / Target / SQL Tempalte 等接口,我們只要實現相關接口,就可以完成從 SQL Server 消費數據到 MySQL 了。
這里我們不展開,我后續還會專門寫一篇文章講如何在 yugong 上面進行開發。可以提前劇透一下,我們已經將支持 SQL Server 的 yugong 版本開源了。
如何回滾
數據庫遷移這樣的項目,我們不僅僅要保證單向從 SQL Server 到 MySQL 的寫入,同時要從 MySQL 寫入 SQL Server。
這個流程同樣考慮增量寫入的要素:增量消費、延遲、冪等一致性。
MySQL 的 binlog 可以滿足這三個要素,需要注意的是,MySQL binlog 有三種模式,Statement based、Row based 和 Mixed。只有 Row based 才能滿足冪等一致性的要求。
確認理論上可行之后,我們一樣需要一個工具將 binlog 讀取出來,并且將其轉化為SQL Server 可以消費的數據格式,然后寫入 SQL Server。
我們目光轉到 alibaba 的另外一個項目 Canal。Canal 是阿里中間件團隊提供的 binlog 增量訂閱 & 消費組件。之所以叫組件,是由于 Canal 提供了 Canal-Server 應用和 Canal Client Library,Canal 會模擬成一個 MySQL 實例,作為 Slave 連接到 Master 上面,然后實時將 binlog 讀取出來。至于 binlog 讀出之后想怎么使用,權看用戶如何使用。
我們基于 Canal 設計了一個簡單的數據流,在 yugong 中增加了這么幾個功能:
- SQL Server 的寫入功能
- 消費 Canal 數據源的功能
Canal Server 中的 binlog 只能做一次性消費,內部實現是一個 Queue,為了滿足我們可以重復消費數據的能力,我們還額外設計了一個環節,將 Canal 的數據放到 Queue 中,在未來任意時間可以重復消費數據。我們選擇了 Redis 作為這個 Queue,數據流如下:

***實踐
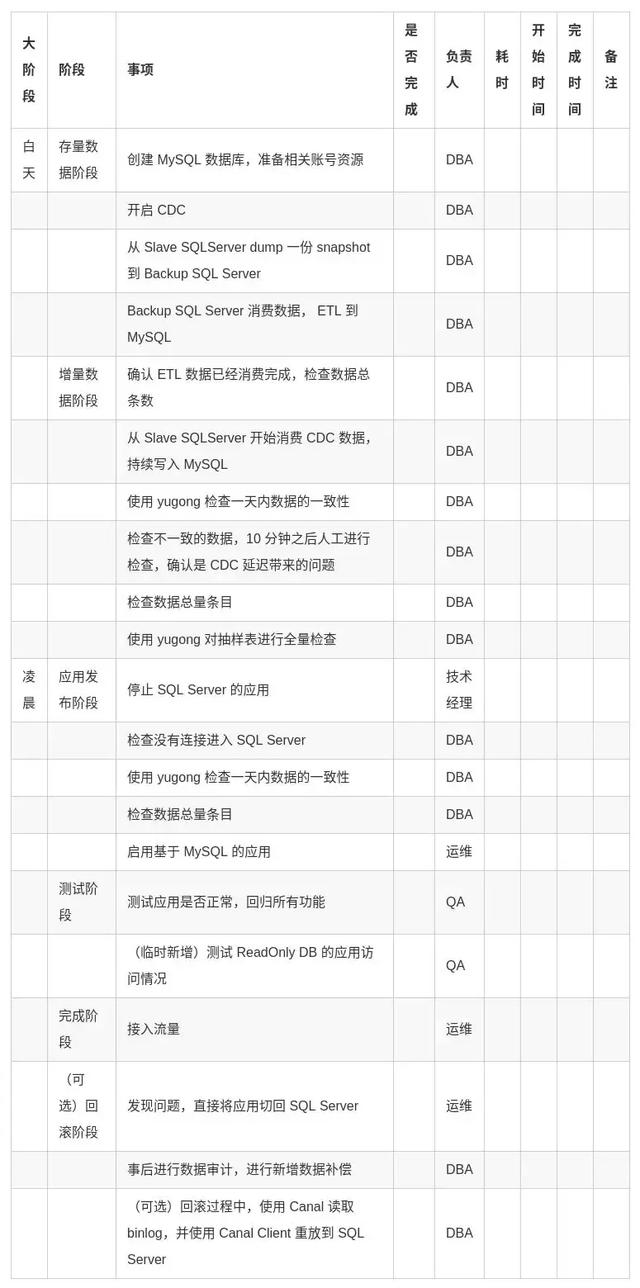
數據庫的遷移在去 Windows 中,是最容不得出錯的環節。應用是無狀態的, 出現問題可以通過回切較快地回滾。但數據庫的遷移就需要考慮周到,做好資源準備,發布流程,故障預案處理。
考慮到多個事業部都需要經歷這樣一個過程,我們項目組將每一個步驟都固化下來,形成了一個***實踐。我們的遷移步驟如下,供大家參考: