人工智能技術在電商搜索的落地應用
一直以來都被高度曝光的人工智能領域相關應用,總是引來巨大關注。在電商搜索領域,人工智能發揮著怎樣的作用?Etsy數據科學主管洪亮劼以案例為基,從人工智能技術在電商中的基本應用、電商人工智能技術與傳統領域的異同等方面出發,為大家帶來了一場以“人工智能技術在電商搜索的落地應用”為題的干貨分享。
人工智能在電商的應用
人工智能技術在電商中的基本應用可以分為三個方面,分別是搜索、推薦和廣告,主要目的是為了讓顧客更加便捷的買到自己想要的商品。
電商的***要務在于是否能夠利用自身的搜索、推薦、廣告平臺,讓顧客更加快速有效的購買一件商品。其次,相對于傳統平臺而言電商必須具備這一功能——發現,目的是幫助用戶找到他目前不太想買但仍存在潛在購買性的商品。
假設把電商購物與線下購物體驗進行對比,普通人在進行線下購物時,商家未必會把顧客心儀的產品擺在最外面,那么顧客就存在一定的不購買性且在很短時間內離開購物中心。對購物中心而言,他們更希望顧客能停留盡可能多的時間,且在這段時間內能光顧更多商家;作為用戶而言,雖然絕大多數用戶可能沒有在***時間購買商品,但這并不妨礙這些用戶享受這樣的購物環境。如何將線下的購物場景運用到線上購物中?是目前的電商平臺所需要考慮的一個問題,也是對人工智能應用而言一個相對巨大的挑戰。
電商人工智能技術與傳統領域的異同
就搜索應用而言,電商搜索與普通搜索的***區別在于購買流程的建模及發現流程的建模。普通的搜索模式更希望用戶盡可能在搜索頁面本身停留較短的時間,它更希望用戶只點擊搜索頁面的首頁,而非翻到第二頁第三頁。它將最相關的內容放在首頁的前幾位的目的是為了讓用戶點擊首頁搜索結果后能夠快速離開,將用戶的這一操作過程控制在30秒甚至更短的時間內。
相反,它希望用戶能夠持續反復的進行這一搜索交互操作。電商搜索則與普通搜索有著很大的差別,在傳統搜索中最受重視的相關性并非電商搜索的全部,只是電商搜索的一方面而已。而電商搜索更需要關注總體利潤,能否通過搜索來產生效益。電商搜索的最終目的是提高用戶的購買訴求,其次是激發用戶的潛在購買欲望。因此,電商搜索相對于傳統搜索而言,多了“如何利潤***化”、“如何激發用戶潛在購買欲”等維度。
就推薦應用而言,目前的推薦系統已較為完善,也出現了許多推薦方案。但電商推薦與傳統推薦又有何不同?已有的推薦模型均基于Collaborative Filtering(協同過濾),一般的Collaborative Filtering是通過用戶過去的行為對未來的行為進行預測推薦。以視頻網站為例,假設你在某個視頻網站上瀏覽過某部電影的***季,這一視頻網站便會為你推薦這部電影的第二季、第三季。
但如果在電商場景下,假設用戶已經購買某一產品,而電商推薦系統繼續向你推薦相同產品時,就會暴露出這一系統的不智能性。因此,Collaborative Filtering技術對電商推薦而言是不恰當的,需要根據電商的特殊屬性來對推薦系統做出大的調整。電商的最終目的是為了讓用戶購買商品,通過推薦的方式使用戶購買***化商家的利潤,這需要在過去的推薦系統上增加更多元素。如庫存元素,假設商家把僅有少量庫存甚至庫存唯一的商品推薦給很多用戶,一旦商品售出就會使得其他用戶有較差的使用體驗。如何利用庫存來做到比較好的交互體驗是電商搜索需要關心的一個內容。
就廣告應用而言,電商的廣告系統是雙信息坊系統。對于賣家而言,更希望通過廣告費用使得自己的商品出現在搜索頁面的前幾位。對于平臺而言,通過幫助賣家獲取更多的點擊量來收取一定費用。對于買家而言,即使搜索頁面的前幾位是廣告位,也不會使用戶產生反感,因為買家的最終目的是買到適合自己的產品。
在這一層面,就存在買家、賣家、平臺之間的三方博弈,而這三方很明顯有三個不同的優化目標,因此需要針對這三個不同的目標函數進行優化。賣家希望用最少的錢打到***的效果;買家希望買到***的東西;平臺則希望在這個交易過程中利益***化。如何將三種不同訴求的目標統一在同一建模中,這對于電商廣告系統而言又是一大挑戰。
電商搜索有別于傳統搜索,不管是在搜索、推薦領域還是廣告領域,基本都屬于一個未知的領域,這其中的核心在于兩個任務,一是如何衡量評價所做的事情是否正在優化你的目標;二是如何優化貫穿搜索、推薦及廣告之間的關系。
電商搜索的優化案例
以優化GMV(搜索產生的利潤)為案例作為分享,它將搜索相關性與利潤相掛鉤。何為GMV?
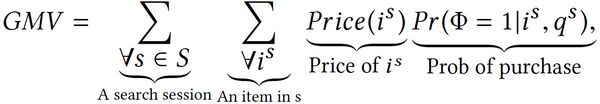
GMV是在搜索過程中所能衡量的期望利潤,針對每一個商品關鍵字,用戶存在一定購買概率。這一概率乘以商品本身的價格,再對所有的商品和所有的搜索繪畫進行加和,得出一個期望利潤,再將這一利潤***化。目標在于估計用戶究竟有多大可能購買一個商品,同時,這些商品也是價格較貴或是能讓商家從中賺取更多利潤的產品。有了這一目標后,重新評估電商搜索領域用戶的決策行為,將這個決策行為進行簡化至兩個步驟,***步是在搜索頁面輸入關鍵字后進行比較,在經過比較后的排序結果里點擊某一結果,針對這個點擊結果進行建模。點擊結果后,頁面跳轉至下一頁面,進入第二個頁面后,用戶可以根據頁面內容、商品價格等進行建模,以確定自己是否需要購買這一商品。
簡單來說,是將整個購買過程簡化成兩個步驟,一是選擇、二是決定;也將如何產生GMV分成兩個步驟,***個步驟是從搜索頁面產生“點擊”的決策動作,二是從產品頁面進行“購買”的決策動作。
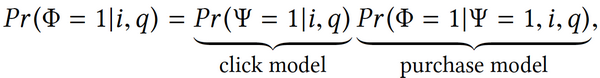
回到GMV公式中的購買概率,將這一概率拆成兩個部分,分別為點擊概率及基于點擊的購買概率。拆分后即可對兩個部分進行單獨建模。首先是點擊建模,點擊建模存在于搜索頁面的基礎之上,當頁面呈現出一個搜索結果后再啟動點擊。這一部分存在可直接借鑒的模型——Learning to Rank(學習排序),兩者***的區別僅在于傳統的Learning to rank是從用戶的相關度來學習,或者是查詢關鍵字的相關度。這里僅需要將相關度在NDCG中從頁面相關程度標簽轉化為點擊標簽。下圖為NDCG的公式。
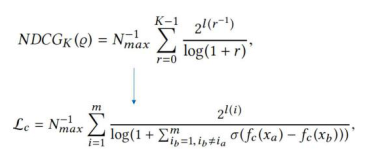
在這一公式中,未知數為Fc,這也是需要建模來表達的未知數(點擊概率)。通過深度網絡對點擊概率進行建模,這也是這一過程中的***個步驟。
第二個步驟為二元決策,也就是當用戶到達某一個產品的頁面時,所做出的“是否購買”的決策行為。運用logistic regression,學習logistic regression中的wp系數。
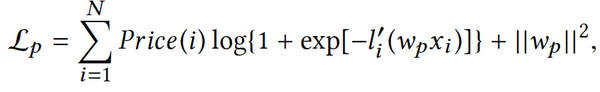
與標準二元決策的差異在于需要對logistic regression重新通過價格進行權重分類。從中可以看出,價格是決定用戶是否購買的重要因素,其中優化目標不再是相關度而是GMV。
從下圖的數據中可以看出,用戶的點擊存在商品位置的偏見。
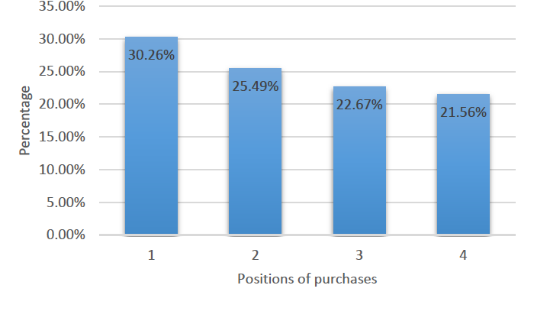
排在前幾位的商品點擊率較高,這也是與傳統搜索相似之處,用戶希望他所預期的產品能夠排在相對靠前的位置,但這一基于位置的遞減點擊速率遠遠低于傳統搜索。
(注:以上內容根據數據俠洪亮劼在數據俠線上實驗室的演講實錄整理。圖片來自其現場PPT,已經本人審閱。本文僅為作者觀點,不代表DT財經立場。)