數據分析師還吃香嗎?用數據告訴你
項目簡介
有人說,這個時代,只要站在了風口,豬都能飛起來,尤其互聯網行業,千變萬化,日異月殊,一不小心就錯過了風口,如果沒記錯的話,前幾年火的是App開發,后來是大數據,再接著是人工智能,現在則是區塊鏈,有人甚至用幣圈一日互聯網十年來形容虛擬幣和區塊鏈的火爆,如果單從熱點看,大數據貌似有點out了,那究竟如何呢?今天就對拉勾網上的數據分析職位的相關信息來一個探索性分析。
數據集
之所以采用拉勾網(201712)的數據,是由于在互聯網垂直招聘領域,拉勾網坐***把交椅,無論是職位數量還是職位有效性,都優于其它渠道。
本次采用的數據集主要有以下變量:薪酬下限、薪酬上限、工作地點、經驗要求、學歷要求、工作時間、公司、所處行業、公司融資情況、投資機構、崗位要求等。
目的
通過實際數據來看看數據分析一職的現況如何,薪資是否還有吸引力等,具體來說,探索以下幾個問題:
- 數據分析職位在各城市的需求對比;
- 數據分析師的待遇情況;
- 工作經驗要求;
- 互聯網熱點城市的待遇情況;
- 工作經驗對待遇的影響;
- 學歷對待遇的影響;
- 需要掌握的技能;
- 哪些技能更吃香;
- 不同的經驗要求是否意味著不同的技能要求。
分析工具
在Jupyter Notebook中以Python3及其pandas、matplotlib、seaborn 和 wordcloud包為主進行分析。下面開始正式分析。
數據整理
前期準備工作,由于matplotlib包使用的默認字體不支持中文,所以得修改配置,用文本編輯器打開下面命令得到的路徑中的 matplotlibrc文件,將以 font.family和 font.sans-serif開頭的兩行前的注釋符(#)刪掉,并在“font.sans-serif:”后加上SimHei,更改后結果如 font.sans-serif : SimHei, msyh, DejaVu Sans, ......;再將附帶的字體文件放入matplotlib同級目錄下的\fonts\ttf目錄中。
- import matplotlib
- print(matplotlib.matplotlib_fname())
接著刪除下面命令得到的用戶目錄中.matplotlib下的所有帶cache的文件及文件夾后重啟 Jupyter Notebook。
- print (matplotlib.get_configdir())
準備工作完成,下面正式讀取數據并整理。
- # python3
- # _*_ coding:utf-8 _*_
- # 導入所需的包
- import numpy as np
- import pandas as pd
- import seaborn as sns
- import matplotlib.pyplot as plt
- from wordcloud import WordCloud
- % matplotlib inline
- matplotlib.rcParams['font.sans-serif'] = ['SimHei']
- # 讀取數據
- df = pd.read_excel('la_gou.xlsx')
- # 刪除不需要的變量
- df_clean1 = df.drop(['Index', 'home_page', 'address', 'url', 'date_time'],axis=1)
- # 刪除冗余行
- df_clean = df_clean1.drop_duplicates(['company', 'title', 'description'])
- df_clean=df_clean.reset_index(drop=True)
- df_clean.info()

經過處理后的數據有16個變量,1766個觀測值,其中投資機構(investor)缺失值太多,不過它不是這次分析的重點,影響不大。
探索數據
一、職位在地域方面的區別:
- city_series = df_clean['city'].value_counts()
- y_cor = list(city_series.values)
- x_cor = list(np.arange(len(y_cor)))
- city_series.plot(kind='bar', figsize=(18,10), fontsize=15, rot=40);
- for x,y in zip(x_cor,y_cor):
- plt.text(x, y+1, '%s' % y, ha='center', va= 'bottom',fontsize=14);
- plt.title(u'各城市職位數量', size = 18);
- plt.show();
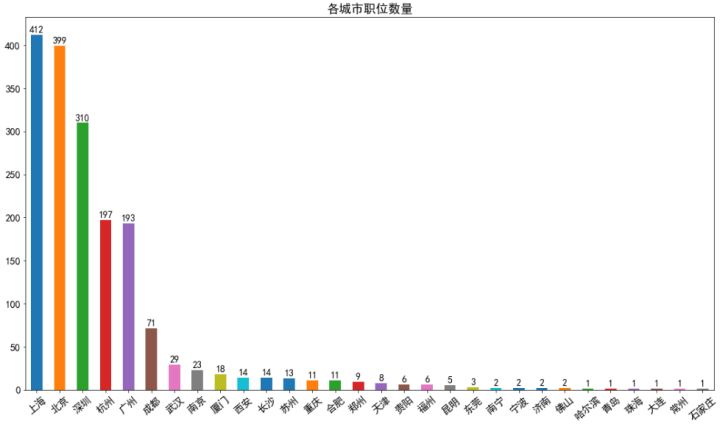
分析結果顯示,與以往媒體報道的北京互聯網發展***不同,上海至少在數據分析職位方面的需求超過了北京,但也只是略超,同時,深圳與上海和北京相比,需求數量差距也不是非常大,其次杭州和廣州的需求比較大,且兩者幾乎無差距,再者就是成都有一定需求,其它城市的需求非常少。總體來說與人們對互聯網強城市的印象相符。
二、薪資概況:
- # 由于招聘給出的薪資是一個區間,故采用其上限和下限間的中值進行分析
- df_clean['salary_median'].hist(figsize=(10,6), bins=30, edgecolor='k', grid=False);
- plt.xlabel(u'薪資(千/月)', size=15);
- plt.ylabel(u'頻數', size=15);
- plt.title(u'薪資分布', size=18);
- plt.xticks(range(0,90,5), size=15);
- plt.yticks(size=15);
- plt.grid(axis='y', alpha=0.2);
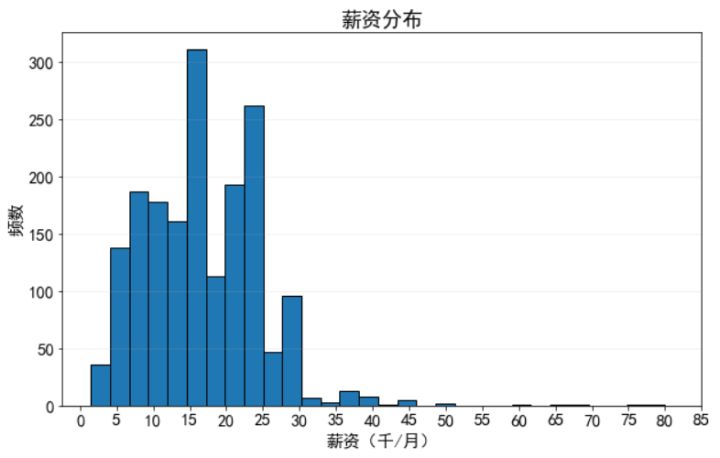
從分布看,薪資差異較大,有大量五千到兩萬五之間的職位,超過三萬的***,***有達到七萬多的,與人們印象不同,并不是每個數據分析師都能"月薪過萬",低于一萬的也有一定比例,但最多的還是一萬五到一萬七的,總的來說,待遇非常吸引人。
三、工作經驗要求:
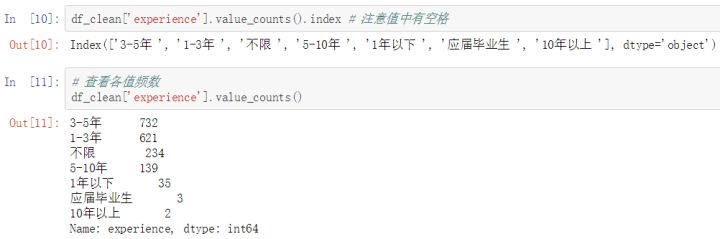
- # 應屆畢業生和10年以上人數很少,將應屆畢業生歸類到一年以下,將10年以上歸類到5-10年,并去掉空格
- for i in df_clean.index:
- df_clean.loc[i,'experience'] = df_clean.loc[i,'experience'].strip()
- if df_clean.loc[i,'experience'] == u'應屆畢業生':
- df_clean.loc[i,'experience'] = u'1年以下'
- if df_clean.loc[i,'experience'] == u'10年以上':
- df_clean.loc[i,'experience'] = u'5-10年'
- experience_freq = df_clean['experience'].value_counts()

- experience_sort = pd.Series([38, 621, 732, 141, 234], index=[u'1年以下',u'1-3年',u'3-5年',u'5-10年',u'不限'])
- experience_sort.plot(kind='bar',figsize=(8,5), fontsize=15, rot=0);
- plt.grid(color='#95a5a6', linewidth=1,axis='y',alpha=0.2)
- plt.xticks(range(5), experience_sort.index, size=15)
- plt.ylabel(u'頻數', size=15);
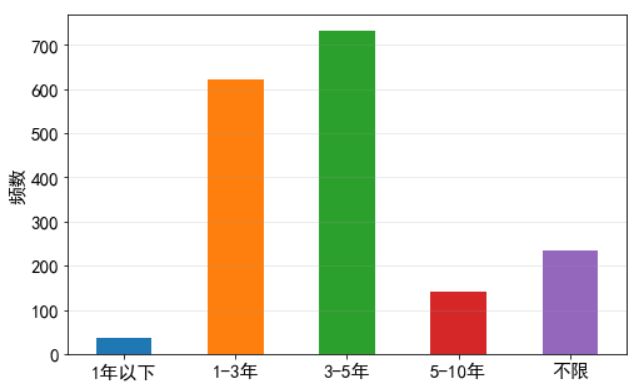
絕大部分崗位都要求有工作經驗,3-5年的最多,其次是1-3年的,5-10年的專家級也有一定需求,還有一些不限經驗的,可能是忘記填寫或實習之類的。
四、互聯網熱點城市薪資概況:
- salary_groupby_city = df_clean.groupby('city')['salary_median']
- large_city = city_series[0:6].index
- salary_of_city = []
- for city in large_city:
- salary_value = salary_groupby_city.get_group(city).values #得到各城市對應的薪水的數組
- salary_of_city.append(salary_value)
- plt.style.use('seaborn-darkgrid')
- matplotlib.rcParams['font.sans-serif'] = ['SimHei']# 對于有些seaborn的style,必須同時運行此命令,否則還是不顯示中文
- plt.figure(figsize=(10,5));
- plt.boxplot(salary_of_city, boxprops = {'color':'blue'},
- flierprops = {'markerfacecolor':'red','color':'black','markersize':4});
- plt.title(u'互聯網熱點城市薪資分布', size=18);
- plt.ylabel(u'薪資(千/月)',size=15);
- plt.xticks(np.arange(6)+1,large_city, size=15);
- plt.yticks(size=15);
- plt.grid(color='#95a5a6', linewidth=1,axis='x',alpha=0.2);
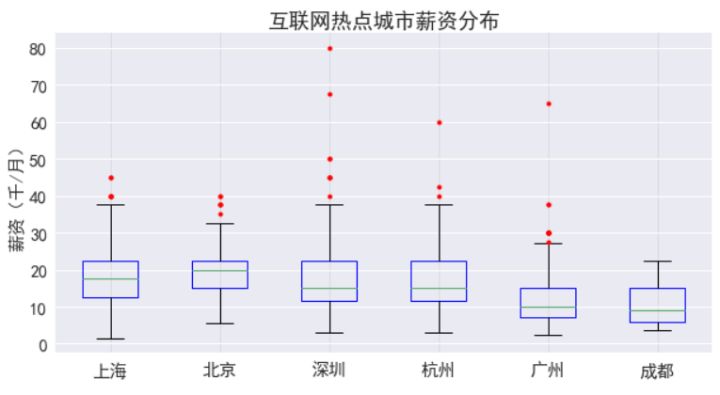
從結果看,北京的月薪中位數***,在2萬元,其次是上海,在1.75萬左右,深杭在1.5萬左右,廣州成都只有1萬,但薪資***的職位在深圳。
五、工作經驗對薪資的影響:
- salary_groupby_experience = df_clean.groupby('experience')['salary_median']
- salary_of_experience = []
- for experience in experience_sort.index:
- salary_value = salary_groupby_experience.get_group(experience).values
- salary_of_experience.append(salary_value)
- plt.figure(figsize=(10,5));
- plt.boxplot(salary_of_experience, boxprops = {'color':'blue'},
- flierprops = {'markerfacecolor':'red','color':'black','markersize':4});
- plt.title(u'不同工作經驗的薪資待遇', size=18);
- plt.ylabel(u'薪資(千/月)',size=15);
- plt.xticks(np.arange(5)+1,experience_sort.index, size=15);
- plt.yticks(size=15);
- plt.style.use('seaborn-darkgrid');
- matplotlib.rcParams['font.sans-serif'] = ['SimHei'];
- plt.grid(color='#95a5a6', linewidth=1,axis='x',alpha=0.2);
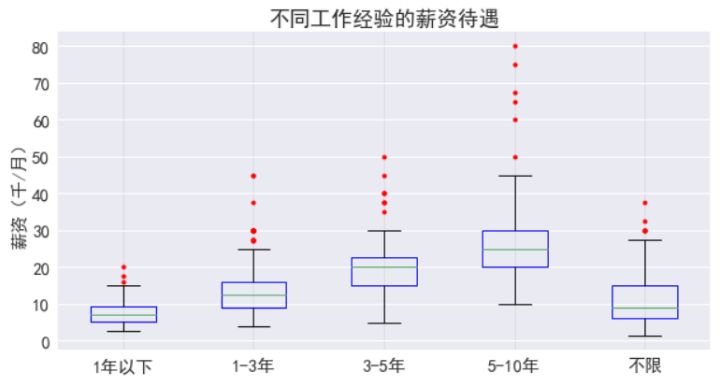
可見經驗越久,待遇越高,有5年經驗的薪資中位數***也有2萬,遠比傳統行業高。
六、學歷對薪資的影響:
- edu_sort = pd.Series([52,170,1465,78,1], index=[u'不限',u'大專',u'本科',u'碩士',u'博士'])
- salary_groupby_edu = df_clean.groupby('education')['salary_median']
- salary_of_edu = []
- for education in edu_sort.index:
- salary_value = salary_groupby_edu.get_group(education).values
- salary_of_edu.append(salary_value)
- plt.figure(figsize=(10,6));
- plt.boxplot(salary_of_edu, boxprops = {'color':'blue'});
- plt.title(u'不同學歷的薪資待遇', size=18);
- plt.ylabel(u'薪資(千/月)',size=15);
- plt.xticks(np.arange(5)+1,edu_sort.index, size=15);
- plt.yticks(size=15);
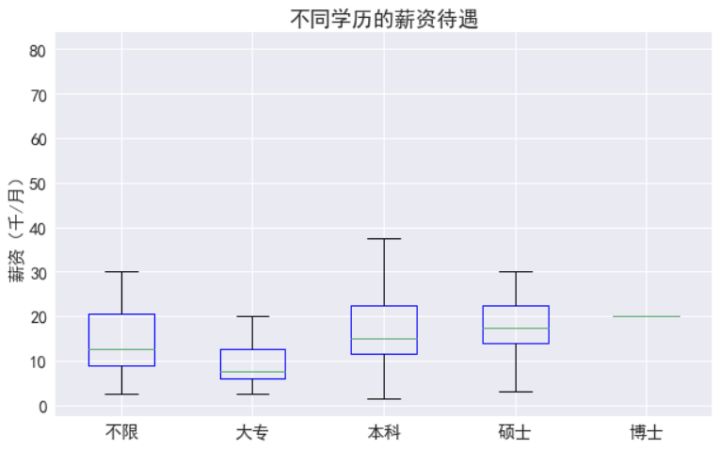
其中不限學歷的可能由于招聘者忘記選擇,也可能由于其是新興領域,更看重實際能力而非學歷,對于有明確要求的,大專明顯低于本科和碩士,本科和碩士的差距倒不是特別大,只是碩士的起薪要高。
七、工作技能要求:
- # 添加技能列
- import re
- def get_skill(text):
- skill_list = re.findall('([a-zA-Z][0-9a-zA-Z]+|C\#|\.Net|R\d?|A\/B|算法)', text)
- for skill in skill_list:
- if skill.upper() == 'EXCEL' or skill.upper() == 'PPT':
- skill_list[skill_list.index(skill)] = 'office'
- return ','.join(skill_list).upper()
- df_clean['skill'] = df_clean['description'].apply(get_skill)
- # 生成技能字典
- import nltk
- skill_list = []
- for i in df_clean.index:
- if len(df_clean.loc[i, 'skill']) > 0:
- skill_list.extend(df_clean.loc[i, 'skill'].split(','))
- skill_freq = dict(nltk.FreqDist(skill_list))
- # 刪除主要的提取錯的鍵值
- del skill_freq['AND']
- del skill_freq['TO']
- del skill_freq['IN']
- del skill_freq['DATA']
- del skill_freq['THE']
- del skill_freq['OF']
- del skill_freq['KPI']
- del skill_freq['APP']
- del skill_freq['WITH']
- del skill_freq['SERVER']
- wc = WordCloud(width=800, height=400, background_color='white').generate_from_frequencies(skill_freq)
- plt.figure(figsize=(8,4));
- plt.imshow(wc);
- plt.axis('off');
- plt.show();

可見,SQL,Office(主要是Excel和PPT)是需求***的,是絕大多數要求必須掌握的;其次,Python,算法和R的需求也很大,另外SAS,SPSS,Hadoop,Hive的需求也不小。
八、查看主流技能的薪酬平均中值:
- # 選取需求最多的20個技能
- skill_sort = sorted(skill_freq.items(), key=lambda item:item[1], reverse=True) #對技能頻數字典按值從大到小排序
- hot_skill_list = skill_sort[0:20]
- hot_skill_salary_mean = {} # 存放技能中值的均值的字典
- for i in hot_skill_list: # i 為技能和其頻次的列表的元素
- for j in df_clean.index:
- if i[0] in df_clean.loc[j, 'skill']: # 如果技能在數據框的技能列中
- if i[0] in hot_skill_salary_mean: # 如果技能在技能中值的均值的字典中
- # 技能鍵的值為原值加上新值
- hot_skill_salary_mean[i[0]] = hot_skill_salary_mean[i[0]] + df_clean.loc[j, 'salary_median']
- else:
- hot_skill_salary_mean[i[0]] = df_clean.loc[j, 'salary_median']
- hot_skill_salary_mean[i[0]] = hot_skill_salary_mean[i[0]] / i[1] # 技能中值的均值為之前計算的和除以技能頻數
- hot_skill_salary_mean = sorted(hot_skill_salary_mean.items(), key=lambda item:item[1]) #排序
- hot_skill_salary_mean #排序后返回由含字典元素的元組構成的列表
- hot_skill_freq = [] #把前20個技能的需求頻數提取出來
- for i in hot_skill_salary_mean:
- hot_skill_freq.append(skill_freq[i[0]])
- hot_skill_freq # 排序會按其薪酬均值從小到大
- hot_skill_salary_key = [] # 熱門技能名稱列表
- hot_skill_salary_values = [] #熱門技能的中值的均值列表
- for i,j in dict(hot_skill_salary_mean).items():
- hot_skill_salary_key.append(i)
- hot_skill_salary_values.append(j)
- plt.figure(figsize=(10,6));
- plt.scatter(x = np.arange(len(hot_skill_salary_values)), y=hot_skill_salary_values, s=hot_skill_freq);
- plt.xticks(np.arange(len(hot_skill_salary_values)), hot_skill_salary_key, size=15, rotation=40);
- plt.yticks(size=15);
- plt.title('不同技能可以拿到的薪資中位數的均值', size=18);
- plt.ylabel('千/月', size=15);
- plt.ylim((5,26));
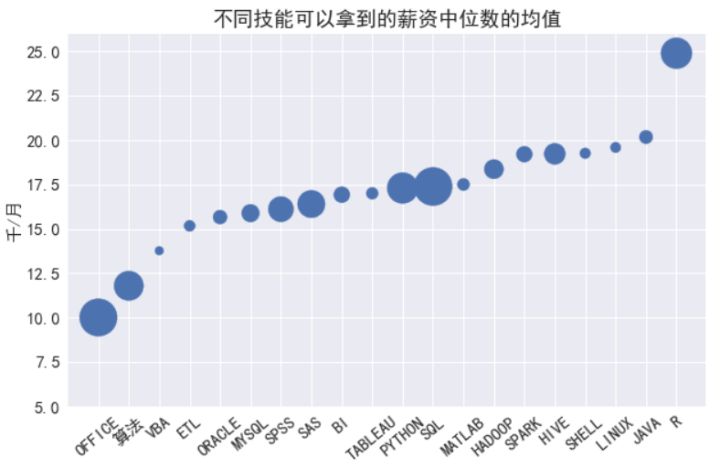
泡泡大小代表了需求量,從結果看,會R的薪資***,但這只是高薪的必要條件,而非充分條件,另外算法太低,可能是由于大多數崗位需求里都提到了算法,進而拉低了其均值,如果進一步分析,應該能得出比較貼合實際的數據,或者也可直接將此項剔除,分析其它崗位如深度學習機器學習的薪資來得到算法的薪資均值。Java是走向高級開發必不可少的路,Hadoop,Spark,Hive仍然是數據分析類職位的高薪必備技能。
九、看看主要工作經驗對主流技能的要求是否有差別:
- # 生成字典,來存放兩種經驗對應的主流技能需求數
- skill_by_exp13 = {}
- skill_by_exp35 = {}
- df_skill_13 = df_clean[df_clean['experience']=='1-3年'][['experience', 'skill']]
- df_skill_35 = df_clean[df_clean['experience']=='3-5年'][['experience', 'skill']]
- for i in hot_skill_salary_key:
- for j in df_skill_13.index:
- if i in df_skill_13.loc[j, 'skill']:
- if i in skill_by_exp13:
- skill_by_exp13[i] = skill_by_exp13[i] + 1
- else:
- skill_by_exp13[i] = 1
- for i in hot_skill_salary_key:
- for j in df_skill_35.index:
- if i in df_skill_35.loc[j, 'skill']:
- if i in skill_by_exp35:
- skill_by_exp35[i] = skill_by_exp35[i] + 1
- else:
- skill_by_exp35[i] = 1
- ind = np.arange(len(skill_by_exp13))
- width = 0.35
- sns.set(context='notebook', style='darkgrid', palette='muted', font='simhei')
- plt.figure(figsize=(12,6));
- plt.grid(color='white', linewidth=1,alpha=0.3);
- plt.bar(ind, pd.Series(skill_by_exp13).values, width, label='1-3年');
- plt.bar(ind + width, pd.Series(skill_by_exp35).values, width, label='3-5年');
- plt.title('不同工作經驗對主流技能的需求對比', size=18);
- plt.xticks(ind+width/2, pd.Series(skill_by_exp13).index, size=15, rotation=40);
- plt.yticks(size=15)
- plt.legend();
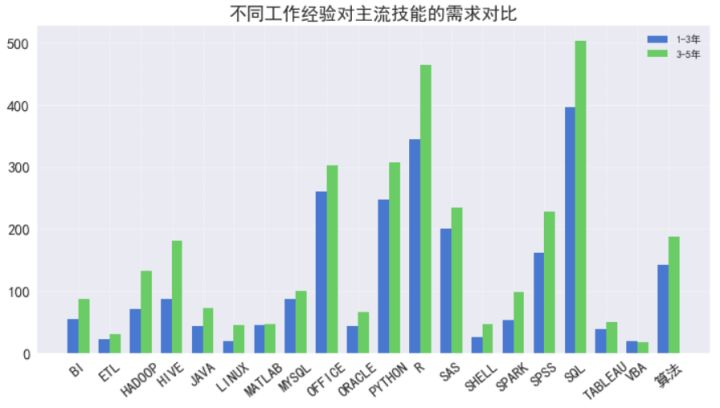
幾乎所有主流技能,3-5年工作經驗的需求量都比1-3年的多,但這很大可能是因為3-5年的招聘數本身就比1-3年的多100個左右,但我注意到,對Matlab、MySQL、VBA及Tableau的需求兩者相差無幾,VBA方面3-5年的甚至低于1-3年的,這說明3-5年經驗要求的對這四種技能的需求不如1-3年的多。
結論匯總
- 對數據分析一職的需求主要集中在北上廣深杭,其中北京和上海***,深圳需求緊隨其后,廣州和杭州相比上海和北京需求減半,但比起其它城市依然不少。
- 大多數職位提供的薪資中值在5千到2萬5之間,很少有給出3萬的,但也有極少數崗位,給出了五六萬的高薪。
- 大多數崗位要求有工作經驗,要求有3-5年經驗的最多,其次是1-3年的,不要求或只要求不到一年的很少。
- 互聯網發展熱門城市中,北京給出的薪資的中值***,達到了2萬元,上海緊隨其后,比北京低一兩千,杭州和深圳基本持平,基本在1萬5左右,這有點出人意料,考慮到置業成本,去杭州貌似比深圳更好,廣州和成都的中值在1萬左右,可見,至少在數據方面,杭州的發展已經超過廣州這個一線城市了。
- 工作經驗與薪資密切相關,1-3年經驗的薪資中值大部分超過了1萬,3-5年的都在1萬5以上,而5年以上的,薪資中值都在2萬以上。
- 學歷方面,碩士對本科的優勢不是很明顯,但下限是肯定高于本科的,大專相比本科劣勢就比較明顯了,薪資低不少,而博士相對碩士也有很大優勢,但需求少。
- 技能方面,office(主要是excel其次少部分PPT)和SQL需求最多,Python、R、算法緊隨其后,Hadoop、SPSS、Hive、SAS、和Spark的需求也不少。
- 對于拿到高薪的必要條件,R優勢***,其次是Java,Linux等,當然這些條件并非單一滿足,一般要同時會其它高級技能才能拿到高薪,顯然這已經不是基礎的數據分析需要的技能了,可能側重于數據挖掘和建模等。
- 要求3-5年經驗的和要求1-3年經驗的在技能需求上沒有太大差別,對于這條結論不是很有把握,不是太符合邏輯,等日后再詳細分析。
思考·總結
通過這次分析,深切的感受到了思路的重要性,如果你對探索數據沒有好奇心,沒有一點自己的想法,那真可謂無處下手,不知道該分析什么,正所謂思路為“道”,工具為“術”,分析之前,得先給自己提出幾個想探索的問題,或想驗證的假設,當然這點不是非得一步到位,也可以循序漸進,隨著分析的不斷進行再開展新的探索。
“術”方面的工具技能也很重要,有時候你不知道那個函數的用法,不知道那個參數的設置,可能找很久都找不到,比如對柱狀圖添加文字說明,起初我按照搜索到的方法添加,可就是不出效果,搜了好幾種方法都不行,無奈之下我只得把別人的代碼截圖一行一行敲下來運行驗證,***發現是因為沒放在一個cell里這個低級原因,當然,這個過程中我又學到了別的知識。術方面還有一點需要說的是,早期seaborn包會對matplotlib的圖自動美化,但新版改了,不會自動美化,得自己設置,這方面花了大量時間搜索,主要是不知道對應的術語叫什么,只能按文字描述搜索,***發現,圖像的灰底不是顏色,是style,可以用兩種方式設置,但兩種都不好用,因為只要對一個圖設置后,那做其它圖時都會默認采用你設置的這個style,而我希望只針對單個圖起作用。
項目之外的,我感到主動學習非常重要,對于自己不會的,不要畏懼,也不要偷懶,要相信自己碰到的問題別人也絕對碰到過,搜一搜,看看別人是怎么解決的,比如對于技能的提取及詞云的繪制,起初用了結巴分詞提取,但提取有疏漏,不過沒有大的問題,但繪制詞云時,出來的都是中文詞,基本沒有技能名,我只好去找別的方法,看能不能過濾掉結巴提取后的中文詞,***發現何不采用正則重新提取呢,于是進行了重新提取,但繪制詞云時又碰到重復顯示的問題,同樣的詞以不同大小和顏色顯示好幾次,但詞并沒有問題。***用自定義詞典解決了。
另外就是英語非常重要,有些函數的參數太多,以至于官網文檔都沒有詳細說,它可能是作為一些共用的參數放在了其它函數中介紹。***,對于崗位描述的探索還能進一步采用語義分析,得出更明確的要求,因為有些要求是必須滿足的,有些是加分項,但水平所限,還不能語義分析,還有就是投資公司,如果數據較全也能探索下金融方面這些機構的投資偏好及相互間的裙帶關系,畢竟,中國的互聯網,誰都繞不開阿里騰訊及其背后的資本。