一億數據量MySQL,如何實現秒級擴容?
上周有個童鞋問我這個問題,系統性說一下。
一般來說,并發量大,吞吐量大的互聯網分層架構是怎么樣的?
數據庫上層都有一個微服務,服務層記錄“業務庫”與“數據庫實例配置”的映射關系,通過數據庫連接池向數據庫路由sql語句。
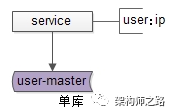
如上圖所示,服務層配置用戶庫user對應的數據庫實例ip。
畫外音:其實是一個內網域名。
該分層架構,如何應對數據庫的高可用?
數據庫高可用,很常見的一種方式,使用雙主同步+keepalived+虛ip的方式進行。
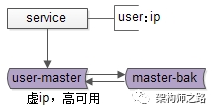
如上圖所示,兩個相互同步的主庫使用相同的虛ip。
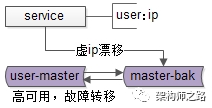
當主庫掛掉的時候,虛ip自動漂移到另一個主庫,整個過程對調用方透明,通過這種方式保證數據庫的高可用。
畫外音:關于高可用,之前介紹過,本文不再展開。
該分層架構,如何應對數據量的暴增?
隨著數據量的增大,數據庫要進行水平切分,分庫后將數據分布到不同的數據庫實例(甚至物理機器)上,以達到降低數據量,增強性能的擴容目的。
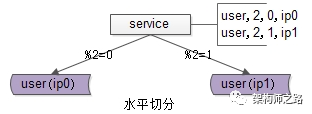
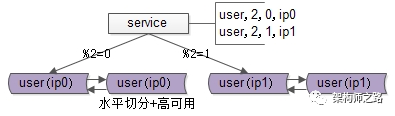
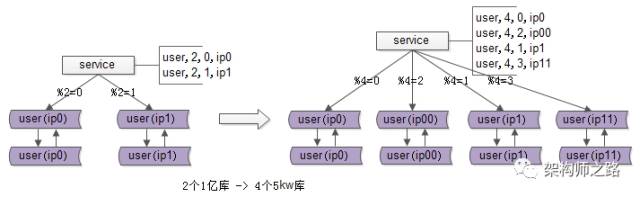
如上圖所示,用戶庫user分布在兩個實例上,ip0和ip1,服務層通過用戶標識uid取模的方式進行尋庫路由,模2余0的訪問ip0上的user庫,模2余1的訪問ip1上的user庫。
畫外音:此時,水平切分集群的讀寫實例加倍,單個實例的數據量減半,性能增長可不止一倍。
綜上三點所述,大數據量,高可用的互聯網微服務分層的架構如下:
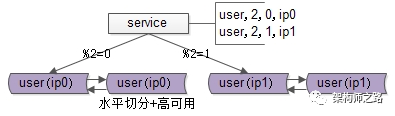
既有水平切分,又保證高可用。
如果數據量持續增大,2個庫性能扛不住了,該怎么辦呢?
此時,需要繼續水平拆分,拆成更多的庫,降低單庫數據量,增加庫主庫實例(機器)數量,提高性能。
新的問題來了,分成n個庫后,隨著數據量的增加,要增加到2*n個庫,數據庫如何擴容,數據能否平滑遷移,能夠持續對外提供服務,保證服務的可用性?
畫外音:你遇到過類似的問題么?
停服擴容,是最容易想到的方案?
在討論秒級平滑擴容方案之前,先簡要說明下停服擴容的方案的步驟:
(1)站點掛一個公告“為了為廣大用戶提供更好的服務,本站點/游戲將在今晚00:00-2:00之間升級,屆時將不能登錄,用戶周知”;
畫外音:見過這樣的公告么,實際上在遷移數據。
(2)微服務停止服務,數據庫不再有流量寫入;
(3)新建2*n個新庫,并做好高可用;
(4)寫一個小腳本進行數據遷移,把數據從n個庫里select出來,insert到2*n個庫里;
(5)修改微服務的數據庫路由配置,模n變為模2*n;
(6)微服務重啟,連接新庫重新對外提供服務;
整個過程中,最耗時的是第四步數據遷移。
如果出現問題,如何進行回滾?
如果數據遷移失敗,或者遷移后測試失敗,則將配置改回舊庫,恢復服務即可。
停服方案有什么優劣?
優點:簡單。
缺點:
(1)需要停止服務,方案不高可用;
(2)技術同學壓力大,所有工作要在規定時間內完成,根據經驗,壓力越大越容易出錯;
畫外音:這一點很致命。
(3)如果有問題第一時間沒檢查出來,啟動了服務,運行一段時間后再發現有問題,則難以回滾,如果回檔會丟失一部分數據;
有沒有秒級實施、更平滑、更帥氣的方案呢?
再次看一眼擴容前的架構,分兩個庫,假設每個庫1億數據量,如何平滑擴容,增加實例數,降低單庫數據量呢?三個簡單步驟搞定。
步驟一:修改配置。

主要修改兩處:
數據庫實例所在的機器做雙虛ip:
- 原%2=0的庫是虛ip0,現增加一個虛ip00;
- 原%2=1的庫是虛ip1,現增加一個虛ip11;
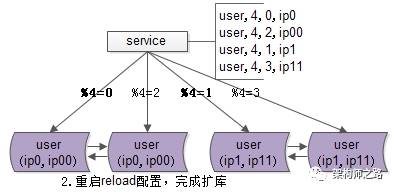
修改服務的配置,將2個庫的數據庫配置,改為4個庫的數據庫配置,修改的時候要注意舊庫與新庫的映射關系:
- %2=0的庫,會變為%4=0與%4=2;
- %2=1的部分,會變為%4=1與%4=3;
畫外音:這樣能夠保證,依然路由到正確的數據。
步驟二:reload配置,實例擴容。
服務層reload配置,reload可能是這么幾種方式:
- 比較原始的,重啟服務,讀新的配置文件;
- 高級一點的,配置中心給服務發信號,重讀配置文件,重新初始化數據庫連接池;
不管哪種方式,reload之后,數據庫的實例擴容就完成了,原來是2個數據庫實例提供服務,現在變為4個數據庫實例提供服務,這個過程一般可以在秒級完成。
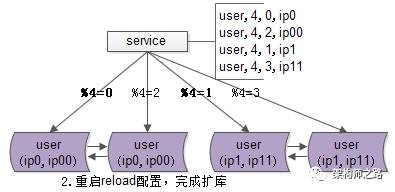
整個過程可以逐步重啟,對服務的正確性和可用性完全沒有影響:
- 即使%2尋庫和%4尋庫同時存在,也不影響數據的正確性,因為此時仍然是雙主數據同步的;
- 即使%4=0與%4=2的尋庫落到同一個數據庫實例上,也不影響數據的正確性,因為此時仍然是雙主數據同步的;
完成了實例的擴展,會發現每個數據庫的數據量依然沒有下降,所以第三個步驟還要做一些收尾工作。
畫外音:這一步,數據庫實例個數加倍了。
步驟三:收尾工作,數據收縮。
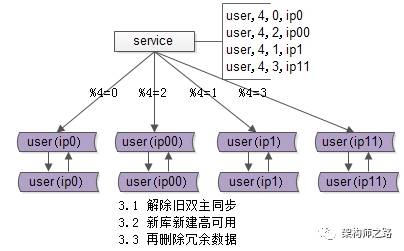
有這些一些收尾工作:
- 把雙虛ip修改回單虛ip;
- 解除舊的雙主同步,讓成對庫的數據不再同步增加;
- 增加新的雙主同步,保證高可用;
- 刪除掉冗余數據,例如:ip0里%4=2的數據全部刪除,只為%4=0的數據提供服務;
畫外音:這一步,數據庫單實例數據量減半了。
總結
互聯網大數據量,高吞吐量,高可用微服務分層架構,數據庫實現秒級平滑擴容的三個步驟為:
- 修改配置(雙虛ip,微服務數據庫路由);
- reload配置,實例增倍完成;
- 刪除冗余數據等收尾工作,數據量減半完成;
思路比結論重要,希望大家有收獲。