開源人工智能根據面部表情特征深度學習應用于生成圖像標題摘要:圖像字幕是生成圖像的自然語言描述的過程。然而,大多數當前的圖像字幕模型沒有考慮圖像的情感方面,這與其中表現的活動和人際關系非常相關。為了開發一種可以生成包含這些人類標題的模型,我們使用從包括人臉在內的圖像中提取的面部表情特征,旨在提高模型的描述能力。在這項工作中,我們提出了兩種Face-Cap模型,它以不同的方式嵌入面部表情特征,以生成圖像標題。使用所有標準評估指標,我們的Face-Cap模型在應用于從標準Flickr 30K數據集中提取的圖像標題數據集時,優于用于生成圖像標題的***進基線模型,該數據集包含大約11K個包含面部的圖像。對字幕的分析發現,令人驚訝的是,令人驚訝的是,字幕質量的提高似乎并非來自添加與圖像的情感方面相關的形容詞,而是來自字幕中描述的行為的更多變化。
開源人工智能根據面部表情特征深度學

習應用于生成圖像標題簡介:圖像字幕系統旨在使用計算機視覺和自然語言處理來描述圖像的內容。這在計算機視覺中是一項具有挑戰性的任務,因為我們不僅要捕捉對象,還要捕捉它們之間的關系以及圖像中顯示的活動,以便生成有意義的描述。大多數***進的方法,包括深度神經網絡,都會生成反映圖像事實方面的字幕[3,8,12,16,20,35,37];在這個過程中,通常會忽略能夠提供更豐富和更有吸引力的圖像標題的情感方面。在設計智能系統以產生智能,適應性和有效結果時,需要包括識別和表達情感的情感屬性[22]。設計能夠識別情感并將其應用于描述圖像的圖像字幕系統仍然是一個挑戰。
一些模型已將情緒或其他非事實信息納入圖像標題[10,23,38];他們通常需要收集一個補充數據集,其中的情感詞匯來源于此,來自自然語言處理[25]的工作,其中情緒通常被描述為積極的,中立的或消極的。馬修斯等人。例如,[23]通過眾包構建了一個情感圖像標題數據集,其中要求說話者使用固定詞匯包括正面情緒(例如可愛的貓)或負面情緒(例如陰險的貓);他們的模型在這個和一套標準的事實標題上進行了訓練。甘等人。 [10]提出了一個名為StyleNet的字幕模型,用于添加樣式,包括情感,以及事實標題;他們指定了一組預定義的樣式,例如幽默或浪漫。
這些類型的模型通常包含代表觀察者對圖像的情感的圖像描述(例如,對于圖像的正面看法而言,可愛的貓,對于負面的看法,則是陰險的貓);它們并不旨在捕捉圖像的情感內容,如圖1所示。這種區別已在情感分析文獻中得到認可:例如,[24]的早期工作提出了一種用于預測情緒的圖論 - 理論方法。由文本作者表達,首先刪除文本實際內容中的正面或負面的文本片段(例如“主角試圖保護她的好名字”作為電影情節描述的一部分,哪里好具有積極的情緒)并且只留下反映作者主觀觀點的情感文本(例如“大膽,富有想象力,無法抗拒”)。在圖像的背景下,我們對與內容相關的情感的概念感興趣。
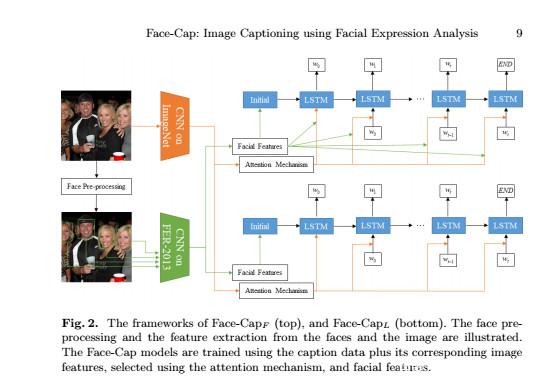
開源人工智能根據面部表情特征深度學習應用于生成圖像標題貢獻:因此,在本文中,我們引入了一個圖像字幕模型,我們稱之為Face-Cap,以結合圖像本身的情感內容:我們自動檢測人臉的情緒,并將衍生的面部表情特征應用于生成圖像標題。我們介紹了Face-Cap的兩種變體,它們以不同的方式使用這些特征來生成字幕。我們的工作貢獻是:
1.Face-Cap模型生成包含面部表情特征和情感內容的字幕,既不使用情感圖像標題配對數據也不使用難以收集的情緒標題數據。據作者所知,這是***項在圖像字幕任務中應用面部表情分析的研究。
2.一組實驗證明,這些Face-Cap模型在所有標準評估指標上都優于基線,這是一種***進的模型。對生成的字幕的分析表明,它們通過更好地描述圖像中執行的操作來改進基線模型。
3.一個圖像標題數據集,包括我們從Flickr 30K數據集[39]中提取的人臉,我們稱之為FlickrFace11K。它是公開的3,用于促進該領域的未來研究。

開源人工智能根據面部表情特征深度學習應用于生成圖像標題數據集:為了訓練我們的面部表情識別模型,我們使用面部表情識別2013(FER-2013)數據集[11]。它包括野外樣本,幸福,悲傷,恐懼,驚訝,憤怒,厭惡和中立。它包含35,887個示例(28,709個用于培訓,3589個用于公開,3589個用于私人測試),通過Google搜索API收集。這些示例采用灰度級,大小為48 x 48像素。在刪除11個完全黑色的示例后,我們將FER-2013的訓練集分為兩個部分:25,109個用于訓練,3589個用于驗證模型。與該領域的其他工作[17,27,40]類似,我們使用FER-2013的私人測試集進行訓練階段后模型的性能評估。為了與相關工作進行比較,我們不會將公共測試集應用于培訓或驗證模型。
為了訓練我們的圖像字幕模型,我們提取了Flickr 30K數據集的一個子集,帶有圖像標題[39],我們稱之為FlickrFace11K。它包含11,696個例子,包括人臉,使用基于CNN的人臉檢測算法進行檢測[18] .4我們觀察到Flickr 30K數據集是我們數據集的一個很好的來源,因為它有很大一部分樣本包括人類與其他圖像標題數據集(如COCO數據集[4])相比,這些面。我們將FlickrFace11K樣本分為8696個進行培訓,2000個進行驗證,1000個進行測試,并將其公之于眾.5為了提取樣本的面部特征,我們使用面部預處理步驟和面部表情識別模型如下。
開源人工智能根據面部表情特征深度學習應用于生成圖像標題Face預處理:由于我們的目標是在FER-2013上訓練面部表情識別模型并將其用作FlickrFace11K樣本的面部表情特征提取器,我們需要使樣本與FER-2013數據一致。為此,使用面部檢測器對FlickrFace11K的面進行預處理。通過基于CNN的面部檢測算法檢測面部并從每個樣本裁剪。然后,我們將每個面轉換為灰度,并將其調整為48 x 48像素,這與FER-2013數據完全相同。
開源人工智能根據面部表情特征深度學習應用于生成圖像標題結論和未來的工作:在本文中,我們提出了兩種圖像字幕模型,Face-Cap,它采用面部特征來描述圖像。為此,應用面部表情識別模型從包括人臉的圖像中提取特征。使用這些特征,我們的模型被告知圖像的情感內容,以自動調節圖像標題的生成。與***進的基線模型相比,我們已經使用標準評估指標顯示了模型的有效性。生成的標題表明Face-Cap模型成功生成圖像標題,并在適當的時間結合了面部特征。對字幕的語言分析表明,描述圖像內容的有效性得到提高,表達的可變性更大。
未來的工作可能涉及設計新的面部表情識別模型,這可以涵蓋更豐富的情感,包括混亂和好奇;并有效地應用其相應的面部特征來生成圖像標題。此外,我們希望探索注入面部情緒的替代架構,如[37]的軟注射方法。