人工智能馬賽克去除深度CNN降噪器和多層相鄰分量嵌入馬賽克去除
人工智能馬賽克去除深度CNN降噪器和多層相鄰分量嵌入馬賽克去除摘要:目前大多數面部去馬賽克方法,無論是淺層學習還是深度學習,都試圖在列車的幫助下學習低分辨率(LR)和高分辨率(HR)空間之間的關系模型 - 集合。他們主要關注通過基于模型的優化或區分推理學習來建模圖像優先。但是,當輸入的LR面很小時,學到的先驗知識不再有效,其性能會急劇下降。為了解決這個問題,本文提出了一種通用的面部幻覺方法,可以將基于模型的優化和區分性推理相結合。特別地,為了利用基于模型的先驗,借助于圖像自適應拉普拉斯正則化將深度卷積神經網絡(CNN)降噪器先前插入到超分辨率優化模型中。此外,我們進一步開發了一種高頻細節補償方法,將人臉圖像分散到人臉部位,并以多層相鄰嵌入方式執行面部幻覺。實驗證明,所提出的方法可以為微小輸入LR面獲得有前途的超分辨率結果。

人工智能馬賽克去除深度CNN降噪器和多層相鄰分量嵌入馬賽克去除簡介:為了克服基于模型的優化方法和判別推理學習方法的缺點,同時利用它們各自的優點,最近,已經提出了一些方法來分別處理保真度項和正則化項,借助于可變分裂技術,例如作為ADMM優化或去噪正則化(RED)[Romano等人,2017]。基于模型的超分辨率方法試圖迭代地重建HR圖像,使得其降級的LR圖像與輸入的LR圖像相匹配,而推理學習試圖通過機器學習來訓練降噪器,使用LR和HR圖像對。因此,復雜的超分辨率重建問題被分解成一系列圖像去噪任務,再加上容易處理的二次規范正則化最小二乘優化問題。
在許多真實的監控場景中,攝像機通常遠離感興趣的物體,系統的帶寬和存儲資源有限,這通常會導致非常小的人臉圖像,即微小的臉部。雖然上述方法是通用的,可以用來處理各種圖像劣化過程,但是當采樣因子非常大時,這種方法的性能會變差,即輸入LR人臉圖像非常小。學習的降噪器先前不能充分利用人臉的結構,因此幻覺的HR面仍然缺乏詳細的特征,如圖1的第二列所示。通常,深度卷積神經網絡(CNN)降噪器先驗基于面部幻覺的方法可以很好地生成主要面部結構,但無法回復很多高頻內容。為了處理非常小的輸入圖像的瓶頸,已經提出了一些基于深度神經網絡的方法[Yu和Porikli,2016; Yu和Porikli,2017]。
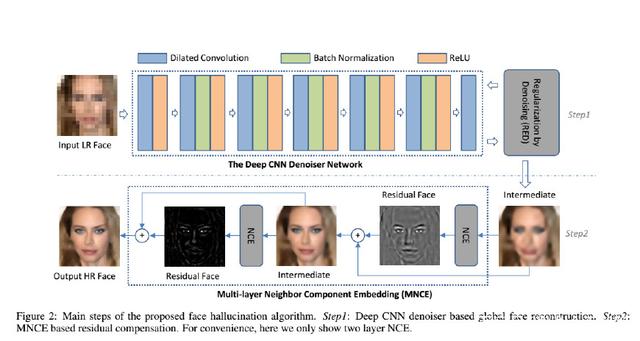
人工智能馬賽克去除深度CNN降噪器和多層相鄰分量嵌入馬賽克去除貢獻:在本文中,我們通過Deep CNN Denoiser和多層鄰居組件嵌入(MNCE)開發了一種新穎的面部馬賽克去除方法。受[Zhang et al。,2017]的工作啟發,我們采用CNN來學習先前的降噪器,然后將其插入基于模型的優化中,共同利用基于模型的優化和判別推理的優點。在這一步中,我們可以預測深度CNN降噪器的中間結果,看起來很平滑。為了增強細節特征,我們通過MNCE進一步提出了一種殘差補償方法。它將NCE擴展到多層框架,以逐步減輕LR和HR空間之間的不一致(特別是當因子非常大時),從而補償在***步中未恢復的缺失細節。圖2顯示了該算法的流水線。
這項工作的貢獻總結如下:
(i)我們提出了一種新穎的兩步式去馬賽克方法,它結合了基于模型的優化和區分性推理學習的優點。所提出的框架使得可以從不同來源(即一般和臉部圖像)學習先驗以同時調整面部馬賽克。 (ii)為了恢復缺失的詳細特征,提出了以多層方式嵌入相鄰分量,并且可以逐步優化和改進幻覺結果。它提供了一種方案來緩解由于一對多映射導致的LR和HR空間之間的不一致性。
人工智能馬賽克去除深度CNN降噪器和多層相鄰分量嵌入馬賽克去除實驗:該算法的性能已經在大規模的名人臉屬性(CelebA)數據集[Liu等人,2015a]上進行了評估,并且我們將該方法與現有技術進行了定性和定量比較數據集。我們采用廣泛使用的峰值信噪比(PSNR),結構相似性(SSIM)[Wang et al。,2004]以及特征相似性(FSIM)[Zhang et al。,2011]作為我們的評估測量。
數據集:我們使用名人臉屬性(CelebA)數據集[Liu et al。,2015b],因為它包含大量多樣,大量和豐富注釋的主題,其中包括10,177個身份和202,599張臉部圖像。我們選擇10%的數據,其中包括20K訓練圖像和260個測試圖像。然后,將這些圖像對齊并裁切為128×128像素作為HR圖像。 LR圖像通過Bicubic 8×下采樣(Matlab函數的默認設置imresize)獲得,因此輸入LR面是16×16像素。
建議的兩步法的有效性。為了證明所提出的兩步法的有效性,我們給出了不同步驟的中間結果。如圖4所示,通過執行基于深度CNN降噪器的全局面部重建(步驟1),它可以很好地保持主要面部輪廓。通過逐層分量嵌入(Step2),我們可以期望逐步增強重建結果的特征細節(請參考第三到第五列)。作為一個學習的普遍以前,以前的深CNN降噪器不能用于建模面部細節。但是,它可以用于緩解LR和HR圖像空間之間的歧義不一致,這將有利于以下相鄰組件嵌入式學習。在第二步中,當它們之間的歧管結構間隙很小時,預測LR和HR空間之間的關系要容易得多。圖5定量顯示了多層嵌入的有效性。它表明,通過迭代嵌入,我們可以期望逐漸接近實際情況。

為了證明基于深度CNN除雪人的全局人臉重建模型的有效性,我們進一步展示了用雙三次插值代替基于深度CNN除雪人的全局人臉重建的幻覺結果,同時保持第二步(即MNCE)為一樣。如圖6所示,深CNN降噪器可以產生更清晰和更整齊的面部輪廓。此外,我們還注意到具有MNEC的Bicubic也可以推斷出合理的結果,這證明了MNCE在學習LR面和殘差圖像之間的關系時的能力。
定性和定量比較:我們將我們的方法與幾種代表性方法進行比較,包括LLE [Chang et al。,2004]和LcR [Jiang et al。,2014b],兩種基于深度學習的代表性方法,SR-CNN [Dong et al。,2016], VDSR [Kim et al。,2016]和兩個最近提出的面部特定圖像超分辨率方法,即LCGE [Song et al。,2017]和UR-DGN [Yu and Porikli,2016]。也作為基線引入雙三次插值。
人工智能馬賽克去除深度CNN降噪器和多層相鄰分量嵌入馬賽克去除結論和未來工作:在本文中,我們提出了一種新的兩步式面部微小圖像的面部幻覺框架。它共同考慮了基于模型的優化和判別推理,并提出了一種基于深度CNN降噪器的全局人臉重構方法。然后,通過多層鄰居組件嵌入,全球中間人力資源面孔逐漸嵌入人力資源管理空間方式。對大規模人臉數據集和真實世界圖像的實證研究證明了所提出的人臉幻覺框架的有效性和魯棒性。輸入面被手動對齊或通過其他算法對齊。在未來的工作中,我們需要考慮人臉對齊和解析來幻化具有未知和任意姿勢的LR人臉圖像。