Raft和Paxos在分布式存儲系統中的應用差異
本文的目的:
最新在看Group Replication(簡稱GR)的代碼,從Codeship的Galera到MariaDB Galera Cluster/Percona XtrDB Cluster的多主集群技術,再到如今的GR; 分布式存儲系統,尤其是分布式的RDBMS必然是未來的趨勢。其中最本質和最難的一個問題就是一致性問題,一致性問題已經是如今分布式系統必須要面臨的問題。從原子廣播到Viewstamped Replication/Paxos/Raft… 查閱了很多分布式一致性的理論paper和工程技術,把覺得不錯的資料翻譯總結一下。
基本概念:
log: 代表對存儲系統的一次操作記錄,比如一條redolog日志或者binlog
message: 分布式系統中各個Server交互的單元
term: 一個任期的編號,就如美國總統的克林頓、小布什等不同任職區間
index: 在一個term內的序號,通常是連續遞增的
slot: log序列中每一個log entry的全局位點
其實一致性算法的核心思想非常簡單,可以這么簡單(接地氣)地理解:
1. 一群人(集群中的Server)對某個問題吵得不可開交,相持沒有一個統一結論;
2. 過了很久... 大家都累了,意識到需要一位德高望重的領袖(Leader),聽取Leader的意見;
3. 于是不同陣營推舉一位局部可以服眾的侯選人(Leader Candidate);
4. 給候選人5分鐘拉票時間(timeout),然后讓其他人投票(Election),我們姑且認為選舉是公平公正的;
5. 最后選舉出Leader了,雖然還是有些人不服,反正少數服從多數(多數派);
6. 以后的事情,都由Leader來提建議,大多數人同意后就張榜公布,一旦公布的結論就不能更改了(不能干打臉的事情);大家也就沒什么異議了(少數人不服也只有忍~);
7. Leader當久了,難免有點權錢交易啊,這個時候可能被反腐了(Leader不可用); 可生活還得繼續不是,需要重新選舉一位Leader,這就重復前面的歷史了...; 當然也有些Leader不是因為權錢交易掛的,有被和諧的,有被揭竿而起的... 反正就是下課了,總進不了世界杯領導壓力大換個洋教頭也行啊!
8. 哪能啊,上一屆領導的爛賬,腫么辦?一個叫Raft的青年說:“先把屁股擦干凈,否則老子不接這個爛攤子,我要有隊伍的絕對控制權!” 于是Raft正式上任前,就帶一幫人把舊賬本理清楚了,也公示了,然后走馬上任開啟了屬于自己的時代!
9. 當官都是肥差,像年輕的Raft青年這樣NB哄哄,有的時候也沒人鳥他...于是還是有些迫不及待的老油條,先占住Leader的坑,至于前任的爛帳本,上任后的三把火來燒唄!沒錯,這老司機就是Paxos...
10. 貌似這Paxos兄弟江湖口碑一般啊?唉,自古套路留人心,這些老司機有很多法寶,分分鐘教你做人。所以,外面很多門(學)派(術)都在研究Paxos。
1. 背景
一致性是提供容錯服務的關鍵部分,例如分布式強一致存儲系統,非阻塞的原子廣播、Paxos和Raft是三種常見的一致性算法。Paxos被學術界廣泛地研究,Raft則在工程師層面非常受歡迎。
盡管學術界對Paxos情有獨鐘,但Raft卻非常流行。工程師可以通過閱讀幾篇論文就可以理解Raft算法,然后實現Raft算法去解決一些實際的工程問題。算法實現的過程中要考慮通訊交互的次數,消息的數量和資源的占用率等等,綜合權衡這些因素的同時還要保證有較好的系統性能。同時,算法的實現還要考慮算法理論和工程實踐之間經常會遇到的一些問題。
為了克服這些障礙,Diego Ongaro和John Ousterhout發表了一種叫做Raft的新一致性算法,其設計的初衷是更易于理解、以及比Paxos更好的工程化實現等。盡管Raft算法給復雜的分布式系統帶來了耳目一新的感覺,但其中大部分思想和Paxos算法的本質是相同的。例如,都會選擇一個唯一的Leader來負責參與者能否就某個問題達成一致。
在這邊文章中,我們將簡要地介紹Paxos和Raft之間的異同。首先我們會討論什么是一致性算法;然后我們會介紹如何實例化一個一致性算法來構建一個數據復制方案;最后我們介紹Leader是如何選舉的,以及一致性算法的安全性和活性。
請記住,本文的目的不是深入討論Paxos和Raft算法(Paxos算法的某些部分至今未理解透),而僅僅是對兩者的一個概要介紹。如果需要深入了解這兩個算法的細節,請閱讀參考論文1/2/3/4.
2. 分布式一致性
2.1 分布式系統的特征
安全性和活性是分布式系統具有的兩個基本特性,因為安全性和活性是系統正確性的充分必要條件。安全性表示推導過程是正確的,即便有意外情況存在,這種意外也絕對不會發生,最終都會得到一個正確的結果。活性表示最終會得到一個結果,不會因為某種相持而讓系統無法繼續推演至得到結果(在有限的時間內得到一個結果)。從定義上可以這么理解:
安全性
- 只有被提議的值才可能被選定(不會選定一個未被提議的值)
- 只會選定唯一的一個值
- 在一個值真正被選定之前,不會被其它Server學習到
活性
- 最終一定有某些被提議的值被選定
- 一個被選定的值,最終一定會被其它Server學習到
2.2 決議的達成
在一致性算法中,目標是在多個Server之間就某個問題達成一致,活性體現為最終多個Server一定會就某個問題達成一致,不會一直僵持無果;安全性體現為不會有兩個Server包含不同決議。
不幸的是,一個Server可能比其它Server執行得慢、可能Crash、可能停止處理一致性算法邏輯。消息可能延遲,亂序或者丟失。所有的這些因素導致實現一個一致性算法是非常復雜的,也很難保證在穩定的時間內得出正確的決議。雖然我們不能確切地知道一個分布式系統在哪個時刻達到”穩定”狀態,但我們知道最終它一定會達到一個“穩定”狀態。
一次決議達成包含兩次通訊:
- leader –(1)–> servers –(2)–> leader:
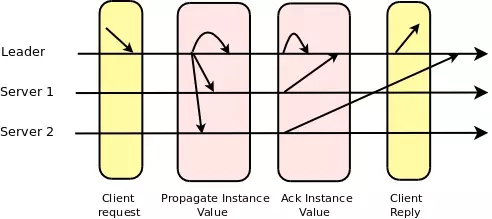
Leader發送一個想要達成一致性的提案給所有參與者,每一個收到這個提案的參與者回復一個ACK給Leader,表示他們已經接受這個提案。在Leader接收到多數派的ACK后,大家對這個提案就達成一致了。
值得注意的是,我們在上面的分析中忽略了兩條消息:第一條是從發起者到Leader之間(發送希望達成一致的意向),第二條是Leader發送給所有的參與者,通知針對某個提案已經達成一致。第二條消息可以通過下面兩種方式避免:
一個Server可以把已經Accept的消息發送給其他所有Server
Leader可以在下一次發送其他提案時附帶已經達成一致的消息編號
2.3 日志復制
為了實現復制,一般會啟動多個一致性算法的實例,每一個實例對應復制日志中的一個log entry,復制日志通常被持久化到磁盤上。Leader可以并行多個一致性算法的實例來針對不同的log entry達成一致,通過這種方式可以提升性能。但是,并行的程度取決于硬件,網絡和應用程序本身。
每一個Leader只對自己所在的任期負責,當Leader發生改變的時候,其對應的任期編號也隨之遞增:

2.4 Leader選舉
無論Paxos算法還是Raft算法,最終都會產生一個Leader,所有其他正常的Server信任Leader來協調一致性的達成,一個任期內只有一個Leader.如果當前任期的Leader不可用,會觸發選舉一個新的Leader,新Leader的任期編號將大于當前任期編號(Term).
在Raft中,一個Server(Leader候選)發送一個“選舉請求”給其他Server,期望在正式成為Leader之前得到多數派Server的響應。如果沒有收到多數派Server的響應或者被告知已經有其他Server成為Leader,當前Server會在timeout后開啟一次新的選舉流程。在一個term內,任何Server只能為一個Leader候選投票。
Paxos沒有明確定義Leader是如何產生的。為了簡單起見,一般都使用基于等級的優先級,比如依據Server的ID(一個整數)。因此,在所有正常的服務器中,總是擁有最高等級或者最低等級的服務器變成Leader. 盡管這是一種簡單直觀的方案,也需要在兩個任期之間劃分間隔:
新任期 = 舊任期 + N(集群中的服務器數目)
Raft對選舉流程加了一些限制:只有最新的Server才能被選舉為Leader。基本上,這種機制保證了Leader擁有所有在上一個任期內達成一致的日志,Leader不需要從全局達成一致的日志中去學習那些它自身沒有的日志。因此當一個Server成為Leader后,它可以立即對外服務,比如向其他Server發起一致性提案。
和Raft不同,Paxos允許任何Server被選舉為Leader. 因此在Paxos中當一個Server成為Leader后,它需要首先向其它Server學習舊任期內已經達成一致的日志,然后才能對外提供服務。可以很明顯地看出,這種靈活性帶來了額外的復雜度。
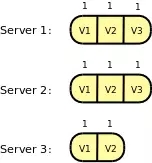
如上圖所示,在Raft中只有Server1和Server2可以被選舉為Leader. 在Paxos中,所有Server都可以被選舉為Leader.
2.5 安全性
源于分布式系統的異步特性,某個Server可能不時地故障并隨時觸發新一輪的選舉。這意味著整個集群中的Server可能在某個時刻臨時處于不同的任期(Term)內,但是他們最終都進入到相同的任期。
任何時候,如果一個Server收到一個來至舊任期內的消息,這意味著發送者要么是Leader,要么是舊任期內試圖成為Leader的一個Server.這種情況下,接收端Server必須拒絕這個消息并通知發送端Server.
如果一個Server接收到一個任期編號大于其當前任期,這意味著已經有一個新Leader產生,接收端必須開始接收新Leader的“提案”.
值得注意的是,兩種算法都需要嚴格地避免覆蓋舊Leader已經達成一致的決議,因為這是明顯不安全的。這是Raft和Paxos的核心差異之一,這一點上我們可以看到Raft算法的相對簡單和直接。
正如前面提到過的一樣,Raft在Leader選舉的時候做出了一些限制,只有擁有最新一致決議的Server才能被選舉為Leader:
Raft對比不同Server中最后一條log記錄的Index和Term來決定是否擁有最新的決議。如果兩條log的Term不相同,則Term較大者勝出。如果兩條log的Term相同,則Index較大者勝出。
Leader只需要保證已經復制的log最終都會被收集到,它通過加入下面的限制來實現這一點:對于一個特定的slot, 當其尚未對index為”n-1”的提案達成一致之前,不會接受index為”n”的提案。
Leader會在當前log中包含上一個log的Term編號,接收端Server只會接收和上一個log匹配的log請求(同一個Term內Index編號連續)。否則,它會要求Leader發送自己尚不存在的log,以此類推“n-2”和“n-3”等等。
在Paxos中,任何一個Server都可能成為Leader,因此避免一個已經達成的決議被覆蓋的任務相對復雜一些。新Leader首先必須找出其它Server都已經處理了哪些決議,然后再開始對外提供服務。
在Paxos算法中,當一個新Leader被選舉出來后,有一個“準備”階段必須執行。“準備”消息包含新的任期編號Term和slot編號“n”,“n”代表前面已經達成一致的決議序號。其他Server回復大于slot編號“n”的信息,這些信息被用于限制新Leader可以對這些slot提議的值。
2.6 活性
只要集群中Server多數派存活,就可以保證集群可以正常服務(選舉和一致性達成流程都可以正常進行)[9].正如前面提到的活性定義,因為Raft和Paxos實際都會有一個Leader來對某一個提案負責,不會出現僵持無果的問題。
3. 結論
通過上面的分析我們了解了Raft和Paxos之間的異同,關鍵的不同之處在于Leader的選舉和安全性的保證。Raft只允許擁有最新數據的Server變成Leader,而Paxos沒有這個限制。這是Paxos的靈活性,當然這個靈活性也帶來了額外的復雜度。
值得注意的是無論在Raft還是在Paxos中,Leade都很容易成為系統的瓶頸,因為所有的請求都會經過Leader。在有Leader的集群中,消息處理的時間復雜度為O(N),而在無Leader的集群中,消息處理的時間復雜度為O(1).
已經有一些基于Paxos的協議支持多個Leader,比如:Mencius;另外還有一些基于Paxos的有序無沖突并行協議,例如:Egalitarian Paxos 和Generalized Paxos. 希望能夠看到基于Raft協議的這種優化!
參考資料:
01 – Paxos made simple
02 – In Search of an Understandable Consensus Algorithm
03 – Desconstructing Paxos
04 – Yet Another Visit to Paxos
05 – Consensus in the presence of partial synchrony
06 – Failure Detection and Consensus in the Crash-Recovery Model
07 – Tuning paxos for high-throughput with batching and pipelining
08 – Introduction to Reliable and Secure Distributed Programming
09 – Lower Bounds for Asynchronous Consensus
10 – Mencius: Building Efficient Replicated State Machines for WANs
11 – There Is More Consensus in Egalitarian Parliaments
12 – Generalized Consensus and Paxos