













【WOT2018】PingCAP CTO黃東旭:TiDB數據庫的四大應用場景分析
原創【51CTO.com原創稿件】2018年5月18-19日,由51CTO主辦的全球軟件與運維技術峰會在北京召開。此次峰會圍繞人工智能、大數據、物聯網、區塊鏈等12大核心熱點,匯聚海內外60位一線專家,是一場高端的技術盛宴,也是***IT技術人才學習和人脈拓展不容錯過的平臺。
在“大數據處理技術”分會場,PingCAP CTO黃東旭以《How can HTAP help you:A TiDB Story》為主題展開精彩分享。TiDB是一套開源分布式HTAP(Hybrid Transactional/Analytical Processing)數據庫,同時提供MySQL與Spark SQL接口。黃東旭在演講中介紹,TiDB作為一款HTAP數據庫,在高性能的實現 OLTP 特性基礎之上,也同時提供基于實時交易數據的實時業務分析需求,他分享了TiDB的設計思路、現實應用場景,以及TiDB集群在部署和運營方面的***實踐。

PingCAP CTO黃東旭
如今硬件的性價比越來越高,網絡傳輸速度越來越快,數據庫分層的趨勢逐漸顯現,人們已經不再強求用一個解決方案來解決所有的存儲問題,而是通過分層,讓緩存與數據庫負責各自擅長的業務場景。
黃東旭提到,當前數據庫領域面臨各種問題,如在縮放、一致性、大數據分析、與云基礎架構集成等方面均存在諸多問題,現有的數據庫解決方案和大數據分析引擎解決方案基本處于割裂的狀態,由于Oracle、MySQL數據庫并不是面向分布式環境而設計,因此即使勉強通過分庫、分表或中間件的方式,在數據庫層面做了分片,從本質上看也只是復制了相同的堆棧,而非針對分布式系統進行存儲和計算優化,這正是進行跨業務查詢或跨物理機查詢和寫入十分繁瑣的本質原因。NoSQL雖然解決了數據庫彈性擴展的難題,但是卻放棄了數據的強一致性以及對ACID事務的支持,帶來了新的問題。
為了解決這一問題,TiDB在架構上將計算和存儲層進行高度的抽象和分離,對混合負載的場景通過IO優先級隊列,智能副本調度,行列混合存儲等技術使其變為可能。TiDB 作為開源的分布式關系數據庫,其特點是幾乎可以100% 兼容MySQL接口,也兼容 MySQL 的語法和協議,在保證不喪失 ACID 事務的前提下,能夠彈性伸縮,高可用,可以同時處理OLTP和OLAP工作負載,不再需要ETL。
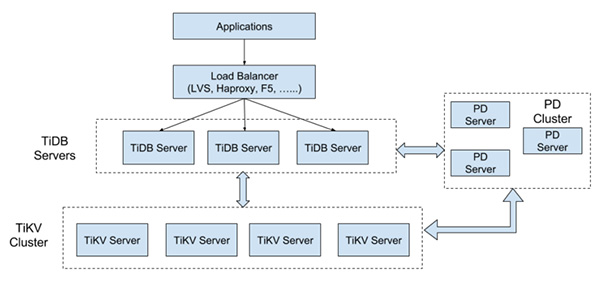
TiDB整體架構圖
TiDB產品的整體架構是高度分層的,由分布式SQL層(TiDB)、分布式KV存儲引擎(TiKV)以及管理整個集群的PD模塊組成。***水平擴展是TiDB的一大特點,這里所說的水平擴展包括兩方面:計算能力和存儲能力。
HTAP給開發者提供了一個實時數據分析方面的新思路,不需要再去維護另一個離線的數據倉庫,既減輕了ETL的工作,又能節省很大一部分建立數據倉庫所用到的存儲和計算成本,HTAP將是未來的重要趨勢。黃東旭介紹了TiDB的四個主要應用場景,一是MySQL分片與合并;二是直接替換MySQL;三是用做數據倉庫;四是作為其他系統的一個模塊。
用例1:MySQL分片與合并
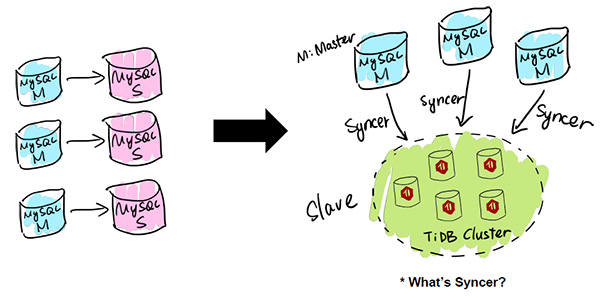

Syncer
TiDB應用的***類場景是MySQL的分片與合并。對于已經在用MySQL的業務,分庫、分表、分片、中間件是常用手段,隨著分片的增多,跨分片查詢是一大難題。TiDB在業務層兼容MySQL的訪問協議,PingCAP做了一個數據同步的工具——Syncer,它可以把TiDB作為一個MySQL Slave,將TiDB作為現有數據庫的從庫接在主MySQL庫的后方,在這一層將數據打通,可以直接進行復雜的跨庫、跨表、跨業務的實時SQL查詢。黃東旭提到,“過去的數據庫都是一主多從,有了TiDB以后,可以反過來做到多主一從。”
用例2:直接替換MySQL
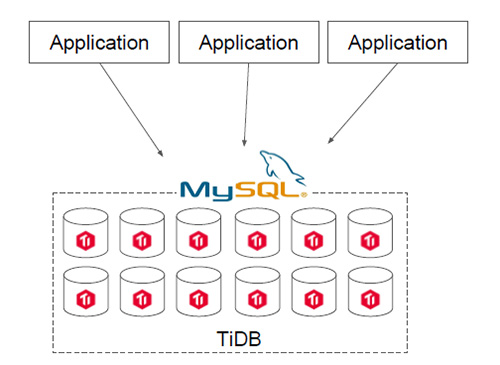
第二類場景是用TiDB直接去替換MySQL。如果你的IT架構在搭建之初并未考慮分庫分表的問題,全部用了MySQL,隨著業務的快速增長,海量高并發的OLTP場景越來越多,如何解決架構上的弊端呢?
在一個TiDB的數據庫上,所有業務場景不需要做分庫分表,所有的分布式工作都由數據庫層完成。TiDB兼容MySQL協議,所以可以直接替換MySQL,而且基本做到了開箱即用,完全不用擔心傳統分庫分表方案帶來繁重的工作負擔和復雜的維護成本,友好的用戶界面讓常規的技術人員可以高效地進行維護和管理。另外,TiDB具有NoSQL類似的擴容能力,在數據量和訪問流量持續增長的情況下能夠通過水平擴容提高系統的業務支撐能力,并且響應延遲穩定。
黃東旭在演講中提到了摩拜單車的案例,摩拜早期的數據庫全部用MySQL,隨著業務的快速增長,MySQL的弊端逐漸顯現,摩拜單車于2017年初開始使用TiDB替換MySQL。如今,摩拜的IT系統中已部署了數套TiDB集群,近百個節點,承載著數十TB 的各類數據。
用例3:數據倉庫
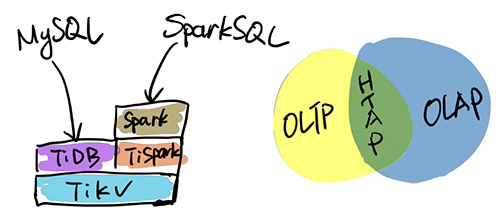
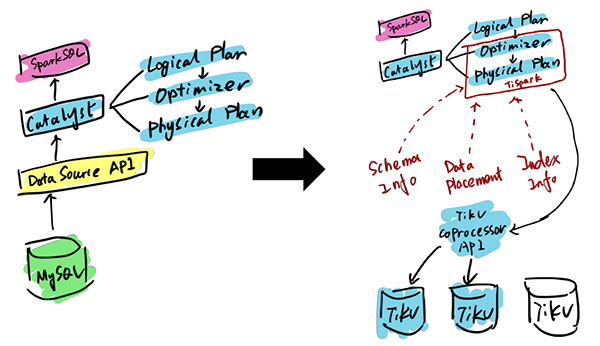
TiDB本身是一個分布式系統,第三種使用場景是將TiDB當作數據倉庫使用。TPC-H是數據分析領域的一個測試集,TiDB 2.0在OLAP場景下的性能有了大幅提升,原來只能在數據倉庫里面跑的一些復雜的Query,在TiDB 2.0里面跑,時間基本都能控制在10秒以內。當然,因為OLAP的范疇非常大,TiDB的SQL也有搞不定的情況,為此PingCAP 開源了 TiSpark,TiSpark是一個Spark插件,用戶可以直接用Spark SQL實時地在TiKV上做大數據分析。
用例4:作為其他系統的模塊
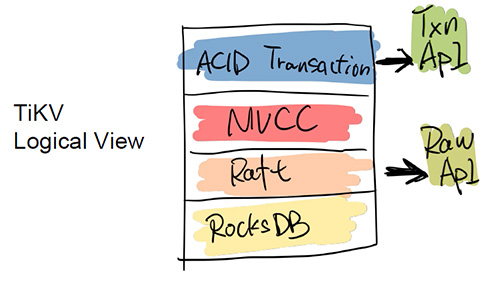
TiDB是一個傳統的存儲跟計算分離的項目,其底層的Key-Value層,可以單獨作為一個HBase的Replacement來用,它同時支持跨行事務。TiDB對外提供兩個API接口,一個是ACID Transaction的API,用于支持跨行事務;另一個是Raw API,它可以做單行的事務,換來的是整個性能的提升,但不提供跨行事務的ACID支持。用戶可以根據自身的需求在兩個API之間自行選擇。例如有一些用戶直接在 TiKV 之上實現了 Redis 協議,將 TiKV 替換一些大容量,對延遲要求不高的 Redis 場景。
尚待解決的問題
***,黃東旭提到了數據庫領域尚待解決的三大問題:
1、 多租戶:例如,整個集群云化之后,IO隔離還存在很大的問題,數據層如何做到更有效的資源隔離和復用是一個問題。
2、真正的自治:數據庫能否擁有真正的智能,如能夠自我維護,自我修復以及自我性能調優等。
3、如何利用新的硬件:如何利用Nvme SSD、Persistent Memory、GPU、FPGA等,軟硬結合的利用新時代的硬件提升數據庫的穩定性。
以上內容是51CTO記者根據PingCAP CTO黃東旭在WOT2018全球軟件與運維技術峰會的演講內容整理,更多關于WOT的內容請關注51cto.com。
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】





















