













6個人如何維護上千規模的大數據集群?
本文主要介紹餓了么大數據團隊如何通過對計算引擎入口的統一,降低用戶接入門檻;如何讓用戶自助分析任務異常及失敗原因,以及如何從集群產生的任務數據本身監控集群計算/存儲資源消耗,監控集群狀況,監控異常任務等。
餓了么 BDI-大數據平臺研發團隊目前共有 20 人左右,主要負責離線&實時 Infra 和平臺工具開發。
其中 6 人的離線團隊需要維護大數據集群規模如下:
- Hadoop 集群規模 1300+
- HDFS 存量數據 40+PB,Read 3.5 PB+/天,Write 500TB+/天
- 14W MR Job/天,10W Spark Job/天,25W Presto/天
此外還需要維護 Hadoop、Spark、Hive、Presto 等餓了么內部版本組件,解決公司 400+ 大數據集群用戶每天面臨的各種問題。
引擎入口統一
目前在餓了么對外提供的查詢引擎主要有 Presto、Hive 和 Spark,其中 Spark 又有 Spark Thrift Server 和 Spark SQL 兩種模式。
并且 Kylin 也在穩步試用中,Druid 也正在調研中。各種計算引擎都有自身的優缺點,適用的計算場景各不相同。
從用戶角度來說,普通用戶對此沒有較強的辨識能力,學習成本會比較高。
并且當用戶可以自主選擇引擎執行任務時,會優先選擇所謂的最快引擎,而這勢必會造成引擎阻塞,或者將完全不適合的任務提交到某引擎,從而降低任務成功率。
從管理角度來說,大數據集群的入口太多,將難以實現統一管理,難以實現負載均衡、權限控制,難以掌控集群整體對外服務能力。
并且當有新的計算需求需要接入,我們還需要為其部署對應的客戶端環境。
用戶使用多種計算引擎
功能模塊
針對這種情況,餓了么大數據團隊開發了 Dispatcher,該組件的主要功能如下圖所示:
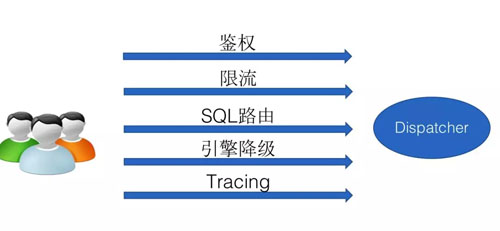
Dispatcher 功能模塊
用戶所有任務全部通過 Dispatcher 提交,在 Dispatcher 中我們可以做到統一的鑒權,統一的任務執行情況跟蹤。
還可以做到執行引擎的自動路由,各執行引擎負載控制,以及通過引擎降級提高任務運行成功率。
邏輯架構
Dispatcher 的邏輯架構如下圖所示:
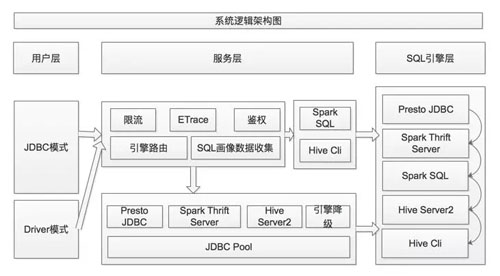
Dispatcher 系統邏輯架構
目前用戶可以通過 JDBC 模式調用 Dispatcher 服務,或者直接以 Driver 模式運行 Dispatcher。
Dispatcher 接收到查詢請求后,將會統一進行鑒權、引擎路由等操作,將查詢提交到對應引擎。
另外,Dispatcher 還有 SQL 轉換模塊,當發生從 Presto 引擎降級到 Spark/Hive 引擎時,將會通過該模塊自動將 Presto SQL 轉換成 HiveQL。
通過 Dispatcher 對查詢入口的統一,帶來的好處如下:
- 用戶接入門檻低,無需再去學習各引擎使用方法和優缺點,無需手動選擇執行引擎。
- 部署成本低,客戶端可通過 JDBC 方式快速接入。
- 統一的鑒權和監控。
- 降級模塊提高任務成功率。
- 各引擎負載均衡。
- 引擎可擴展。
引擎可擴展主要是指當后續接入 Kylin、Druid 或者其他更多查詢引擎時,可以做到用戶無感知。
由于收集到了提交到集群的所有查詢,針對每一個已有查詢計劃,我們可以獲得熱度數據,知道在全部查詢中哪些表被使用次數最多,哪些表經常被關聯查詢,哪些字段經常被聚合查詢等。
當后續接入 Kylin 時,可以通過這些數據快速建立或優化 Cube。
SQL 畫像
在 Dispatcher 中最核心的是 SQL 畫像模塊,基本流程如下圖:
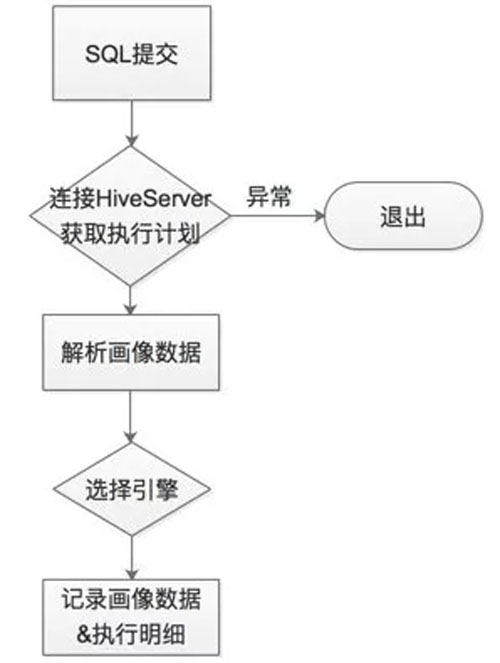
SQL 路由模塊
查詢提交后,通過連接 HiveServer 對查詢計劃進行解析,可以獲取當前查詢的所有元數據信息,比如:
- 讀入數據量
- 讀入表/分區數
- 各類 Join 次數
- 關聯字段多少
- 聚合復雜度
- 過濾條件
- ……
上述元數據信息基本上可以對每一個查詢進行精準的描述,每一個查詢可以通過這些維度的統計信息調度到不同引擎中。
Hive 對 SQL 進行解析并進行邏輯執行計劃優化后,將會得到優化后的 Operator Tree,通過 explain 命令可以查看。
SQL 畫像數據可以從這個結果收集各種不同類型的 Operator 操作,如下圖所示:
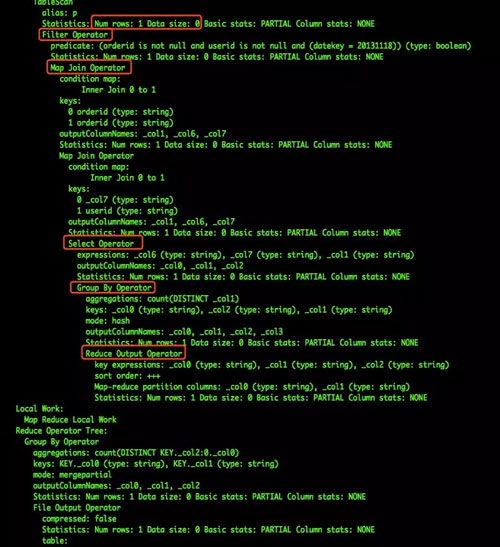
SQL 解析示例
從直觀的理解上我們知道,讀入數據量對于引擎的選擇是很重要的。比如當讀入少量數據時,Presto 執行性能***,讀入大量數據時 Hive 最穩定,而當讀入中等數據量時,可以由 Spark 來執行。
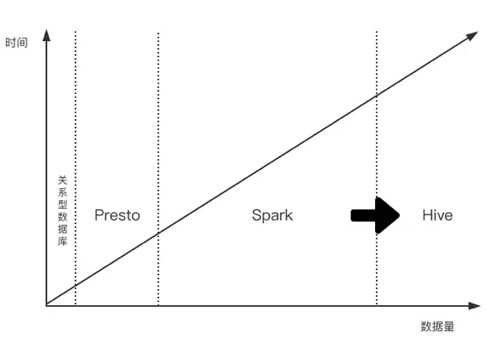
各類計算引擎數據量-執行時間分布
在初始階段,還可以通過讀入數據量,結合 Join 復雜度,聚合復雜度等因素在各種計算引擎上進行測試,采用基于規則的辦法進行路由。
執行過程中記錄好每一次查詢的 SQL 畫像數據,執行引擎,降級鏈路等數據。
基于這些畫像數據,后續可以采用比如決策樹,Logistic 回歸,SVM 等分類算法實現引擎的智能路由,目前餓了么大數據團隊已經開始了這方面的嘗試。
在餓了么的應用中,由 Dispatcher 統一調度的 Ad Hoc 查詢,由于增加了預檢查環節,以及失敗降級環節,每天總體成功率為 99.95% 以上,整體 PT90 值為 300 秒左右。
目前 Presto 承擔了 Ad Hoc 查詢的 50% 流量,SparkServer 模式承擔了 40% 流量。
充分利用集群本身數據
餓了么大數據集群每天運行的 Spark&MR 任務 25W+,這些數據詳細記錄了每一個 Mapper/Reducer 或者 Spark 的 Task 的運行情況,如果能夠充分利用,將會產生巨大的價值。即充分利用集群本身數據,數據驅動集群建設。
這些數據不僅可以有助于集群管理人員監控集群本身的計算資源、存儲資源消耗,任務性能分析,主機運行狀態。還可以幫助用戶自助分析任務運行失敗原因,任務運行性能分析等。
餓了么大數據團隊開發的 Grace 項目就是在這方面的一個示例。
Grace 使用場景
你對集群任務運行狀況詳細數據沒有明確認識的話,很容易當出現問題時陷入困境,從監控看到集群異常后將無法繼續進一步快速定位問題。
當經常有用戶找你說,我的任務為什么跑失敗了?我的任務為什么跑的這么慢?我的任務能調一下優先級么?不要跟我說看日志,我看不懂。我想大家內心都是崩潰的。
當監控發出 NameNode 異常抖動,網絡飚高,block 創建增加,block 創建延時增大等告警時,應該如何快速定位集群運行的異常任務?
當監控發出集群中 Pending 的任務太多時,用戶反饋任務大面積延遲時,如何快速找到問題根本原因?
當用戶申請計算資源時,到底應該給他們分配多少資源?當用戶申請提高任務優先級時如何用數據說話,明確優先級到底應該調到多少?當用戶只管上線不管下線任務時,我們如何定位哪些任務是不再需要的?
還有,如何通過實時展示各 BU 計算資源消耗,指定 BU 中各用戶計算資源消耗,占 BU 資源比例。
以及如何從歷史數據中分析各 BU 任務數,資源使用比例,BU 內部各用戶的資源消耗,各任務的資源消耗等。
以下示例展示一些 Grace 產出數據圖表,有關 BU、用戶、任務級別的數據不方便展示。
監控隊列
從下圖可以方便的看到各隊列***最小資源,當前已用資源,當前運行任務數,Pending 任務數,以及資源使用比例等,還可以看到這些數據的歷史趨勢。
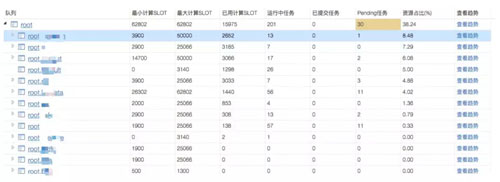
各隊列任務情況
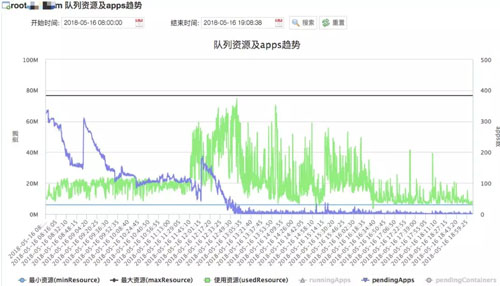
隊列資源使用趨勢
任務監控
可以查看指定隊列中運行中任務的任務類型,開始時間,運行時長,消耗當前隊列資源比例,以及消耗當前 BU 資源比例等。
可快速定位計算資源消耗多并且運行時間長的任務,快速找到隊列阻塞原因。
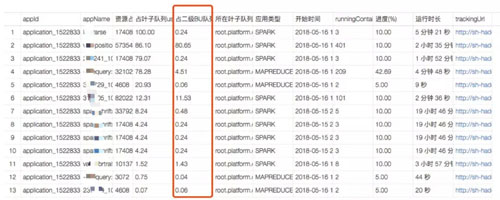
指定隊列任務情況
監控主機失敗率
可以監控集群所有主機上的 Task 執行失敗率。已有監控體系會對主機的 CPU,磁盤,內存,網絡等硬件狀況進行監控。
這些硬件故障最直觀的表現就是分配在這些有問題的主機上的任務執行緩慢或者執行失敗。
運行中的任務是最靈敏的反應,一旦檢測到某主機失敗率過高,可觸發快速自動下線保障業務正常執行。后續可以結合硬件監控定位主機異常原因。
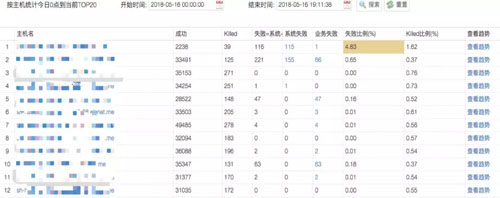
主機失敗率監控
任務性能分析
用戶可自助進行任務性能分析,如下圖:
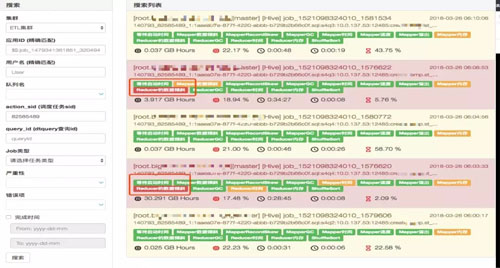
任務性能分析
并且可以根據異常項按照以下建議自助調整,如下圖:
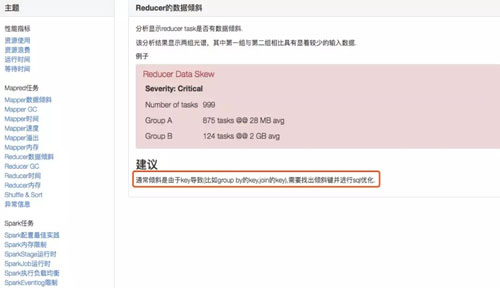
任務自助優化方案
任務失敗原因分析
對于失敗的任務,用戶也可以按照以下方法快速從調度系統查看失敗原因,以及對應的解決辦法,餓了么大數據團隊會定期收集各種典型報錯信息,更新維護自助分析知識庫。
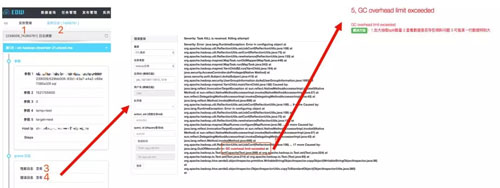
失敗原因自助分析
除此之外,我們還可以實時監控每個任務的計算資源消耗 GB Hours,總的讀入寫出數據量,Shuffle 數據量等,以及運行中任務的 HDFS 讀寫數據量,HDFS 操作數等。
當出現集群計算資源不足時,可快速定位消耗計算資源多的任務。當監控出現 HDFS 集群抖動,讀寫超時等異常狀況時,也可通過這些數據快速定位到異常任務。
基于這些數據還可以根據各隊列任務量,任務運行資源消耗時間段分布,合理優化各隊列資源分配比例。
根據這些任務運行狀況數據建立任務畫像,監控任務資源消耗趨勢,定位任務是否異常。再結合任務產出數據的訪問熱度,還可以反饋給調度系統動態調整任務優先級等。
Grace 架構
上述示例中使用到的數據都是通過 Grace 收集的。Grace 是餓了么大數據團隊開發的應用,主要用于監控分析線上 MR/Spark 任務運行數據,監控運行中隊列及任務明細及匯總數據。
邏輯架構如下圖:
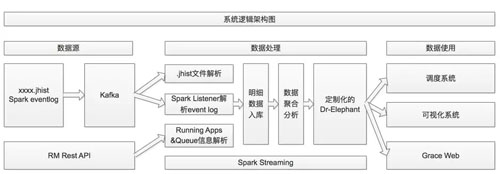
Grace 邏輯架構
Grace 是通過 Spark Streaming 實現的,通過消費 Kafka 中存儲的已完成 MR 任務的 jhist 文件或 Spark 任務的 eventlog 路徑,從 HDFS 對應位置獲取任務運行歷史數據,解析后得到 MR/Spark 任務的明細數據。
再根據這些數據進行一定的聚合分析,得到任務級別,Job 級別,Stage 級別的匯總信息。
***通過定制化的 Dr-Elephant 系統對任務明細數據通過啟發式算法進行分析,從而給用戶一些直觀化的優化提示。
對于 Dr-Elephant,我們也做了定制化的變動,比如將其作為 Grace 體系的一個組件打包依賴。
從單機部署服務的模式變成了分布式實時解析模式。將其數據源切換為 Grace 解析到的任務明細數據。
增加每個任務的 ActionId 跟蹤鏈路信息,優化 Spark 任務解析邏輯,增加新的啟發式算法和新的監控指標等。
總結
隨著大數據生態體系越來越完善,越來越多背景不同的用戶都將加入該生態圈,我們如何降低用戶的進入門檻,方便用戶快速便捷地使用大數據資源,也是需要考慮的問題。
大數據集群中運行的絕大部分任務都是業務相關,但是隨著集群規模越來越大,任務規模越來越大,集群本身產生的數據也是不容忽視的。
這部分數據才是真正反映集群使用詳細情況的,我們需要考慮如何收集使用這部分數據,從數據角度來衡量、觀察我們的集群和任務。
僅僅關注于集群整體部署、性能、穩定等方面是不夠的,如何提高用戶體驗,充分挖掘集群本身數據,用數據促進大數據集群的建設,是本次分享的主題。
作者:陳凱明
簡介:具有多年從事大數據基礎架構工作經驗。目前擔任餓了么數據平臺研發團隊資深數據工程師,主要負責餓了么離線平臺及底層工具開發。


















