













【W(wǎng)OT2018】四位重磅大咖解析NLP在企業(yè)業(yè)務(wù)中的深度應(yīng)用
原創(chuàng)【51CTO.com原創(chuàng)稿件】2018年11月30日-12月1日,WOT2018全球人工智能技術(shù)峰會在北京•粵財JW萬豪酒店盛大召開。60+國內(nèi)外人工智能一線精英大咖與千余名業(yè)界人士齊聚現(xiàn)場,分享人工智能的平臺工具、算法模型、語音視覺等技術(shù)內(nèi)容,探討人工智能如何賦予行業(yè)新的活力。兩天會議涵蓋通用技術(shù)、應(yīng)用領(lǐng)域、行業(yè)賦能三大章節(jié),開設(shè)13大技術(shù)專場,如機器學習、數(shù)據(jù)處理、AI平臺與工具、推薦搜索、業(yè)務(wù)實踐、優(yōu)化硬件等,堪稱人工智能技術(shù)盛會。

在《文本分析與NLP》分論壇,宜信技術(shù)研發(fā)中心數(shù)據(jù)科學家井玉欣、新浪微博研發(fā)中心機器學習研發(fā)部NLP負責人胥望軍、貝殼找房資深算法專家陳開江和知乎AI團隊技術(shù)負責人黃波,四位專家圍繞文本分析與自然語言處理技術(shù),就人機對話、問答系統(tǒng)等在企業(yè)中的應(yīng)用展開論述。

NLP技術(shù)在宜信業(yè)務(wù)中的技術(shù)實踐
自然語言數(shù)據(jù)作為重要的溝通形式以及信息載體,廣泛存在于企業(yè)日常業(yè)務(wù)的各個環(huán)節(jié)之中,合理的NLP技術(shù)可以克服自然語言非形式化、不確定性等問題,發(fā)掘并捕獲其中蘊含的有價值信息,進而用于業(yè)務(wù)咨詢、決策支持、精準營銷等方面,是企業(yè)重要的AI能力之一。
宜信技術(shù)研發(fā)中心數(shù)據(jù)科學家井玉欣在《NLP技術(shù)在宜信業(yè)務(wù)中的技術(shù)實踐》的演講中,圍繞基于機器學習的NLP技術(shù)在宜信內(nèi)部各業(yè)務(wù)領(lǐng)域的應(yīng)用實踐展開,分享了相關(guān)的實踐經(jīng)驗,包括智能機器人在業(yè)務(wù)支持、客戶服務(wù)中的探索,基于文本語義分析的用戶畫像構(gòu)建,以及NLP算法服務(wù)平臺化實施思路等。
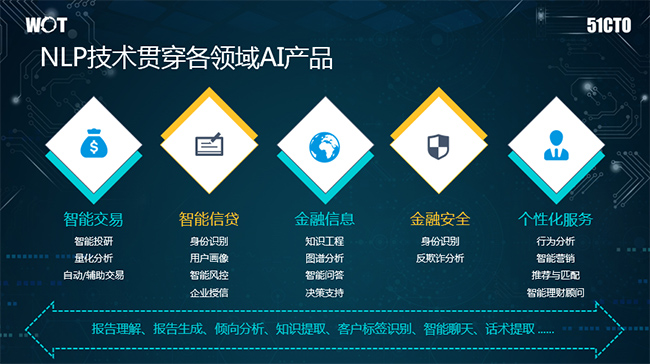
宜信于2006年在北京成立,是一家從事普惠金融以及財富管理的金融科技企業(yè),目前AI技術(shù)已廣泛應(yīng)用于宜信的各大產(chǎn)品線,這些AI產(chǎn)品背后都有自然語言處理技術(shù)的縮影。例如,在智能交易中有很多投研方面的報告,需要報告理解方面的NLP技術(shù)。
自然語言數(shù)據(jù)存在數(shù)據(jù)非結(jié)構(gòu)化、語言歧義性、語法不規(guī)則、未知語言現(xiàn)象四大缺陷,但也有數(shù)據(jù)量豐富、信息表述多樣性、信息完整性、符合用戶習慣四大優(yōu)點。結(jié)合宜信自身的金融數(shù)據(jù)也有四大特點:詞匯專業(yè)性強、數(shù)據(jù)來源廣泛、數(shù)據(jù)形式多樣、數(shù)據(jù)量大但不均衡。

宜信技術(shù)研發(fā)中心數(shù)據(jù)科學家井玉欣
由于結(jié)構(gòu)化數(shù)據(jù)可被挖掘的潛力有限,企業(yè)業(yè)務(wù)越來越關(guān)注那些大量的非結(jié)構(gòu)化數(shù)據(jù)蘊含的高價值信息,如客戶信息、產(chǎn)品數(shù)據(jù)、輿論傾向和策略反饋等。此外,自然語言理解和自然語言生成給人們帶來了一種新的會話交互方式,且更加自然、高效,更吸引人,也更符合用戶的習慣,這也是NLP技術(shù)被廣泛應(yīng)用于各個領(lǐng)域的重要原因。自然語言的特點決定了NLP技術(shù)的必要性,NLP承擔了各業(yè)務(wù)領(lǐng)域內(nèi)自然語言數(shù)據(jù)的分類、提取、轉(zhuǎn)換、生成任務(wù),是業(yè)務(wù)領(lǐng)域內(nèi)重要、基礎(chǔ)的技術(shù)服務(wù)之一。

現(xiàn)代企業(yè)對智能聊天機器人有著非常廣泛的業(yè)務(wù)需求。以信貸業(yè)務(wù)咨詢機器人為例,業(yè)務(wù)的核心是基于檢索的問答模型,核心問題是文本語義的相似度問題,涉及語義相似度函數(shù)和文本表征函數(shù)。對于用戶的問題,要在數(shù)據(jù)庫中找出最相似的答案反饋給用戶,可以通過構(gòu)建Dual LSTM神經(jīng)網(wǎng)絡(luò)或是拆分成子問題這兩種方法來解決。隨后,井玉欣介紹了DSSM模型與遷移學習,QA匹配模型、基于NN的匹配模型、知識庫檢索,模糊 Query 造成的精度下降的解決辦法,以及基于文本語義分析的用戶畫像構(gòu)建思路等。
自然語言處理在新浪微博中的應(yīng)用
微博作為國內(nèi)超大的社交媒體平臺,用戶每天更新的微博內(nèi)容達上億條。由于微博內(nèi)容的文本短且表達形式豐富,為內(nèi)容理解帶來了較大難度。新浪微博研發(fā)中心機器學習研發(fā)部NLP負責人胥望軍在主題為《自然語言處理(NLP)在微博中的應(yīng)用》的分享中,介紹了微博內(nèi)容理解的場景、難點、解決思路和算法,以及在微博興趣推薦場景下的應(yīng)用。
微博的推薦場景包括內(nèi)容推薦和用戶推薦兩大類,有基于關(guān)注關(guān)系推薦內(nèi)容的關(guān)注流、基于興趣推薦內(nèi)容的熱門流、按頻道領(lǐng)域推薦內(nèi)容的頻道流,以及基于用戶興趣和關(guān)注關(guān)系的個性化推送等等。微博的內(nèi)容推薦框架由物料庫、召回(常規(guī)/實時)、粗排序、精排序、業(yè)務(wù)策略及展示、行為收集,以及離線訓練模型、常規(guī)模型和實時模型等構(gòu)成。

新浪微博研發(fā)中心機器學習研發(fā)部NLP負責人胥望軍
微博構(gòu)建了全領(lǐng)域的知識圖譜和標簽體系,其中一級標簽覆蓋五十余個領(lǐng)域,二級標簽一千余個,三級標簽高達一千余萬個,標簽體系的建立在推薦場景中發(fā)揮著重要作用。微博內(nèi)容通過標簽分類解決內(nèi)容的可解釋性,通過主題模型解決內(nèi)容的匹配問題。此外,新浪微博基于內(nèi)容理解構(gòu)建了用戶畫像,包括用戶的興趣偏好,性別、年齡等自然屬性,以及職業(yè)、公司、學歷等社會屬性。
隨后,胥望軍主要介紹了BERT(Bidirectional Encoder Representations from Transformers)和多模態(tài)融合兩種算法,BERT用于結(jié)合語義本身的信息,表達時間維度;多模態(tài)融合用于結(jié)合微博富媒體內(nèi)容信息進行分類,表達空間維度。此外,新浪微博在短文本分類方面也進行了較多嘗試,從最初的樸素貝葉斯到深度模型,不斷進行對比、更新,進行模型演進。
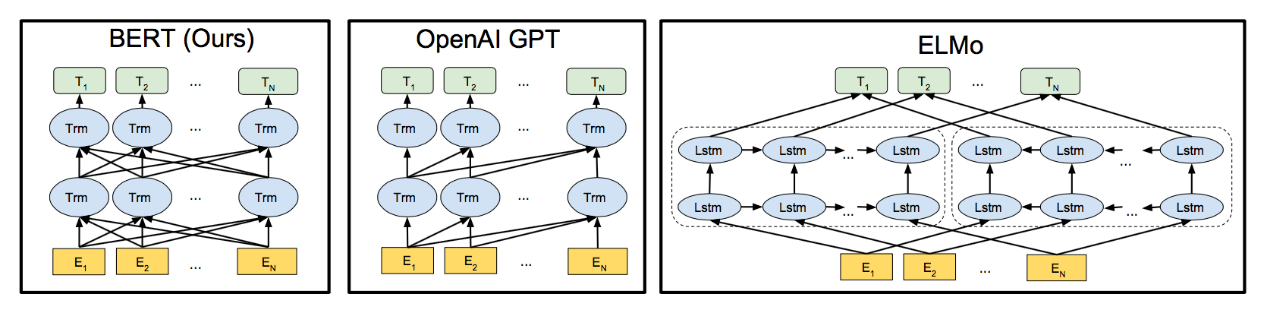
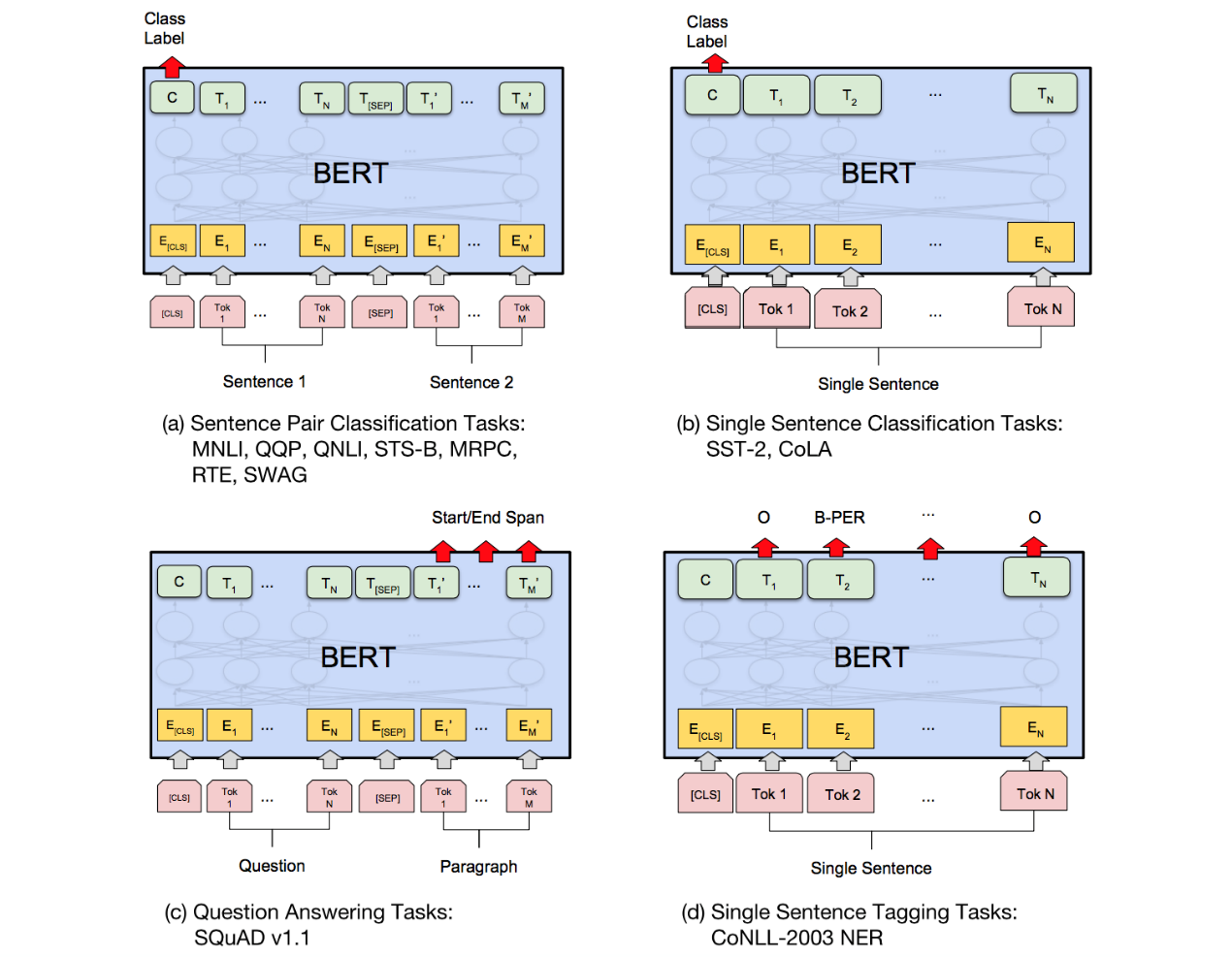
BERT模型幾乎能應(yīng)用于所有的NLP任務(wù)。BERT預(yù)訓練最關(guān)鍵的兩點:一是特征抽取器采用Transformer;第二點是預(yù)訓練時采用雙向語言模型。Transformer特征提取器的效果高,能進行分布式處理,采用self attention機制能夠捕獲遠距離特征信息。
微博具有豐富的表達方式,如文字、圖片、視頻、語音,甚至是用戶互動等,都是用來理解內(nèi)容的各種模態(tài)。因此,除了在純文本方面嘗試前沿的算法,新浪微博也在內(nèi)容的多模態(tài)方面進行嘗試,例如文本和圖片的雙端attention融合方式等。
對話系統(tǒng)在房產(chǎn)行業(yè)的應(yīng)用
對話系統(tǒng)是NLP領(lǐng)域常見的技術(shù)方向,也是未完全解決的技術(shù)難點。近年來,深度學習的興盛把對話系統(tǒng)帶到了一個新高度。貝殼找房作為行業(yè)超大規(guī)模的居住服務(wù)平臺,一直在對話系統(tǒng)方面進行長期的探索嘗試。常規(guī)的對話系統(tǒng)試圖取代傳統(tǒng)的人工服務(wù),而貝殼找房的對話系統(tǒng)有自己的創(chuàng)新,人工智能和人工知識可以共同學習演化,借助深度學習和傳統(tǒng)NLP技術(shù)為行業(yè)賦能。貝殼找房資深算法專家陳開江分享了貝殼找房在語義理解、對話系統(tǒng)、語音助手和VR看房協(xié)同工作方面的相關(guān)技術(shù)和產(chǎn)品實踐。

貝殼找房資深算法專家陳開江
對話系統(tǒng)的難點包含五個方面:一是很難用單一模型解決問題;二是很難獲得高質(zhì)量、低成本的大量標注數(shù)據(jù);三是很多人人皆知的常識需要機器去理解;四是對話系統(tǒng)的溝通很難進行量化、標準的評測;五是對話系統(tǒng)很難通用,一個行業(yè)、一個場景做到很好的效果,也很難復(fù)制到其他行業(yè)或場景中直接使用。
貝殼找房作為居住服務(wù)平臺,在對話系統(tǒng)上有著長期的探索嘗試。貝殼找房利用深度學習和傳統(tǒng)NLP技術(shù),為眾多經(jīng)紀人賦能,使其作業(yè)效率提升3到5倍。房產(chǎn)行業(yè)都是高額消費,如果直接人機對話很難建立信任,因此貝殼找房通過用戶端的貝殼APP與經(jīng)紀人端的Link APP進行直接對話,對話系統(tǒng)在對話過程中是一個潛在角色,系統(tǒng)將對話發(fā)送給經(jīng)紀人,經(jīng)紀人可以對文本進行修飾,也可直接發(fā)送給用戶。
貝殼找房的對話系統(tǒng)在技術(shù)上分為三個階段:一階段不斷獲取對話數(shù)據(jù),第二階段是MVP(Model-View-Presenter ),第三階段是反復(fù)迭代。從對話數(shù)據(jù)中得到初級知識,首先進行數(shù)據(jù)的預(yù)處理,抽取出Q&A問答的對話體系,對話體系包括流程、意圖和槽位(類似函數(shù)的參數(shù))三大要素。隨后,陳開江重點介紹了單意圖單輪會話和多意圖多輪對話的主要流程、算法和實驗結(jié)果等。他透露,目前貝殼找房正在將一些科技元素融入房產(chǎn)行業(yè),例如通過4D看房,提升了經(jīng)紀人和用戶的看房效率,通過AI平臺將貝殼的能力開放給內(nèi)部,服務(wù)更多場景,通過行業(yè)數(shù)倉加房產(chǎn)知識圖譜的建設(shè)形成行業(yè)全景圖,助力4D看房及AI平臺的建設(shè)。
知乎:應(yīng)用AI打造智能社區(qū)
作為國內(nèi)知名知識分享平臺,知乎已擁有 2 億注冊用戶,回答數(shù)超過 1 億,目前 AI 已經(jīng)全面參與知乎的各個環(huán)節(jié),大幅提升了社區(qū)的運營效率。知乎AI團隊技術(shù)負責人黃波帶來了《知乎AI技術(shù)及應(yīng)用》的精彩演講,分享了知乎在知識圖譜、內(nèi)容理解、用戶分析方面的具體技術(shù)及相關(guān)應(yīng)用。
知識圖譜分兩步;一是知識圖譜的構(gòu)建,包括將結(jié)構(gòu)化與半結(jié)構(gòu)的知識融合,通過數(shù)據(jù)挖掘知識之間的關(guān)系,進行知識表示與建模;第二步是知識圖譜的應(yīng)用,包括語義搜索和推薦,問答和對話系統(tǒng),大數(shù)據(jù)分析與決策三部分。

知乎AI團隊技術(shù)負責人黃波
知識圖譜的構(gòu)建與具體業(yè)務(wù)場景強相關(guān),目前,知乎構(gòu)建了以話題、實體為核心的百萬級節(jié)點,構(gòu)建了話題相關(guān)性圖譜、話題上下位圖譜、話題與實體的關(guān)系圖譜等。從長遠來看,知乎會將用戶作為知識圖譜的一個節(jié)點,和話題、實體等語義節(jié)點建立連接關(guān)系。
知識圖譜的知識表示分為離散表示和連續(xù)表示兩種。離散表示的優(yōu)點是可解釋性強,表示能力強,能處理復(fù)雜知識結(jié)構(gòu),缺點是稀疏、擴展性差;連續(xù)表示的優(yōu)點是低維稠密、模型友好,缺點是可解釋性差,表示能力弱,復(fù)雜知識結(jié)構(gòu)支持較差。因此,在選擇知識表示方法時需要根據(jù)各自優(yōu)缺點進行慎重選擇。
目前,知乎內(nèi)容平臺有25 萬個話題,2700 萬個問題,1.2 億個回答。知乎內(nèi)容分析包括語義標簽、質(zhì)量標簽和時效標簽三類。
多種粒度語義標簽要求:
- 一二級領(lǐng)域:粒度粗,盡量完備正交的分類體系,保證任一問題或文章能分到某個類別;
- 話題:高準確度,同一個問題或文章可打上多個話題;
- 實體/關(guān)鍵詞:高準確度,優(yōu)先保證熱門實體/關(guān)鍵詞被召回;
- 語義聚類:語義類簇粒度均,源于數(shù)據(jù)。
話題匹配方面,由于端到端深度學習模型的效果較差,因此知乎采用基于召回+排序的多策略融合,準確率高達93%,召回率達83%。其中,召回策略包括AC多模匹配、基于點互信息(PMI)兩趟對齊算法和基于知識圖譜三種召回方式。多策略融合排序模型,分別為基于深度學習模型的語義相似度得分,與候選話題集合的相似度得分,基于話題圖譜的權(quán)重得分,和基于規(guī)則的權(quán)重得分四種。
在用戶分析方面,分為用戶基礎(chǔ)畫像,用戶興趣畫像,和用戶社交表示與挖掘三類。其中,用戶表示與聚類使用用戶搜索內(nèi)容、關(guān)注、收藏、點贊、閱讀的回答、文章等對應(yīng)的話題,作為用戶的特征,整理成 one-hot 的向量;使用變分自編碼器(Variational Auto-Encoder,VAE) 重建用戶話題向量,將 encoder 層輸出映射為概率分布,并作為用戶的 Embedding 表示。
以上內(nèi)容是51CTO記者根據(jù)WOT2018全球人工智能技術(shù)峰會的《文本分析與NLP》分論壇演講內(nèi)容整理,更多關(guān)于WOT的內(nèi)容請關(guān)注51cto.com。

【51CTO原創(chuàng)稿件,合作站點轉(zhuǎn)載請注明原文作者和出處為51CTO.com】



























